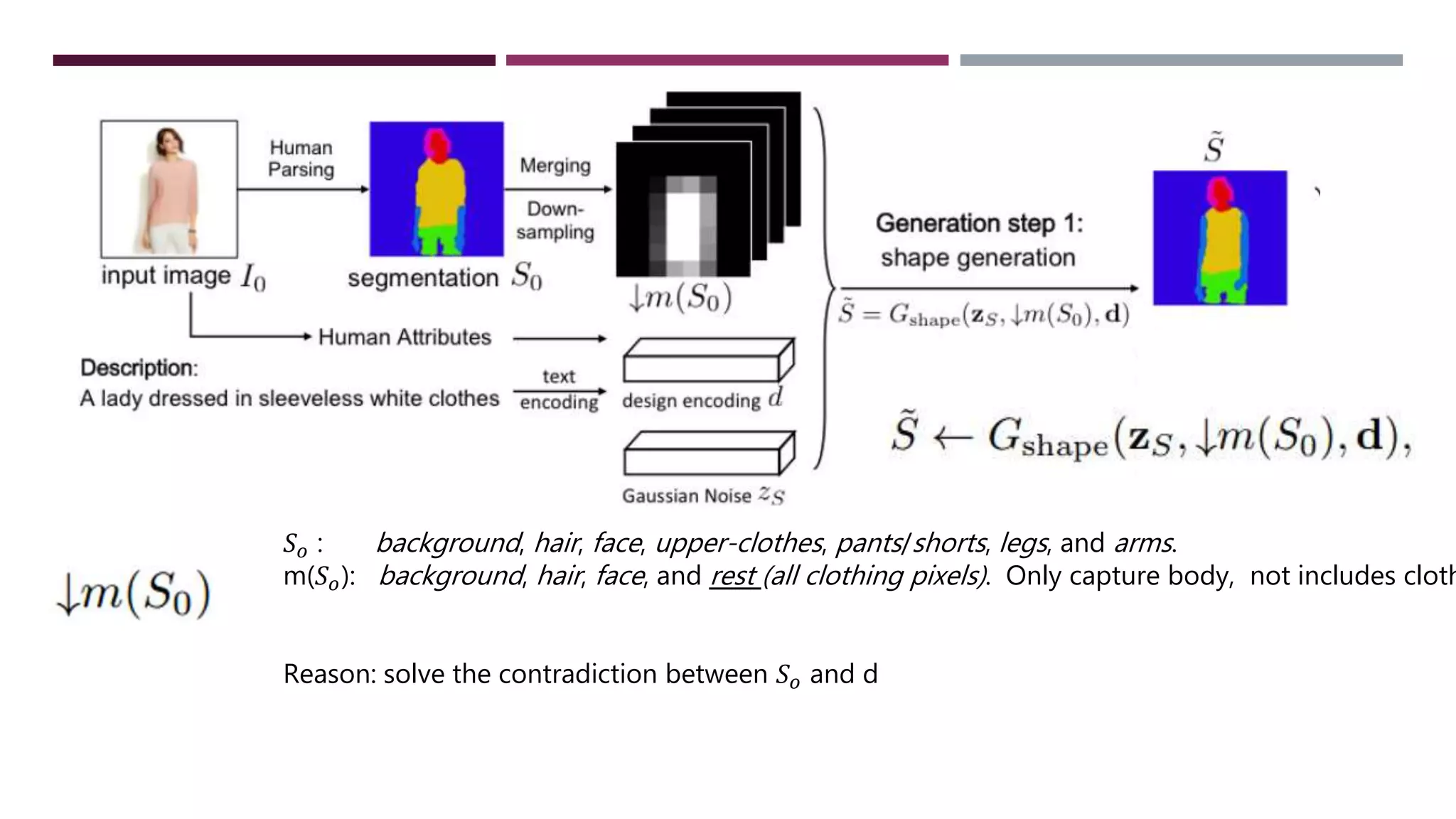
FashionGAN is a model that can generate new outfits for a person in an input image while keeping their pose unchanged. It takes in an input image, a segmentation map of the clothing items, and a text description of a new outfit. FashionGAN then generates a new segmentation map matching the description while maintaining consistency with the person's pose and attributes like gender, hair, and skin color. It renders the new outfit onto the person using the segmentation map and image rendering to realistically redraw the person in the new clothes description. FashionGAN is trained on the DeepFashion dataset containing over 800,000 diverse fashion images with labels.
































![[NS][Lab_Seminar_250616]FashionERN: Enhance-and-Refine Network for Composed F...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250616fashionern-250616115525-b4e48ba0-thumbnail.jpg?width=640&height=640&fit=bounds)










































