This document describes research on using mobile hyperspectral imaging to detect material surface damage. It discusses how hyperspectral imaging captures hundreds of spectral reflectance values per pixel, providing more information than traditional RGB images. The researchers developed a mobile hyperspectral imaging system and machine learning models to classify different surface objects, including cracks. Experimental results showed hyperspectral pixels could identify eight surface objects with high accuracy, outperforming gray-valued images with higher spatial resolution. The researchers conclude hyperspectral imaging has great potential for automating damage inspection, especially for complex scenes on built structures.


![With advances in HSI and especially sensors that are not for
orbital or airborne platforms, the acquisition of hyperspectral cubes
can be realized with other mechanisms. In addition to the spatial
scanning or push-broom imaging mechanism, two other mecha-
nisms (spectral scanning and spatial-spectral scanning) were devel-
oped for HSI applications in medical and biological sciences (Lu
and Fei 2014). These three scanning techniques require complex
postprocessing steps to achieve the end product, a data cube. The
fourth mechanism is nonscanning, and is termed snapshot imaging
(Johnson et al. 2004). Snapshot imaging acquires spectral pixels
in a 2D field of view simultaneously, without the requirement of
trajectory flights or using any moving parts in the imager. There-
fore, this snapshot mechanism also is referred to as real-time HSI
(Bodkin et al. 2009), and can achieve much higher frame rates and
higher signal-to-noise ratios, and can provide hyperspectral cubes
immediately after every action of capturing, as in a regular digital
camera. Due to this property, real-time or snapshot HSI opens up
significant opportunities for its use in portable or low-altitude re-
mote sensing.
Hyperspectral Image Computing
A hyperspectral cube can be denoted hðx; y; sÞ, where ðx; yÞ are
the spatial coordinates (in terms of pixels) and s is the spectral
coordinate in terms of spectral wavelength—i.e., for visible bands,
s ∈ ½400,600 nm, and for visible to near-infrared bands, s ∈ ½400;
1,000 nm. At a select location of ðx; yÞ, therefore, hðx; y; sÞ rep-
resents a spectral profile when plotted against the spectral variable
s. In the remote-sensing context (not in a medical or biological
context), i.e., when the data cube is acquired in the air, the meas-
urement at the sensor is the upwelling radiance. In general, the re-
flectance property of a material at the ground nominally does not
vary with solar illumination or atmospheric disturbance. Therefore,
the reflectance profile of a pixel reflects the characteristic or sig-
nature of the material at that pixel. Therefore, a raw-radiance data
cube needs to be corrected to generate a reflectance cube, consid-
ering the environmental lighting and the atmospheric distortion.
This process is called atmospheric correction (Adler-Golden et al.
1998). For this, many physics-based algorithms exist, including the
widely used fast line-of-sight atmospheric analysis of spectral
hypercubes (FLAASH) (Cooley et al. 2002).
The most frequent use of hðx; y; sÞ as a reflectance cube is
material detection. Compared with single-band or three-band pixels
in common images, the distinct property of hyperspectral images
is the high dimensionality of the pixels. This high-dimensionality
is the foundation of spectroscopy for material identification. To
achieve such identification, various unmixing methods have been
developed to distinguish the statistically significant material types
and their abundance levels underlying the spectral profile of a pixel
(Bioucas-Dias et al. 2012; Heylen et al. 2014). If the concern is not
a specific material (that consists of single molecules or atoms), but
an object is of interest, extracting and selecting descriptive features
at hyperspectral pixels becomes the first stage. This stage, com-
monly called feature description, is as common as it is in a typical
machine-learning process. If pixel-based object detection is con-
cerned, the dimensionality of hyperspectral pixels poses the first
challenge. To avoid the so-called curse of dimensionality when
using machine learning methods, early efforts emphasized the
development of dimensionality reduction (DR) methods for select-
ing representative feature values across spectral bands. The most
commonly used DR methods are mathematically linear, including
principal component analysis (PCA) and linear discriminant analy-
sis (LDA) (e.g., Bandos et al. 2009; Chen and Qian 2008; Hang
et al. 2017; Palsson et al. 2015). Other advanced, and usually
nonlinear, methods, such as the orthogonal subspace projection
method (Harsanyi and Chang 1994) and the locally linear embedding
method (Chen and Qian 2007), are also found in the literature. For
semantic segmentation–based object detection, feature description
needs to consider the spatial distribution of hyperspectral pixels.
