47/129
2016
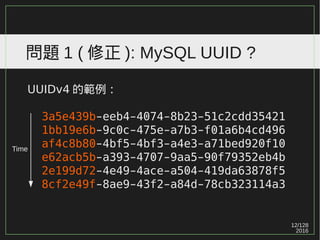
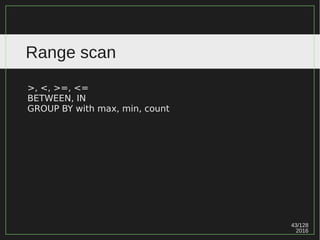
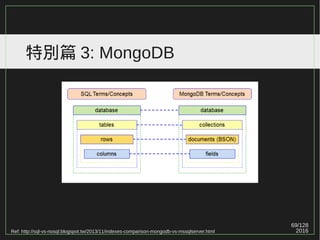
Range scan: IOTw/ 循序式 & 亂序式
SELECT * FROM x WHERE y BETWEEN 1 AND 7;
13
4 7
1 2 3 4 5 6 7
1 user1 pass1
2 user2 pass2
3 user3 pass3
4 user4 pass4
5 user5 pass5
6 user6 pass6
7 user7 pass7
p1
p3
p2
Block N+3 ...
I/O
p1 p2 p3 p4
I/O
Block N+M
48.
2016
48/129
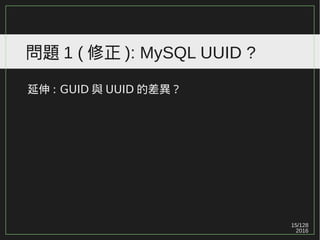
問題 3
Q: 哪些資料庫支援Heap table ?哪些支援 IOT ?
MySQL
Oracle
Microsoft SQL Server
PostgreSQL
MongoDB
CouchDB
49.
49/129
2016
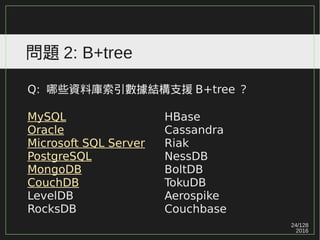
問題 3
Heap tableIOT
MySQL/MyISAM O X
MySQL/InnoDB X O
Oracle O O
Microsoft SQL Server O O
PostgreSQL O X
MongoDB/MMAPv1 O X
MongoDB/WiredTiger O X
CouchDB X O
64/129
2016
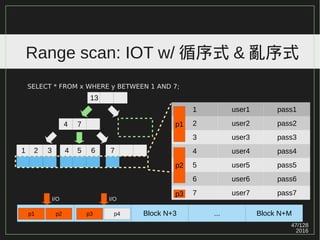
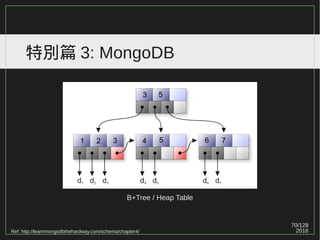
特別篇 2: PostgreSQL(Merge IO)
MySQL Insert Buffering( 現在改名 Change Buffer) :
1. Reducing the number of disk i/o operations by merging i/o
requests to the same block.
2. Some random i/o operations can be sequential.
Ref: http://www.percona.com/files/presentations/percona-live/london-2011/PLUK2011-linux-and-hw-optimizations-for-mysql.pdf (p17)




















































![60/129
2016
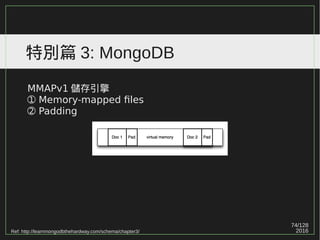
特別篇 2: PostgreSQL (Index Bloat)
PostgreSQL(non HOT updates) 天性無法避免 index bloat 。
Ref: PostgreSQL 9.0 High Performance [PACKT] (2010) (p171)](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-60-320.jpg)































