Datapaloozaで発表した資料です。
http://www-01.ibm.com/software/jp/events/analytics2/
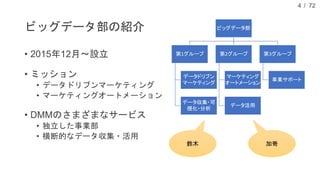
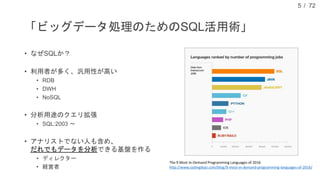
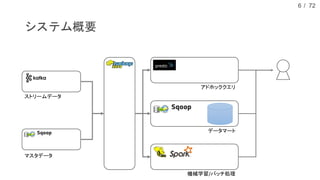
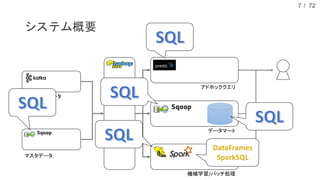
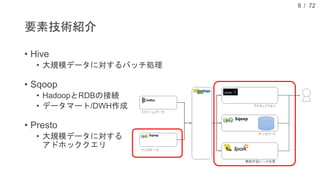
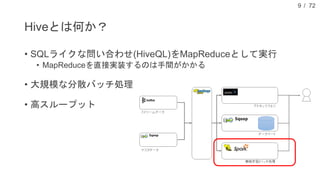
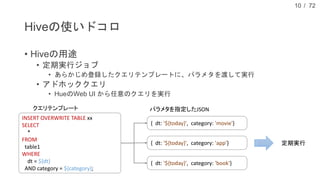
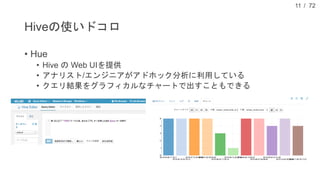
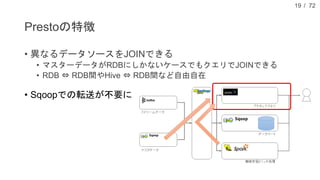
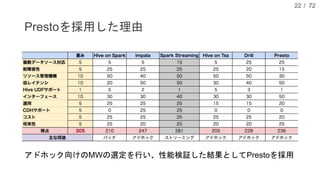
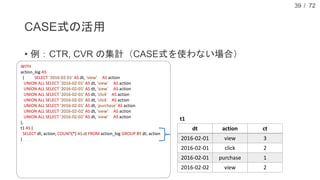
現在、DMM.com ラボでは、1日あたり1億レコード以上の行動ログを中心に、各サービスのコンテンツ情報や、地域情報のようなオープンデータを収集し、データドリブンマーケティングやマーケティングオートメーションに活用しています。本発表では、DMM.comのビッグデータ基盤について紹介し、ビッグデータを処理するためのSQLの活用について発表します。特に、代表的なSQL on HadoopのプロダクトであるHiveやSparkSQL, Prestoの活用事例や、Sqoopを用いたRDBとの連携について、具体的な事例や導入時の注意点を解説し、現状の課題と今後の方針についても紹介します。





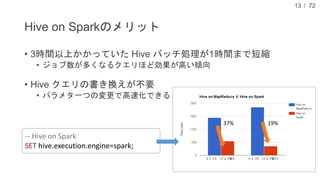
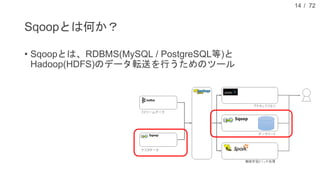
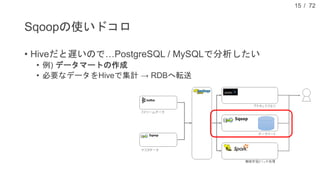
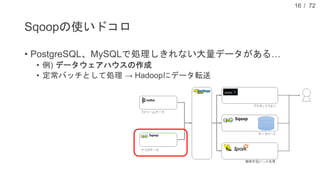

























![/ 72
LATERAL句 × テーブル関数の活用
• explode関数
• テーブル (rows) を返す関数
• 配列や MAP を行に展開する
46
SELECT ARRAY(1, 2, 3);
SELECT EXPLODE(ARRAY(1, 2, 3));
col
1
2
3
SELECT MAP('a', 1, 'b', 2, 'c', 3);
SELECT EXPLODE(MAP('a', 1, 'b', 2, 'c', 3));
key Value
a 1
b 2
c 3
_c0
{"a":1,"b":2,"c":3}
_c0
[1,2,3]](https://image.slidesharecdn.com/dmm-160622080630/85/DMM-com-SQL-46-320.jpg)