The most straightforward treatment is to extract feature vectors based
on the dimensionality-reduced hyperspectral pixels, as in extracting
features in a gray or a color image. Advanced methods in recent years
have concerned the extraction of spatial–spectral features in three di-
mensions (Fang et al. 2018; Hang et al. 2015; Zhang et al. 2014). For
the classification design, as the second stage of a conventional
machine-learning problem, the commonly used classical classifiers
include artificial neural network (ANN), support vector machine
(SVM), decision tree, k-nearest neighbor (KNN), and nonsupervised
clustering techniques such as k-means (Goel et al. 2003; Ji et al. 2014;
Marpu et al. 2009; Mercier and Lennon 2003).
As deep learning became a focus in the machine vision com-
munity, DL models have been developed in recent years which
potentially unify DR, feature description, and classification in
end-to-end architectures for hyperspectral image–based object de-
tection. Chen et al. (2014) integrated PCA, stacked autoencoder
(SAE), and logical regression into one DL architecture (Chen
et al. 2014). Convolutional neural networks (CNNs), as commonly
adopted in regular machine-vision problems, were introduced in
subsequent years (Chen et al. 2016; Hu and Jia 2015; Li et al.
2017). These advances imply the advent of computational hyper-
spectral imaging or hyperspectral machine vision, which may im-
pact many engineering fields, including damage inspection in civil
engineering.
Mobile Hyperspectral Imaging System
A mobile HSI system for ground-level and low-altitude remote
sensing was developed by the authors. The imaging system consists
of a Cubert S185 FireflEYE snapshot camera (Ulm, Germany) and
a mini-PC server for onboard computing and data communication
(Cubert 2018). For ground-based imaging, the system is mounted
to a DJI gimbal (Shenzhen, China) that provides two 15-W,
1580-mA·h batteries for powering both the imaging payload and
the operation of the gimbal. Fig. 1(a) shows the gimbaled imaging
system ready for handheld or other ground-based HSI. To enable
low-altitude remote sensing, an unmanned aerial vehicle is used,
and the gimbaled system can be installed easily on the UAV for
remote sensing [Fig. 1(b)].
The Cubert camera has a working wavelength range of 450–
950 nm covering most of the VNIR wavelengths, spanning 139
bands, with a spectral resolution of 8 nm in each band. The raw
sensor has a snapshot resolution of 50 × 50 spectral channels.
Natively, the imager captures radiance images; with a proper cal-
ibration procedure and the internal processing in the onboard com-
puter, the camera can output reflectance images directly. To do so, a
calibration process starts with the use of a standard white reference
board, achieving a data cube for the standard whiteboard (denoted
hW). Then a perfect dark cube is obtained (by covering the lens
tightly with a black cap), denoted hB. The relative reflectance im-
age, h, is calculated given a radiance cube hR
h ¼
hR − hw
hw − hB
ð1Þ
Following Eq. (1), a reflectance image can be produced by the
camera system directly or can be postprocessed from the generated
radiance image.
One unique feature of the Cubert HSI system is its dual acquis-
ition of hyperspectral cubes and a companion gray level–intensity
© ASCE 04020057-3 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2021, 35(1): 04020057
Downloaded
from
ascelibrary.org
by
University
of
Liverpool
on
11/14/20.
Copyright
ASCE.
