Downloaded 41 times







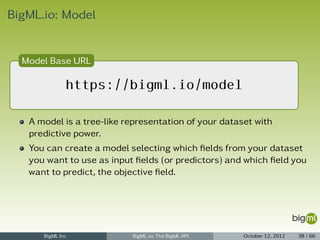
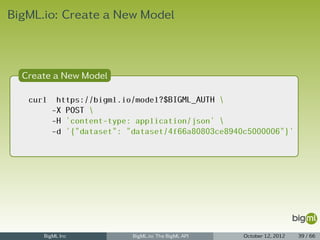
![BigML.io: New Source
New Source
1 {
2 "category": 0,
3 "code": 201,
4 "content_type": "application/octet-stream",
5 "created": "2012-05-21T18:41:47.546669",
6 "credits": 0.0,
7 "description": "",
8 "file_name": "iris.csv",
9 "md5": "d1175c032e1042bec7f974c91e4a65ae",
10 "name": "iris.csv",
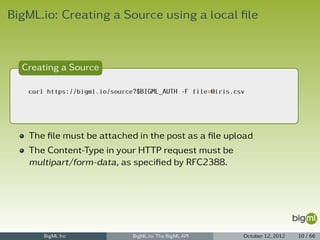
11 "number_of_datasets": 0,
12 "number_of_models": 0,
13 "number_of_predictions": 0,
14 "private": true,
15 "resource": "source/4f52824203ce893c0a000053",
16 "size": 4608,
17 "source_parser": {},
18 "status": {
19 "code": 2,
20 "elapsed": 0,
21 "message": "The source creation has been started"
22 },
23 "tags": [],
24 "type": 0,
25 "updated": "2012-05-21T18:41:47.546693"
26 }
BigML Inc BigML.io: The BigML API October 12, 2012 13 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-13-320.jpg)
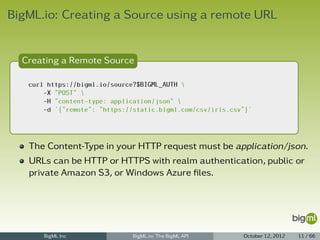
![BigML.io: Source Parser
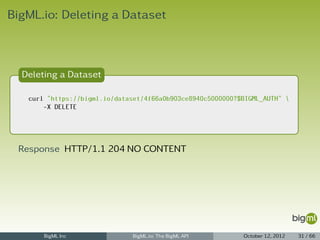
Source Parser
1 {
2 "header": true,
3 "locale": "en-US",
4 "missing_tokens": ["?"],
5 "quote": """,
6 "separator": ",",
7 "trim": true
8 }
BigML Inc BigML.io: The BigML API October 12, 2012 16 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-16-320.jpg)


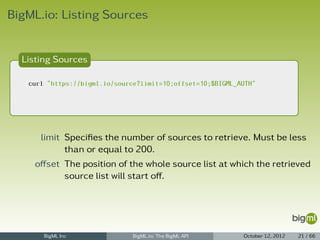
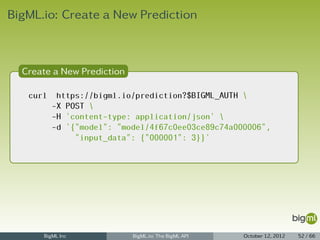
![BigML.io: Listing Sources (cont.)
Source Listing
1 {
2 "meta": {
3 "limit": 10,
4 "next": "/source?limit=10&offset=20&username=francisco&api_key=aa4420adaed03ea68c850",
5 "offset": 10,
6 "previous": null,
7 "total_count": 540
8 },
9 "objects": [
10 {
11 "code": 200,
12 "content_type": "text/csv",
13 ...
14 },
15 ...
16 {
17 "code": 200,
18 "content_type": "text/csv",
19 ...
20 }
21 ]
22 }
BigML Inc BigML.io: The BigML API October 12, 2012 22 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-22-320.jpg)