![98/129
2016
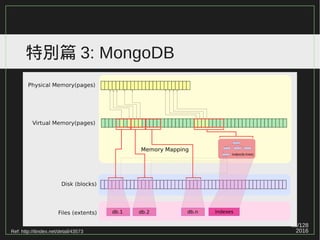
特別篇 5: 黑暗執行緒案例
假設已有五筆資料
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-98-320.jpg)
![99/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = “5b..” 】
IO 次數: 0
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-99-320.jpg)
![100/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = “5b..” 】
IO 次數: 1
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-100-320.jpg)
![101/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = “5b..” 】
IO 次數: 2
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-101-320.jpg)
![102/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = “5b..” 】
IO 次數: 3
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-102-320.jpg)
![103/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = “5b..” 】
IO 次數: 4 ( 完成 )
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-103-320.jpg)
![104/129
2016
特別篇 5: 黑暗執行緒案例
新增【 SeqNo: 6, FlowID: 4c.. 】
IO 次數: 0
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
6 4c.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-104-320.jpg)
![105/129
2016
特別篇 5: 黑暗執行緒案例
新增【 SeqNo: 6, FlowID: 4c.. 】
IO 次數: 1
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
6 4c.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-105-320.jpg)
![106/129
2016
特別篇 5: 黑暗執行緒案例
新增【 SeqNo: 6, FlowID: 4c.. 】
IO 次數: 2
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
6 4c.. ...
1 3 5 2 4
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-106-320.jpg)
![107/129
2016
特別篇 5: 黑暗執行緒案例
新增【 SeqNo: 6, FlowID: 4c.. 】
IO 次數: 3+3
Page Split 次數: 1
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
6 4c.. ...
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )
07.. 3b.. 4c.. 5b..
1 3 6 5 42
3b.. 5b.. cb..
9e.. cb..](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-107-320.jpg)
![108/129
2016
特別篇 5: 黑暗執行緒案例
新增【 SeqNo: 6, FlowID: 4c.. 】
IO 次數: 3+3+1
Page Split 次數: 1
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
6 4c.. ...
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )
07.. 3b.. 4c.. 5b..
1 3 6 5 42
3b.. 5b.. cb..
9e.. cb..](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-108-320.jpg)
![109/129
2016
特別篇 5: 黑暗執行緒案例
新增【 SeqNo: 6, FlowID: 4c.. 】
IO 次數: 3+3+2
Page Split 次數: 1
3 5
1 2 3 4 5
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
6 4c.. ...
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )
07.. 3b.. 4c.. 5b..
1 3 6 5 42
3b.. 5b.. cb..
9e.. cb..](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-109-320.jpg)
![110/129
2016
特別篇 5: 黑暗執行緒案例
新增【 SeqNo: 6, FlowID: 4c.. 】
IO 次數: 3+3+3
Page Split 次數: 1
3 5
1 2 3 4 5 6
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
6 4c.. ...
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )
07.. 3b.. 4c.. 5b..
1 3 6 5 42
3b.. 5b.. cb..
9e.. cb..](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-110-320.jpg)
![111/129
2016
特別篇 5: 黑暗執行緒案例
新增【 SeqNo: 6, FlowID: 4c.. 】
IO 次數: 3+3+4=10 ( 完成 )
Page Split 次數: 1
07.. 3b.. 4c.. 5b..
3 6
1 2 3 4 5 6
[SeqNo] [FlowId] ...
1 07.. ...
2 9e.. ...
3 3b.. ...
4 cb.. ...
5 5b.. ...
6 4c.. ...
1 3 6 5 42
Nonclustered Index ( 亂序式 )
Clustered Index ( 循序式 )
3b.. 5b.. cb..
9e.. cb..](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-111-320.jpg)
![112/129
2016
特別篇 5: 黑暗執行緒案例
如果用一般亂序式 UUID
[FlowId] ... ...
07.. ... ...
9e.. ... ...
3b.. ... ...
cb.. ... ...
5b.. ... ...
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
Clustered Index ( 亂序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-112-320.jpg)
![113/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = “5b..” 】
IO 次數: 0
[FlowId] ... ...
07.. ... ...
9e.. ... ...
3b.. ... ...
cb.. ... ...
5b.. ... ...
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
Clustered Index ( 亂序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-113-320.jpg)
![114/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = “5b..” 】
IO 次數: 1
[FlowId] ... ...
07.. ... ...
9e.. ... ...
3b.. ... ...
cb.. ... ...
5b.. ... ...
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