For
personal
use
only;
all
rights
reserved.](https://image.slidesharecdn.com/aryal-220629012212-d6bf204a/75/Aryal-pdf-3-2048.jpg)


![improve classification performance. In general, PCA is a statistical
procedure that converts a set of data points with a high dimension
of possibly correlated variables into a set of new data points that
have linearly uncorrelated variables or are mutually orthogonal,
called principal components (PCs). The component scores associ-
ated with the orthogonal PCs construct the coordinates in a new
space spanned by the PCs. By selecting several dominant PCs (less
than the original dimension of the data point), the original data
points can be projected to a lower-dimension subspace. Therefore,
the select PC scores for an originally high-dimension feature point
can be used as a dimension-reduced feature vector. In this study, the
first six components were selected empirically after testing from the
first three to the first seven components. In addition, a normaliza-
tion step was conducted for all PCA features at all pixels. The PC
scores, when visualized, can be used as a straightforward approach
to inspecting the discrimination potential of the features, which oth-
erwise are not possible if the original high-dimension hyperspectral
profiles are plotted. These illustrations are described subsequently.
Histogram of Oriented Gradients
The histogram of oriented gradient feature descriptor characterizes
the contextual texture or shape of objects in images by counting the
occurrence of gradient orientations in a select block in an image or
in the whole image. It was first proven effective by Dalal and Triggs
(2005) in their seminal effort for pedestrian detection in images;
since then, HOG has been applied extensively for different objec-
tive detection tasks in the literature of machine vision. HOG differs
from other scale-invariant or histogram-based descriptors in that its
extraction is computed over a dense grid of uniformly spaced cells,
and it uses overlapping local contrast normalization for improved
performance. There are many variants of HOG descriptors for im-
proving the robustness and the accuracy; a commonly used variant
is HOG-UoCTTI (Felzenszwalb et al. 2010). The original HOG
extractor and its variants are formulated over a gray image, which
is convenient to the research in this study, in which a companion
gray-image exists for every hyperspectral cube.
Considering the resolution compatibility between the hyper-
spectral cube and the companion gray-level image, the feature ex-
traction was conducted in a 20 × 20 sliding neighborhood in a gray
image. Within this neighborhood, four histograms of undirected
gradients were averaged to obtain a no-dimensional histogram
(i.e., binned per their orientation into nine bins, no ¼ 9) and a sim-
ilar operation was performed for the directed gradient to obtain a
2no-dimensional histogram (i.e., binned according to gradient into
18 bins). Along with both directed and undirected gradient, the
HOG-UoCTTI also computed another four-dimensional texture-
energy feature. The final descriptor was obtained by stacking the
averaged directed histogram, averaged undirected histogram, and
four normalized factors of the undirected histogram. This led to
the final descriptor of size 4 þ 3 × no (i.e., a 31 × 1 feature vector).
Multiclass Support Vector Machine
In the traditional machine vision literature, the combined use of
SVM as a classifier and HOG as a feature descriptor is regarded
as a de facto approach for visual recognition tasks or a benchmark-
ing model if used to validate a novel model (Bilal and Hanif 2020;
Bristow and Lucey 2014). This fact partially supports the selection
of SVM (in lieu of many other classical models) in this effort.
A native SVM is a binary classifier that separates data into classes
by fitting an optimal hyperplane in the feature space separating all
training data points into two classes. As described by Foody and
Mathur (2006), the most optimal hyperplane is the one that max-
imizes the margin (i.e., from this hyperplane, the total distance to
the nearest data points of the two classes is maximized).
When the data do not have linear boundaries according to their
underlying class memberships, the finite feature-vector space can
be transformed into a functional space, which is termed the kernel
trick. The Gaussian kernel is widely used and was adopted in this
study, which is parameterized by a kernel parameter (γ). Another
critical parameter, often denoted C, is a regularization parameter
that controls the trade-off between achieving a low training error
and a low testing error or that controls the generalization capability
of the SVM classifier. Pertinent to a model selection problem, these
two hyperparameters can be determined through a cross-validation
process during the training. In the SVM literature, 10-fold cross-
validation often is used to determine the hyperparameters (Foody
and Mathur 2006). To accommodate multiclass classification based
on a binary SVM classifier, two well-known designs can be adopted:
(1) one-versus-all design; and (2) pairwise or one-versus-one design
(Duan et al. 2007). This study adopted the one-versus-one design.
