Download to read offline


![ www.slideshare.net/marco.parenzan
www.github.com/marcoparenzan
marco [dot] parenzan [at] 1nn0va [dot] it
www.1nnova.it
@marco_parenzan
Formazione ,Divulgazione e Consulenza con 1nn0va
Microsoft MVP 2015 for Microsoft Azure
Cloud Architect, NET developer
Loves Functional Programming, Html5 Game Programming and Internet of Things AZURE
COMMUNITY
BOOTCAMP 2015
IoT Day - 08/05/2015
@1nn0va
#microservicesconf2015
9 Maggio 2015](https://image.slidesharecdn.com/2015-160406224443/85/Azure-Document-Db-2-320.jpg)
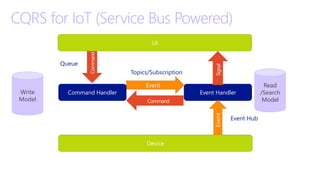
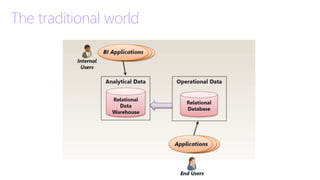
























This document discusses an IoT Day event hosted by 1nn0va on May 8, 2015. It covers topics like representing data models for IoT using DocumentDB, including embedding vs normalizing data and handling one-to-many relationships. It also discusses partitioning strategies for DocumentDB, consistency levels to trade off speed and availability vs consistency, and using weaker consistency for scenarios like IoT and data analysis.



























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