Clustered Index ( 亂序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-114-320.jpg)
![115/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = “5b..” 】
IO 次數: 2 ( 完成 )
[FlowId] ... ...
07.. ... ...
9e.. ... ...
3b.. ... ...
cb.. ... ...
5b.. ... ...
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
Clustered Index ( 亂序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-115-320.jpg)
![116/129
2016
特別篇 5: 黑暗執行緒案例
新增【 FlowID: 4c.. 】
IO 次數: 0
[FlowId] ... ...
07.. ... ...
9e.. ... ...
3b.. ... ...
cb.. ... ...
5b.. ... ...
4c.. ... ...
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
Clustered Index ( 亂序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-116-320.jpg)
![117/129
2016
特別篇 5: 黑暗執行緒案例
新增【 FlowID: 4c.. 】
IO 次數: 1
[FlowId] ... ...
07.. ... ...
9e.. ... ...
3b.. ... ...
cb.. ... ...
5b.. ... ...
4c.. ... ...
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
Clustered Index ( 亂序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-117-320.jpg)
![118/129
2016
特別篇 5: 黑暗執行緒案例
新增【 FlowID: 4c.. 】
IO 次數: 2
[FlowId] ... ...
07.. ... ...
9e.. ... ...
3b.. ... ...
cb.. ... ...
5b.. ... ...
4c.. ... ...
5b.. cb..
07.. 3b.. 5b.. 9e.. cb..
Clustered Index ( 亂序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-118-320.jpg)
![119/129
2016
特別篇 5: 黑暗執行緒案例
新增【 FlowID: 4c.. 】
IO 次數: 3+3 ( 完成 )
Page Split 次數: 1
[FlowId] ... ...
07.. ... ...
9e.. ... ...
3b.. ... ...
cb.. ... ...
5b.. ... ...
4c.. ... ...
3b.. 5b.. cb..
07.. 3b.. 4c.. 5b..
Clustered Index ( 亂序式 )
9e.. cb..](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-119-320.jpg)
![120/129
2016
特別篇 5: 黑暗執行緒案例
如果用一般循序式 UUID
[FlowId] ... ...
1 ... ...
2 ... ...
3 ... ...
4 ... ...
5 ... ...
3 5
1 2 3 4 5
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-120-320.jpg)
![121/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = 5 】
IO 次數: 0
[FlowId] ... ...
1 ... ...
2 ... ...
3 ... ...
4 ... ...
5 ... ...
3 5
1 2 3 4 5
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-121-320.jpg)
![122/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = 5 】
IO 次數: 1
[FlowId] ... ...
1 ... ...
2 ... ...
3 ... ...
4 ... ...
5 ... ...
3 5
1 2 3 4 5
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-122-320.jpg)
![123/129
2016
特別篇 5: 黑暗執行緒案例
尋找【 WHERE FlowId = 5 】
IO 次數: 2 ( 完成 )
[FlowId] ... ...
1 ... ...
2 ... ...
3 ... ...
4 ... ...
5 ... ...
3 5
1 2 3 4 5
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-123-320.jpg)
![124/129
2016
特別篇 5: 黑暗執行緒案例
新增【 FlowID: 6 】
IO 次數: 0
[FlowId] ... ...
1 ... ...
2 ... ...
3 ... ...
4 ... ...
5 ... ...
6 ... ...
3 5
1 2 3 4 5
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-124-320.jpg)
![125/129
2016
特別篇 5: 黑暗執行緒案例
新增【 FlowID: 6 】
IO 次數: 1
[FlowId] ... ...
1 ... ...
2 ... ...
3 ... ...
4 ... ...
5 ... ...
6 ... ...
3 5
1 2 3 4 5
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-125-320.jpg)
![126/129
2016
特別篇 5: 黑暗執行緒案例
新增【 FlowID: 6 】
IO 次數: 2
[FlowId] ... ...
1 ... ...
2 ... ...
3 ... ...
4 ... ...
5 ... ...
6 ... ...
3 5
1 2 3 4 5
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-126-320.jpg)
![127/129
2016
特別篇 5: 黑暗執行緒案例
新增【 FlowID: 6 】
IO 次數: 3+1 ( 完成 )
[FlowId] ... ...
1 ... ...
2 ... ...
3 ... ...
4 ... ...
5 ... ...
6 ... ...
3 6
1 2 3 4 5 6
Clustered Index ( 循序式 )](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-127-320.jpg)

![129/129
2016
特別篇 6: MultiColumn B-Tree Index
[Col#1] [Col#2]
1 A
3 B
3 C
4 D
3 C
CREATE INDEX ON table (Col#1, Col#2);
1 A 3 B 3 C 4 D](https://image.slidesharecdn.com/2016-04-12btree-160423002253/85/b-tree-part-1-129-320.jpg)


























![[CB19] アンチウイルスをオラクルとしたWindows Defenderに対する新しい攻撃手法 by 市川遼](https://cdn.slidesharecdn.com/ss_thumbnails/codeblue2019-ja-191211062732-thumbnail.jpg?width=640&height=640&fit=bounds)







































![恰如其分的 MySQL 設計技巧 [Modern Web 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/2016-08-24modernweb-mysql-161019062706-thumbnail.jpg?width=640&height=640&fit=bounds)