MATLAB version R2018a and its machine-learning toolbox were
employed to implement the multiclass SVM–based learning, includ-
ing training and testing.
Data Collection and Preparation
With the mobile HSI system [Fig. 1(a)], a total of 68 instances of
hyperspectral images (and their companion gray-level images)
were captured in the field. Among these images, 43 images were
of concrete surfaces and 25 images were of asphalt surfaces. To
create scene complexity, artificial markings, oil, water, and green
and dry vegetation were added in 34 concrete images and 16 as-
phalt images that had hairline or apparent cracks. Of the remaining
18 images, 9 images each were were of concrete and asphalt pave-
ments without cracks. A proper calibration process was included
before the imaging; therefore, the obtained data all were reflectance
cubes. Due to the fixed exposure setting of the camera, the gray
images were captured physically as relatively dark pixels, and hence
had low visual contrast [Figs. 3(a and c)]. In Figs. 3(a and c), no
image enhancement (e.g., histogram equalization) is introduced;
nonetheless, the contrast-normalization step in a HOG descriptor
effectively can mitigate this issue before producing the gray value–
based feature vectors.
To create a supervised learning–ready data set, manual and se-
mantic labeling was carried out. Semantic labeling is the process of
labeling each pixel in an image with a corresponding class label.
This study used an image-segmentation (or image parsing) based
labeling approach in which clustered pixels belonging to the same
class were delineated in the image domain and rendered with a
select color. The labeling is based on the gray-level image that
accompanies a hyperspectral cube. In this work, this process was
conducted using an open-source image processing program, GIMP
version 2.10.12. During the labeling process, a total of six different
classes, including cracking, green vegetation, dry vegetation, water,
oil, and artificial marking, were assigned the colors black, green,
brown, blue, red, and yellow, respectively [Figs. 3(b and d)]. The
background materials (concrete and asphalt) were not classified in
these complex images or in the plain (concrete/asphalt) images.
To advance hyperspectral imaging–based machine learning and
damage detection research, the authors have shared this unique data
set publicly (Chen 2020).
Feature Calculation and Visualization
The colored mask images, denoted mðu; vÞ, share the same spatial
domain as the underlying gray image gðu; vÞ. For the sake of sim-
plicity, based on the color coding for the mask images, the value of
mð·Þ takes an integer value of 1, 2, : : : , 6 to indicate the underlying
© ASCE 04020057-6 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2021, 35(1): 04020057
Downloaded
from
ascelibrary.org
by
University
of
Liverpool
on
11/14/20.
Copyright
ASCE.
For
personal
use
only;
all
rights
reserved.](https://image.slidesharecdn.com/aryal-220629012212-d6bf204a/75/Aryal-pdf-6-2048.jpg)
![six surface objects; in addition, the following notations are used to
describe the resulting data set:
D ¼ fhnðx; y; sÞ; gnðu; vÞ; mnðu; vÞjn ¼ 1; 2; : : : ; 50g ð2Þ
To generate the machine-learning data for the models, the fol-
lowing process was developed:
1. Iterating with the location of (xi; yj), where i; j ¼ 1; 2; : : : ; 50,
the spectral profile is stored in the vector {hðxi; yj; sÞjs ∈
½1; 139}, and the gray values in the corresponding gray
image gðu; vÞ are confined in a neighborhood block of b ¼
fðu0; v0Þju0 ∈ ½ðxi − 1Þ × 20 þ 1; xi × 20; and v0 ∈ ½ðyj − 1Þ ×
20 þ 1; yj × 20g. In this neighborhood of b, the gray-level im-
age patch and the corresponding mask patch corresponding to
the hyperspectral pixel at ðx; yÞ are denoted gðbÞ and mðbÞ,
respectively.
