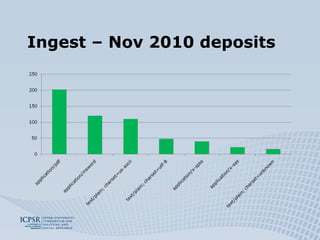
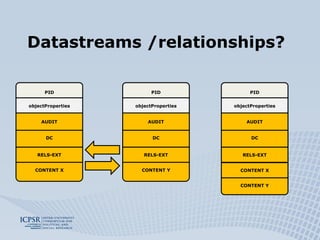
The document discusses the preservation of social science research data using the Fedora system, highlighting the ICPSR's extensive experience and practices in data curation and access. It outlines the processes for ingesting and preserving research data, including the distinction between motivated and unmotivated depositors, and the generation of preservation metadata. Additionally, it addresses challenges and solutions related to data formats, relationships, and the creation of archival information packages.