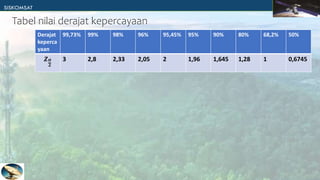
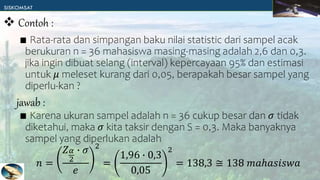
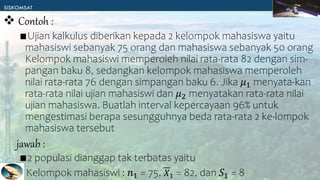
Dokumen tersebut membahas tentang estimasi parameter populasi berdasarkan sampel. Terdapat dua jenis estimasi yaitu estimasi titik yang menggunakan satu nilai statistik dan estimasi interval yang menggunakan rentang nilai statistik. Estimasi interval lebih baik karena melibatkan derajat keyakinan. Contoh soal memberikan penjelasan tentang cara menghitung interval kepercayaan untuk rata-rata, variansi, dan proporsi berdasarkan ukuran sampel dan derajat ke