2. Given the mask patch mðbÞ, a simplified process is used to se-
lect the underlying class label for the hyperspectral pixel at
(xi; yj). By counting the number of pixels belong to different
object types within the neighborhood block b
a. if a dominant class label exists, i.e., the number of pixels that
belong to a class is greater than 50% of the total pixels in the
block (namely 200=400 pixels), this class label is assigned to
(xi; yj); and
b. if no dominant class label exists, this pixel (xi; yj) and the
corresponding neighborhood b is skipped.
3. At a pixel with a dominant class label, and per the feature ex-
traction method (HYP, HYP_PCA, and GL_HOG)
a. if HYP is used, fhðxi; yj; sÞjs ∈ ½1; 139g is directly used as
the feature vector with a dimension of 139 × 1;
b. If HYP_PCA is used, PCA is conducted over the vector
fhðxi; yj; sÞjs ∈ ½1; 139g, and the first 6 PC scores are used
to form a much lower-dimensional 6 × 1 feature vector;
c. if GL_HOG is used, the feature extraction is based on the
gray-level patch gðbÞ using the HOG-UoCTTI method, re-
sulting in a 31 × 1 feature vector; and
d. if HYP_PCA + GL_HOG is fused, the two corresponding
feature vectors simply are concatenated, resulting in a 37 × 1
feature vector.
4. By iterating this procedure over all the hyperspectral pixels for
all 50 instances of images, which include different types of
features in consideration, the following classification data set
is obtained for each of the feature extraction methods:
DFEA
¼ fðpk; ckÞjk ¼ 1; 2; : : : ; Kg ð3Þ
where FEA represents one of the feature extraction processes,
HYP, HYP_PCA, GL_HOG, or HYP_PCA+GL_HOG. By
skipping many background pixels or pixels that do not have
dominant labels in Step 2b, the resulting number of meaningful
pixels (with dominant class labels) is 29,546, 8,132, 6,495,
6,273, and 5,312 features were obtained for the class labels (ck)
of water, oil, artificial marking, and green vegetation, respec-
tively. The number of features for cracks (concrete and asphalt
cracks) was 2,377. The dry vegetation features had the smallest
number of features, 957.
With the data cubes and gray images for the plain concrete
and asphalt surfaces (9 pairs each), 2,601 features arbitrarily were