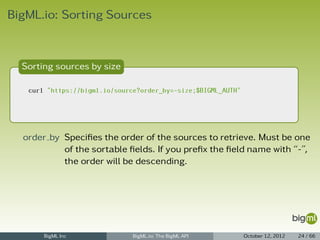

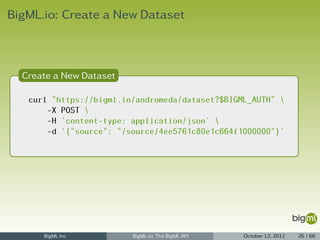
![New Datatset
1 { "category": 0,
2 "code": 201,
3 "columns": 5,
4 "created": "2012-05-25T06:02:40.889538",
5 "credits": 0.0087890625,
6 "description": "",
7 "fields": {
8 "000000": {
9 "column_number": 0,
10 "name": "sepal length",
11 "optype": "numeric"
12 },
13 ...
14 },
15 "locale": "en_US",
16 "name": "iris' dataset",
17 "number_of_models": 0,
18 "number_of_predictions": 0,
19 "private": true,
20 "resource": "dataset/4f66a0b903ce8940c5000000",
21 "rows": 0,
22 "size": 4608,
23 "source": "source/4f665b8103ce8920bb000006",
24 "source_status": true,
25 "status": {
26 "code": 1,
27 "message": "The dataset is being processed and will be created soon"
28 },
29 "tags": [],
30 "updated": "2012-05-25T06:02:40.889570" }
BigML Inc BigML.io: The BigML API October 12, 2012 27 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-27-320.jpg)
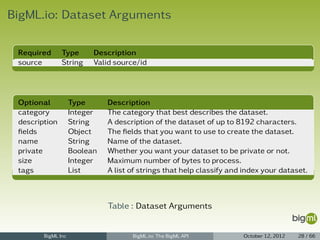
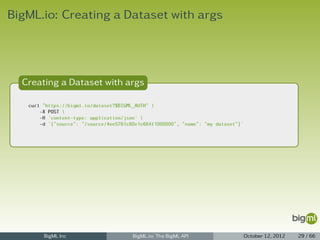
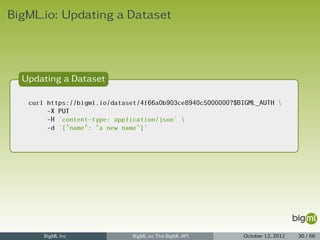

![BigML.io: Dataset Listing
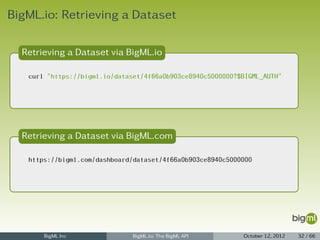
Dataset Listing
1 {
2 "meta": {
3 "limit": 10,
4 "next": "/dataset?limit=10&offset=20&username=ciskoo&api_key=70aaae8d77699bc5d43788a5",
5 "offset": 10,
6 "previous": null,
7 "total_count": 2114
8 },
9 "objects": [
10 {
11 "code": 200,
12 "columns": 120,
13 ...
14 },
15 ...
16 {
17 "code": 200,
18 "columns": 5,
19 ...
20 }
21 ]
22 }
BigML Inc BigML.io: The BigML API October 12, 2012 35 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-35-320.jpg)

