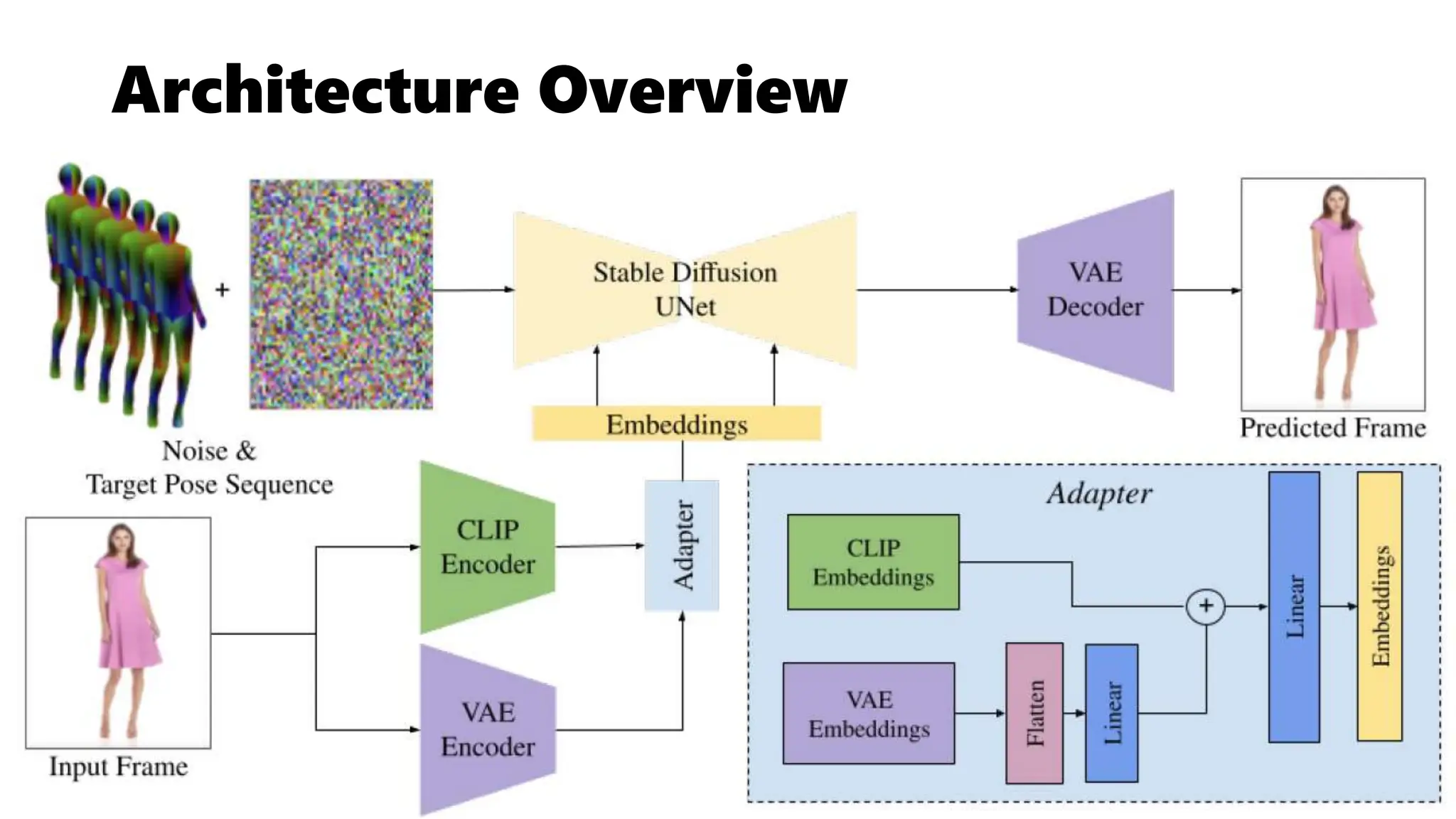
This document describes DreamPose, a method for generating animated fashion videos from still images and pose sequences using a modified Stable Diffusion model. It uses a dual CLIP-VAE encoder and adapter module to condition on both the input image and target poses. The model is fine-tuned on a fashion video dataset to achieve temporal consistency while maintaining fidelity to the input image and target poses. The goal is to synthesize videos where both the human and fabric are moving naturally.




















![[NS][Lab_Seminar_250616]FashionERN: Enhance-and-Refine Network for Composed F...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250616fashionern-250616115525-b4e48ba0-thumbnail.jpg?width=640&height=640&fit=bounds)

































