Downloaded 24 times









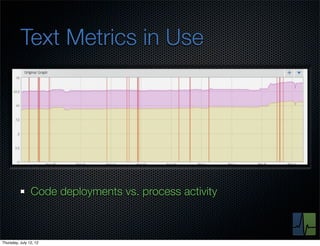

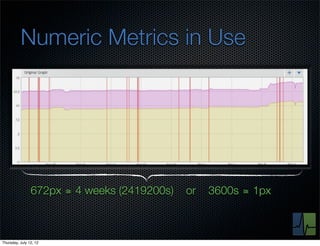
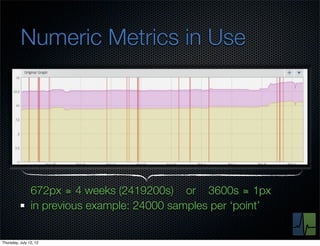
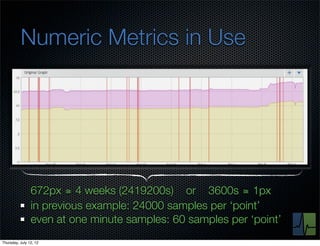





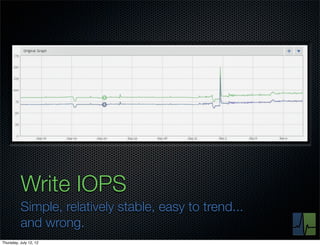
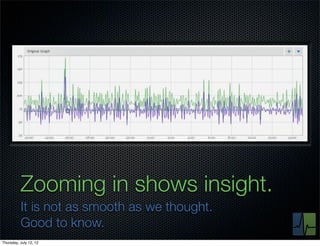
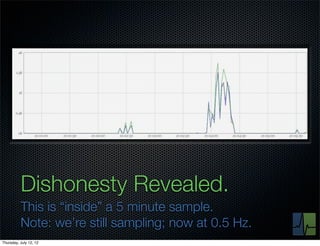












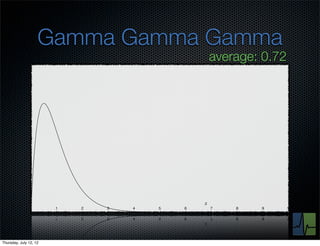
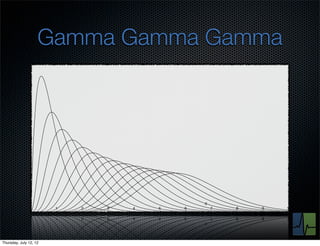
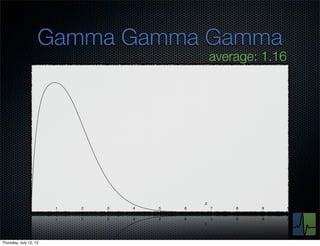
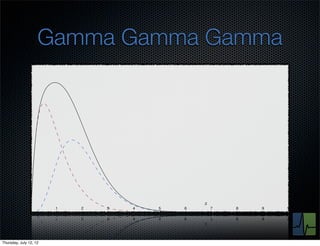
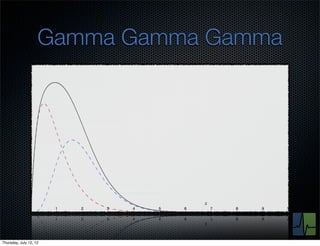
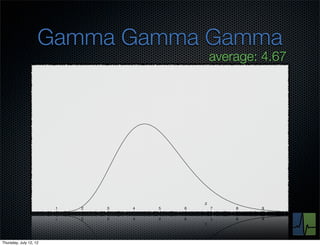







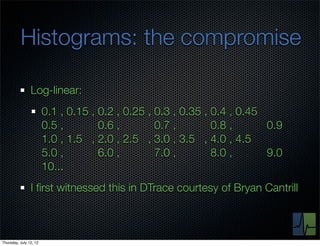

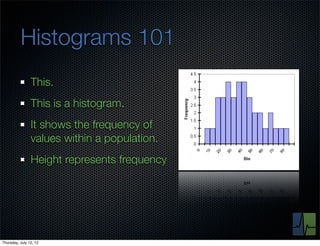
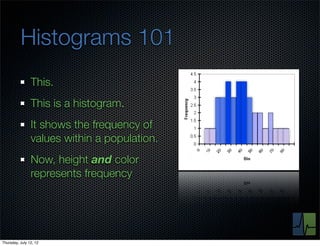
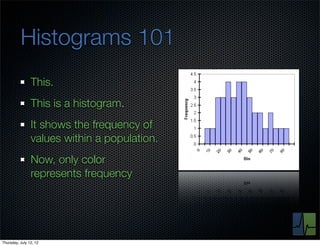















The document discusses monitoring and measuring systems by observing behaviors and metrics over time. It notes that every observation distills down to two elements - the circumstances or context being measured, and the value or result. Context includes dimensions like what is being measured, location, time, etc. Values can be numeric metrics or text outcomes. The document advocates for capturing both passive data reflecting real events as well as active tests to better understand system performance in low traffic environments. It also stresses that averaging or sampling can hide variability, so capturing additional statistical details beyond just the average value provides more useful insights.









































