![New Model
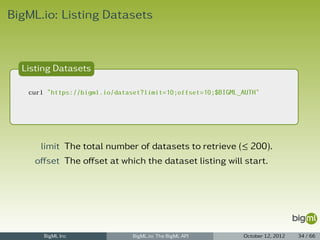
1 { "category": 0,
2 "code": 201,
3 "columns": 5,
4 "created": "2012-05-25T07:13:07.243623",
5 "credits": 0.03515625,
6 "dataset": "dataset/4f66a80803ce8940c5000006",
7 "dataset_status": true,
8 "description": "",
9 "holdout": 0.0,
10 "input_fields": [],
11 "locale": "en_US",
12 "max_columns": 5,
13 "max_rows": 150,
14 "name": "iris' dataset model",
15 "number_of_predictions": 0,
16 "objective_fields": [],
17 "private": true,
18 "range": [
19 1, 150
20 ],
21 "resource": "model/4f67c0ee03ce89c74a000006",
22 "rows": 150,
23 "size": 4608,
24 "source": "source/4f665b8103ce8920bb000006",
25 "source_status": true,
26 "status": {
27 "code": 1, "message": "The model is being processed and will be created soon"
28 },
29 "tags": [],
30 "updated": "2012-05-25T07:13:07.243658" }
BigML Inc BigML.io: The BigML API October 12, 2012 40 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-40-320.jpg)

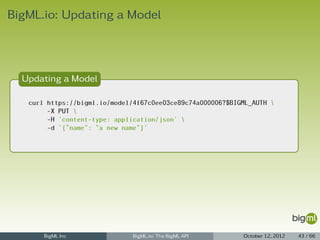
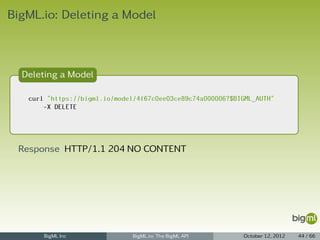
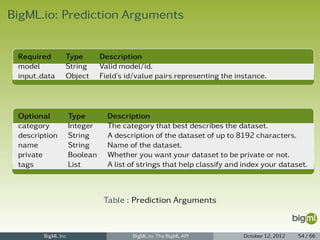
![BigML.io: Creating a Model with args
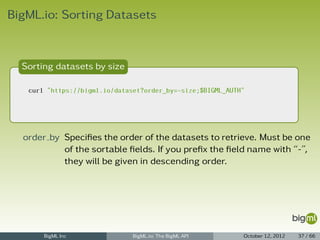
Creating a Model with args
curl https://bigml.io/andromeda/model?$BIGML_AUTH
-X POST
-H 'content-type: application/json'
-d '{"dataset": "dataset/4f66a80803ce8940c5000006", "input_fields": ["000001", "000003"]}'
BigML Inc BigML.io: The BigML API October 12, 2012 42 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-42-320.jpg)

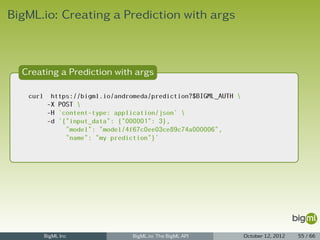
![BigML.io: Model Listing
Model Listing
1 {
2 "meta": {
3 "limit": 10,
4 "next": "/model?limit=10&offset=20&username=ciskoo&api_key=70aaae8d77699bc5d437876d85",
5 "offset": 10,
6 "previous": null,
7 "total_count": 1220
8 },
9 "objects": [
10 {
11 "code": 200,
12 "columns": 1150,
13 ...
14 },
15 ...
16 {
17 "code": 200,
18 "columns": 512,
19 ...
20 }
21 ]
22 }
BigML Inc BigML.io: The BigML API October 12, 2012 48 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-48-320.jpg)

