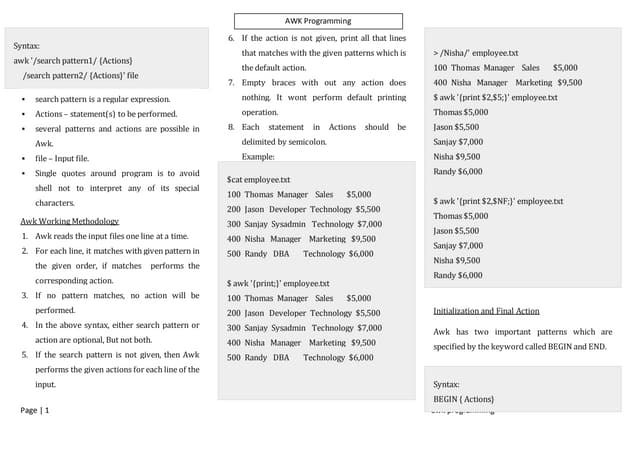
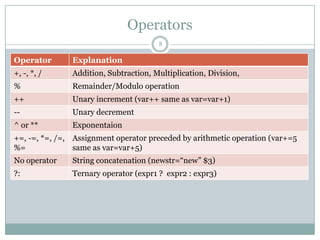
The document serves as a comprehensive introduction to the awk programming language, covering its syntax, built-in variables, operators, and usage examples. It explains how to process text files using patterns and actions, and also demonstrates advanced features like user-defined functions and regular expressions. Additionally, the document provides practical examples and one-liners to illustrate common awk tasks in data manipulation and reporting.



![awk syntax
4
awk [-Ffield_sep] 'cmd' infile(s)
awk [-Ffield_sep] –f cmd_file infile(s)
infile can be the output of pipeline.
Space is the default field_sep](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-4-320.jpg)
![awk mechanics
5
[pattern] [{action} …]
Input files processed a line at a time
Every line is processed if there is no pattern
Lines split into fields based on field-sep
Print is the default action.
Input files not affected in anyway](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-5-320.jpg)



![Regular Expressions
11
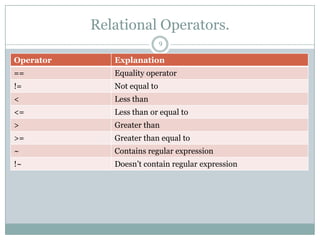
Meta character Meaning
. Matches any single character except newline
* Matches zero or more of the character preceding it
e.g.: bugs*, table.*
^ Denotes the beginning of the line. ^A denotes lines starting
with A
$ Denotes the end of the line. :$ denotes lines ending with :
Escape character (., *, [, , etc)
[] matches one or more characters within the brackets. e.g.
[aeiou], [a-z], [a-zA-Z], [0-9], [[:alpha:]], [a-z?,!]
[^] matches any characters others than the ones inside brackets.
eg. ^[^13579] denotes all lines not starting with odd numbers,
[^02468]$ denotes all lines not ending with even numbers
<, > Matches characters at the beginning or end of words](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-11-320.jpg)

![Regular Expressions – Examples
13
Example Meaning
.{10,} 10 or more characters. Curly braces have to
escaped
[0-9]{3}-[0-9]{2}-[0-9]{4} Social Security number
([2-9][0-9]{2})[0-9]{3}-[0- Phone number (xxx)yyy-zzzz
9]{4}
[0-9]{3}[ ]*[0-9]{3} Postal code in India
[0-9]{5}(-[0-9]{4})? US ZIP Code with optional four-digit extension](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-13-320.jpg)




![BEGIN and END patterns
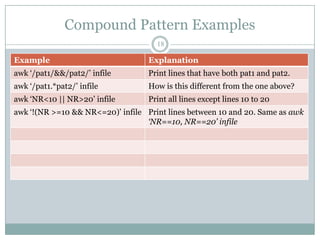
19
BEGIN allows actions before any lines are processed.
END allows actions after all lines have been
processed
Either or both optional
BEGIN {action}
[Pattern] {action}
END {action}](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-19-320.jpg)



