Download as PDF, PPTX














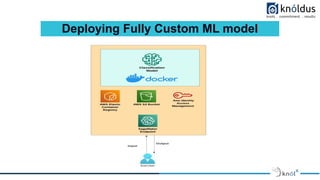





![Deploying Fully Custom ML model
● How SageMaker Runs Your Inference Image
To configure a container to run as an executable, use an ENTRYPOINT instruction in a Dockerfile. Note the
following:
For model inference, SageMaker runs the container as:
● Docker run image serve
SageMaker overrides default CMD statements in a container by specifying the serve argument after the
image name. The serve argument overrides arguments that you provide with the CMD command in the
Dockerfile. We recommend that you use the exec form of the ENTRYPOINT instruction:
● ENTRYPOINT ["executable", "param1", "param2"]
For example:
ENTRYPOINT ["python", "k_means_inference.py"]](https://image.slidesharecdn.com/awsmlmodeldeployment-230117135152-44b20d6f/85/AWS-ML-Model-Deployment-23-320.jpg)




This document summarizes a presentation about deploying custom machine learning models using Amazon SageMaker. It discusses: 1. An overview of machine learning, AWS SageMaker, and how SageMaker works to build, train, test, tune and deploy models. 2. The process for deploying a fully custom ML model with SageMaker, including building the model, defining inference code, creating a SageMaker container, and deploying the model as an endpoint. 3. A demo of this process showing how to create a model, endpoint configuration, and endpoint to deploy a custom model and invoke it via an API.























































