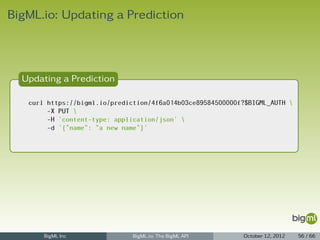
![New Prediction
1 { "code": 201,
2 "created": "2012-03-21T16:26:51.300678",
3 "credits": 0.01,
4 "dataset": "dataset/4f66a80803ce8940c5000006",
5 "dataset_status": true,
6 "fields": { ... },
7 "input_data": { "000001": 3 },
8 "locale": "en-US",
9 "model": "model/4f67c0ee03ce89c74a000006",
10 "model_status": true,
11 "name": "Prediction for species",
12 "objective_fields": [ "000004" ],
13 "prediction": { "000004": "Iris-virginica" },
14 "prediction_path": {
15 "bad_fields": [],
16 "next_predicates": [
17 { "count": 100, "field": "000002", "operator": ">", "value": 2.45 },
18 { "count": 50, "field": "000002", "operator": "<=", "value": 2.45 }
19 ],
20 "path": [],
21 "unknown_fields": []
22 },
23 "private": true,
24 "resource": "prediction/4f6a014b03ce89584500000f",
25 "source": "source/4f665b8103ce8920bb000006",
26 "source_status": true,
27 "status": { "code": 5, "message": "The prediction has been created" },
28 "updated": "2012-03-21T16:26:51.300700" }
BigML Inc BigML.io: The BigML API October 12, 2012 53 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-53-320.jpg)
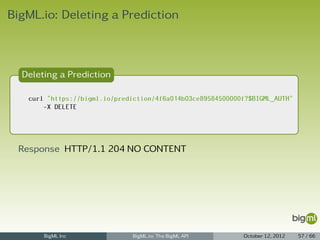
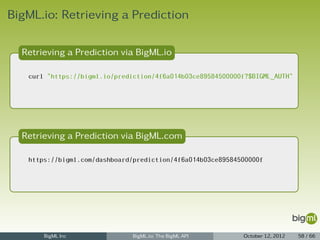
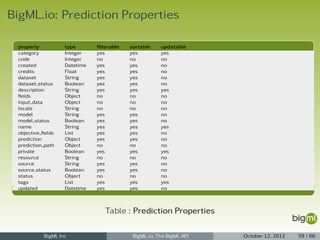
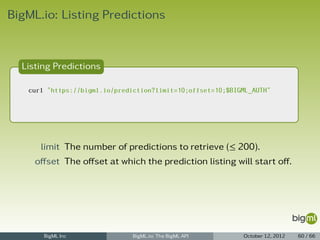
![Prediction Listing
1 { "category": 0,
2 "code": 201,
3 "created": "2012-05-25T07:20:35.687797",
4 "credits": 0.01,
5 "dataset": "dataset/4f66a80803ce8940c5000006",
6 "dataset_status": true,
7 "description": "",
8 "fields": { ... },
9 "input_data": { "000001": 3 },
10 "locale": "en_US",
11 "model": "model/4f67c0ee03ce89c74a000006",
12 "model_status": true,
13 "name": "Prediction for species",
14 "objective_fields": [ "000004" ],
15 "prediction": { "000004": "Iris-virginica" },
16 "prediction_path": {
17 "bad_fields": [],
18 "next_predicates": [
19 { "field": "000002", "operator": ">", "value": 2.45 },
20 { "field": "000002", "operator": "<=", "value": 2.45 }
21 ],
22 "path": [], "unknown_fields": [] },
23 "private": true,
24 "resource": "prediction/4f6a014b03ce89584500000f",
25 "source": "source/4f665b8103ce8920bb000006",
26 "source_status": true,
27 "status": { "code": 5, "message": "The prediction has been created" },
28 "tags": [],
29 "updated": "2012-05-25T07:20:35.687819" }
BigML Inc BigML.io: The BigML API October 12, 2012 61 / 66](https://image.slidesharecdn.com/bigml-io-deck-121027202924-phpapp01/85/BigML-io-The-BigML-API-61-320.jpg)

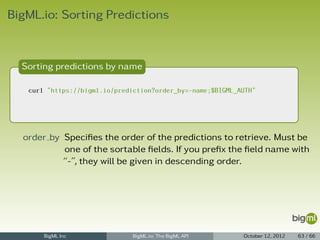




The document provides an overview of the BigML API, detailing its structure, usage, and resources such as sources, datasets, models, and predictions. It includes instructions for authentication, creating, updating, deleting, and retrieving these resources through various methods including local files, remote URLs, and inline data. Additionally, it outlines properties and arguments for each type of resource managed through the API.









































![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)

























