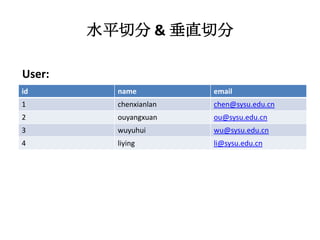
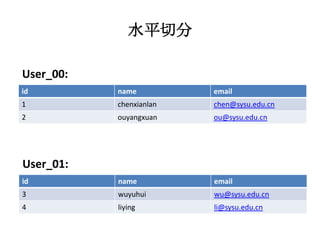
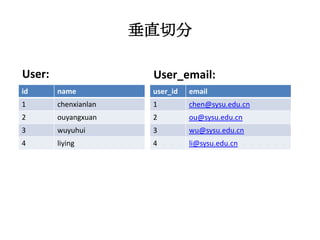
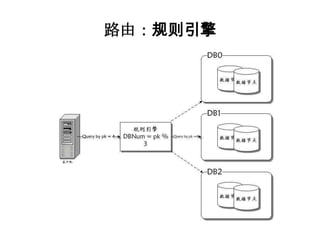
本文探讨了大型网站架构设计的关键因素,从前端和后端的基本概念,到面对高访问量时如何优化服务器架构并采用分布式存储解决方案。重点讨论了数据切分策略(水平和垂直切分)、路由机制及其对查询效率的影响,同时介绍了搜索引擎核心原理与架构变化。文末提到未来的发展方向,包括系统解耦和优化数据库使用的建议。




















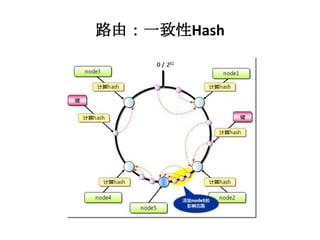

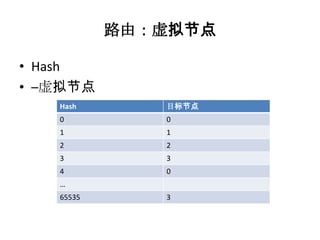









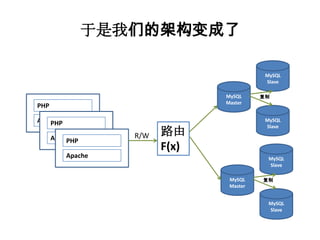




![搜索的流程
• 输入Query
– what is it
– 分词得到token
– what, is, it
– 查询得到各token的倒排链
– sets=[[0,1], [0,1,2], [0,1,2]]
– 对各倒排链集合求交集
– setsAND(sets) = [0,1]
– 得到结果
– result=[0,1]](https://image.slidesharecdn.com/random-120519092437-phpapp02/85/1-100000000-46-320.jpg)