obtained without using mask images individually for the concrete
and the asphalt labels. After adding these features into Eq. 3, the
number of labeled features used in this study [Eq. (3), K] was
34,748. As described previously, given the smallest (957) and the
largest (8,132) number of features, a moderate imbalance existed.
Based on the data in Eq. (3) and the original hyperspectral
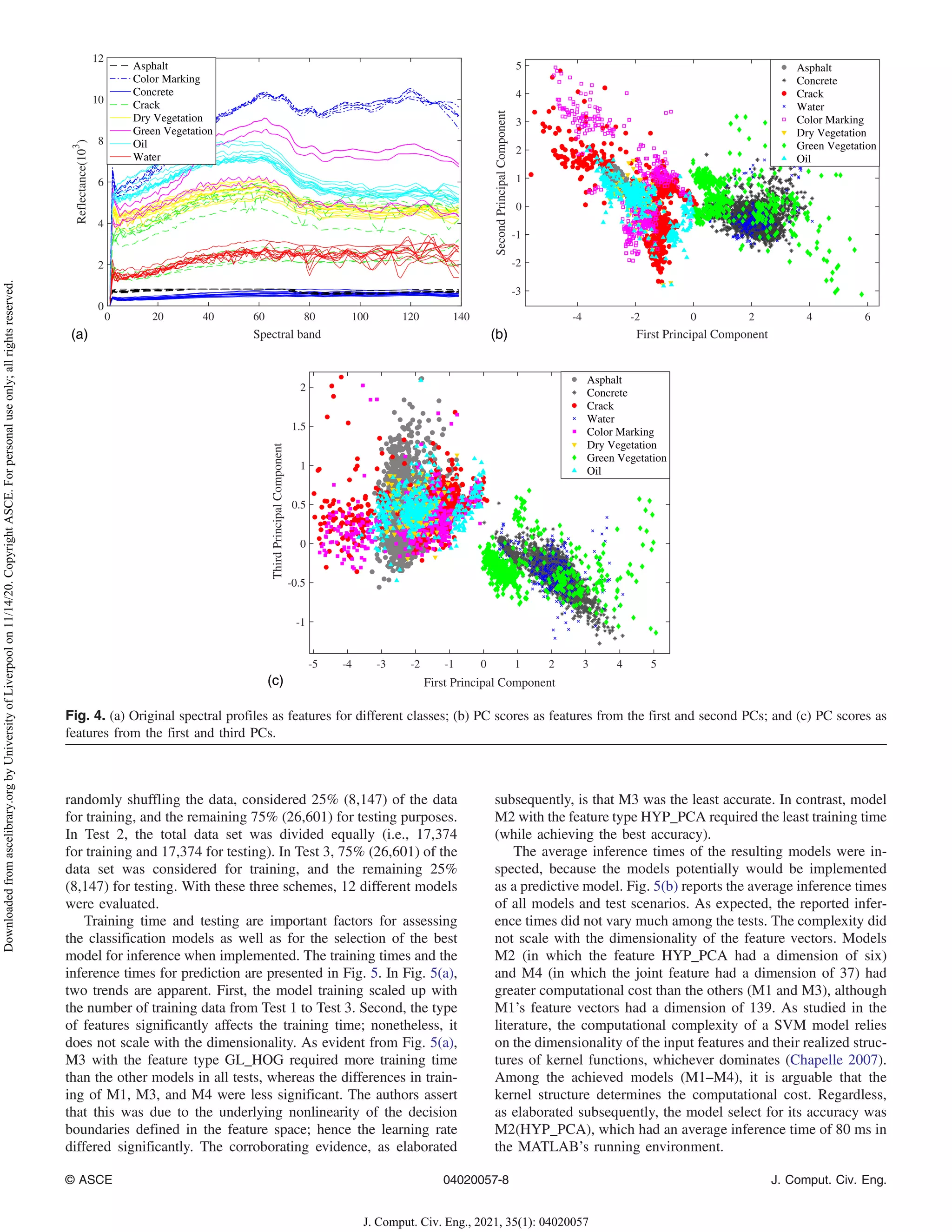
pixels, three plots in Fig. 4 qualitatively illustrate the potential dis-
crimination power of hyperspectral pixels. Fig. 4(a) plots the origi-
nal spectral profiles of eight underlying objects (with only five
sample profiles for each object). Although the separability is evi-
dent, it is objectively hard to discern their potential capability of
prediction. Figs. 4(b and c) plot the first three primary PC scores
for obtained HYP_PCA features. These plotsshow the underlying
discrimination potential between all classes. HOG-based feature
vectors, which are in the form of histograms, also can be plotted;
however, it is challenging to discern their discrimination potential
visually; this is possible only through a classification model.
Experimental Tests and Performance Evaluation
Data Partition and Computational Cost
To proceed with the modeling and performance evaluation, a data
partition strategy is needed to split the data; one part is for the
training, and the other part is for model validation. In the literature,
the widely used scheme is to use 75% of the total data for training
and the remaining 25% for testing. Indeed, if there is a sufficient
amount of data, the data splitting ratio is flexible and is up to
the analyst. In this study, it was meaningful to examine whether
the amount of data size was sufficient, which can be determined
if the prediction performance increases with the amount of train-
ing data. Three data splitting schemes were considered for the
obtained feature data sets [Eq. (3)]. The first scheme, Test 1, after
Fig. 3. (a) Gray image of concrete surface; (b) mask image for (a); (c) gray image of asphalt surface; and (d) mask image for (c). Colored mask images
in (b) and (d) appear in the online version.