![Flow-control statements
23
Statement Explanation
if (conditional) Perform statement_list1 if conditional is true.
{statement_list1} Otherwise statement_list2 if specified
[else {statement_listt2}]
while (conditional) Perform statement_list while conditional is true
{statement_list}
for Perform int_expr firt. While conditional_expr is
(int_expr;conditional_expr true, perform statement_list and execute ctrl_expr.
;ctrl_expr) {statement_list}
break Break from the containing loop and continue with
the next statement
continue Go to the next iteration of the containing loop without
executing the remaining statements in loop
next Skip remaining patterns on this line
exit Skip the rest of the input and go to the END pattern
if one exists or exit.](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-23-320.jpg)
![Print-control statements
24
Statement Explanation
print [expression_list] Print the expression on stdout unless redirected to
[>filename] filename.
printf format [, Prints the output as specified in format (like printf
expression_list] in C). Has a rich set of format specifiers.
[>filename]](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-24-320.jpg)
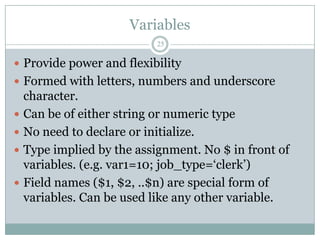
![Arrays
26
One-dimensional arrays: array_name[index]
Index can be either numeric or string. Starts with 1
if numeric
No special declaration needed. Simply assign
values to an array element.
No set size. Limited only by the amount of memory
on the machine.
phone[“home”], phone[“mobile”], phone[var1],
phone[$1], ranks[1]](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-26-320.jpg)
![Multi-Dimensional arrays
27
Arrays are one-dimensional.
Array_name[1,2] not supported
Concatenate the subscripts to form a string which
could be used as the index:
array_name[1”,”2]
Space is the concatenation operator. “1,2”, a three character
string is the index.
Use SUBSEP, subscript separator, variable to
eliminate the need to have double quotes around
the comma.](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-27-320.jpg)
![Built-in functions
28
Function Explanation
cos(awk_expr) Cosine of awk_expr
exp(awk_expr) Returns the exponential of awk_expr (as in e raised to the
power of awk_expr)
index(str1, str2) Returns the position of strt2 in str1.
length(str) Returns the length of str
log(awk_expr) Base-e log of awk_expr
sin(awk_expr) Sine of awk_expr
sprintf(frmt, awk_expr) Returns the value of awk_expr formatted as per frmt
sqrt(awk_expr) Square root of awk_expr
split(str, array, [field_sep]) Splits a string into its elements and stores into an array
substr(str, start, length) Returns a substring of str starting at position “start” for
“length” characters.
toupper(), tolower() Useful when doing case-insensitive searches](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-28-320.jpg)
![Built-in functions contd.
29
Function Explanation
sub(pat1, “pat2”, [string]) Substitute the first occurrence of pat1 with pat2 in string.
String by default is the entire line
gsub(pat1, “pat2”, [string]) Same as above, but replace all occurrences of pat1 with
pat2.
match(string, pat1) Finds the regular expression pat1, and sets two special
variables (RSTART, RLENGTH) that indicate where the
regular expression begins and ends
systime() returns the current time of day as the number of seconds
since Midnight, January 1, 1970](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-29-320.jpg)



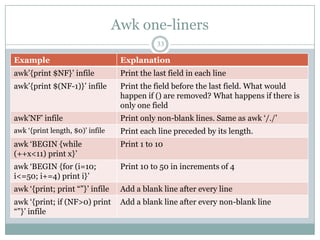

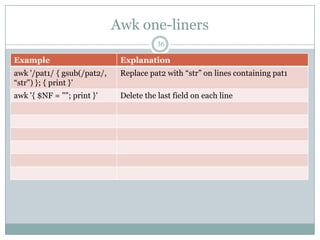
![Awk one-liners
35
Example Explanation
awk „length < 81‟ Print lines that are shorter than 81 characters
awk „/pat1/, 0‟ Print all lines between the line containing pat1 and
end of file
awk „NR==10, 0‟ Print lines 10 to the end of file. The end condition
“0” represents “false”.
awk '{ sub(/^[ t]+/, ""); Trim the leading tabs or spaces. Called ltrim
print }'
awk '{ sub(/[ t]+$/, ""); Trim the trailing tabs or spaces. Called rtrim
print }'
awk '{ gsub(/^[ t]+|[ Trim the white spaces on both sides
t]+$/, ""); print }'](https://image.slidesharecdn.com/awkessentials-120508151057-phpapp02/85/Awk-essentials-35-320.jpg)