Download to read offline




















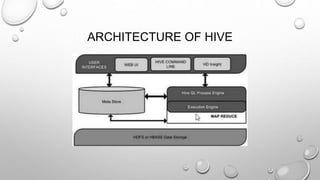





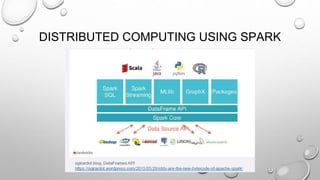

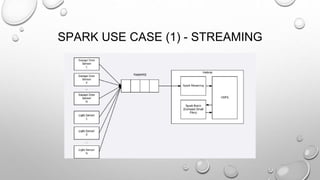





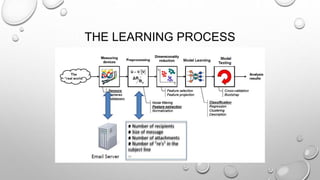





The document discusses the significance of big data from both business and technical perspectives, highlighting benefits such as cost savings, time reductions, and improved product development. It emphasizes the necessary infrastructure for managing big data, including the use of tools like Hadoop and Apache Spark, and strategies for effective implementation. Additionally, it outlines the importance of understanding customer behavior and market conditions to enhance business operations and decision-making.












































![Big_Data_ppt[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatappt11-230720100552-10b674be-thumbnail.jpg?width=640&height=640&fit=bounds)






