© ASCE 04020057-7 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2021, 35(1): 04020057
Downloaded
from
ascelibrary.org
by
University
of
Liverpool
on
11/14/20.
Copyright
ASCE.
For
personal
use
only;
all
rights
reserved.](https://image.slidesharecdn.com/aryal-220629012212-d6bf204a/75/Aryal-pdf-7-2048.jpg)


![pavements), the underlying materials are very diversified, and over-
all all the reflectance intensities are darker than other objects. The
dry vegetation type had the least number of instances in the data set,
which partially contributed to the relatively poor performance com-
pared with the prediction for the green vegetation. In addition, in all
tests of all models, the precision and recall measurements were rel-
atively close for all class labels except cracks and dry vegetation.
This was particularly significant for M1(HYP) and M3(GL_HOG),
for which the recall values tended to be much smaller than the pre-
cision values. This means that in the cases of these two objects, each
instance of prediction tended to be correct; however, the models
tended to miss many objects that were either cracks or dry vegetation
objects. Furthermore, this result implies that a trade-off measure,
such as the F1 score, should be used as a better accuracy measure.
To determine the coherency and the distinction of these differ-
ent measurements, scatter plots of all measures are illustrated in
Figs. 6(a–d) for models M1–M4, respectively; for the sake of brev-
ity, only the Test 2 data scheme is included. Figs. 6(a–d) plot the F1
scores against themselves (as indicated by a 1:1 line), and all other
measurements are plotted against F1. The AU-PR as a model
capacity measure was statistically consistent with the F1 score, be-
cause it followed a linear trend in each model with a high R2 value
(R2
0.87). This implies that AU-PR largely was redundant as a
capacity measure. Therefore, the F1 score can replace it as both
a prediction accuracy measure and a model capacity measure.
The AU-ROC measure was adopted as a model-capacity measure
because it was invariant to classification thresholds and nonredun-
dant to the F1 score.
Performance Evaluation
The F1 score and AU-ROC were used as two primary performance
measures in this study. To meet the objectives outlined previously,
Figs. 7(a–d) illustrate the performance of all four models. Fig. 7(a)
shows the F1 scores for Test 1 data; Fig. 7(b) shows the F1 scores
for Test 3 data; Fig. 7(c) shows the AU-ROC for Test 1 data; and
Fig. 7(d) shows the AU-ROC for Test 3 data. The results from Test
2 are not included herein because the observed trends from Test 2
results are between Test 1 and Test 2. The following evaluation
focuses on the four objectives of this study described previously.
The F1 scores of Model M1(HYP) [Figs. 7(a and b)] indicate
that the model successfully identifies (F1 0.7) the plain concrete,
asphalt, green vegetation, and water. For the ed marking and oil, the
F1 score was about 0.6. However, for cracks and dry vegetation, the
F1 measurements were less than 0.3, indicating little prediction ac-
curacy. First, this reflects the challenge in recognizing cracks, pri-
marily caused by the inherent spectral complexity. Second, it is
primarily due to the smaller number of dry-vegetation data points.
For both objects, this presumptively is attributed to the high dimen-
sionality of the feature vectors of HYP. Nonetheless, as expected
R = 0.9882
0.1
0.3
0.5
0.7
0.9
0.1 0.3 0.5 0.7 0.9
Measure
value
F1
Preccision Recall F1
AU-ROC AU-PR Linear (F1)
Linear (AU-PR)
= 0.9181
0.8
0.85
0.9
0.95
1
0.8 0.85 0.9 0.95 1
F1
Preccision Recall F1
AU-ROC AU-PR Linear (F1)
Linear (AU-PR)
= 0.9877
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Measure
value
F1
Preccision Recall F1
AU-ROC AU-PR Linear (F1)
Linear (AU-PR)
= 0.8724
0.4
0.5
0.6
0.7
0.8
0.9
1
0.4 0.5 0.6 0.7 0.8 0.9 1
Measure
value
F1
Preccision Recall F1
AU-ROC AU-PR Linear (F1)
Linear (AU-PR)
Measure
value
2
R2
R2
R2
(a) (b)
(c) (d)
Fig. 6. Performance measurement scatter plots using Test 2 data: (a) M1; (b) M2; (c) M3; and (d) M4.
