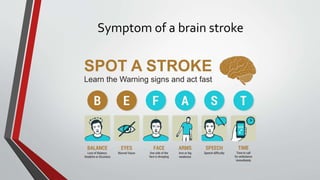
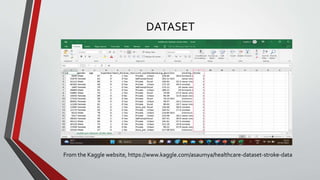
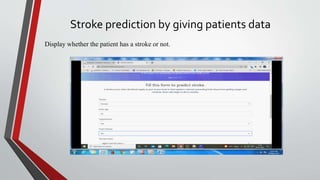
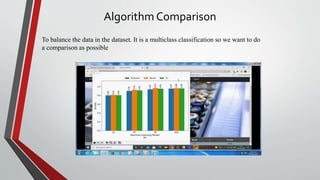
This document presents a project that aims to predict the chances of stroke occurrence using machine learning techniques. Five different algorithms are used and compared to achieve better accuracy. The objective is to create a user-friendly application to predict stroke risk by entering patient data. A dataset from Kaggle is used, and data preprocessing is applied to balance the dataset. Python is used for the frontend and MySQL for the backend. Algorithms are compared to select the best for stroke prediction. The project concludes that an accuracy of 93.68% can be achieved using the XGBoost model.











![REFERENCE
• [1] Tasfia Ismail Shoily, Tajul Islam, Sumaiya Jannat, and Sharmin Akter Tanna
"Detection of stroke using machine learning algorithms", 10th International Conference on
Computing, Communication and Networking Technologies (ICCCNT), IEEE, July 2022.
• [2] JoonNyung Heo , Jihoon G. Yoon , Hyungjong Park , Young Dae Kim , Hyo Suk Nam
and Ji Hoe Heo. "Stroke prediction in acute stroke", Stroke. 2019;50:1263-1265, AHA
Journal, 20 Mar 2021.
• [3] Jaehak Yu, Damee Kim, Hongkyu Park, Seung-Chul Chon,Kang Hee Cho, Sun-Jin
Kim, Sungkyu Yu, Sejin Park and Seunghee “Semantic analysis of NIH stroke”, 2019
International Conference on Platform Technology and Service (PlatCon), IEEE, 30 Jan
2019.](https://image.slidesharecdn.com/brainstrokereview-230427093526-fb6ddf92/85/BRAIN-STROKE-REVIEW-pptx-16-320.jpg)







![Management of acute ischemic stroke including tia [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/managementofacuteischemicstrokeincludingtiaautosaved-180808183403-thumbnail.jpg?width=640&height=640&fit=bounds)




























