© ASCE 04020057-11 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2021, 35(1): 04020057
Downloaded
from
ascelibrary.org
by
University
of
Liverpool
on
11/14/20.
Copyright
ASCE.
For
personal
use
only;
all
rights
reserved.](https://image.slidesharecdn.com/aryal-220629012212-d6bf204a/75/Aryal-pdf-11-2048.jpg)
![from the AU-ROC measurements [Figs. 7(c and d)], there is no
doubt that Model M1(HYP) is highly effective in recognizing these
structural surface objects. For concrete, the average AU-ROC was
about 1. Therefore, hyperspectral pixels as feature vectors are ef-
fective in recognizing most of the structural surface objects, and
have relatively less accuracy only in the detection of cracks and
dry vegetation.
Comparing the accuracy of Model M2(HYP_PCA) with that of
M1(HYP) [Figs. 7(a and b)] showed that the detection accuracy sig-
nificantly increased. For the two weak prediction instances of cracks
and dry vegetation in M1(HYP), the F1 score increased from 0.198
to 0.917 in Test 1 and from 0.107 to 0.96 in Test 3 with Model M2
(HYP_PCA). For dry vegetation, the F1 scores changed from 0.246
to 0.757 in Test 1, and from 0.278 to 0.887 in Test 3. For all other
class labels, the classification accuracy still increased from their ini-
tially high F1 values from M1 to M2. When inspecting Fig. 7(c), the
AU-ROC measurements from M1 and M2 increased. Particularly,
the M2’s AU-ROC measurements were greater than 0.99 at predict-
ing all classes. This again signifies that Model M2(HYP_PCA) had
nearly perfect capacity to detect all structural surface objects. The
comparative tests herein provide the direct evidence that performing
dimensionality reduction over hyperspectral profiles (i.e., as HYP
feature vectors) substantially can unleash the embedded discrimina-
tion capacity of the data that otherwise is not exploitable.
A secondary yet important research problem in this work was
to prove the competitiveness of low spatial-resolution hyperspec-
tral data compared with high-resolution gray-intensity images in
detecting material surface objects. For this purpose, the results
of M2(HYP_PCA) and M3(GL_HOG) were evaluated and com-
pared. The F1 scores and the AU-ROC measurements shown in
Figs. 7(a–d), respectively, clearly indicate that in the prediction of
all class labels, M2(HYP_PCA) superseded M3(GL_HOG). Even
considering the fourth model, M4, to be evaluated, M2(HYP_PCA)
was the best model in Test 3. This model provided outstanding
performance; the smallest F1 score was 0.757, and the smallest
AU-ROC measurement was 0.985, both for predicting dry vegeta-
tion; for crack prediction, F1 ¼ 0.917 and AU-ROC ¼ 0.995. The
control model in this test, M3(GL_HOG), had F1 ¼ 0.354 and
AU-ROC ¼ 0.898 for dry vegetation, and AU-ROC ¼ 0.774, and
F1 ¼ 0.292 for cracks.
To further visualize the prediction capacity and the stability of
the two most important models in this work, M2(HYP_PCA) and
M3(GL_HOG), the ROC curves are illustrated in Figs. 8(a and b)
for the two models, respectively, based on Test 3 data. Similarly,
Figs. 9(a and b) report the PR curves. The two ROC and PR curves
show the different prediction capacity for each class label as the
underlying classification threshold changed. The ROC and PR
curves show that Model M2(HYP_PCA) had not only superb clas-
sification capability but also stronger stability, the latter of which is
indicated by the smoothness of the curves as the underlying thresh-
old varies. In the case of M3(GL_HOG), the classification capabil-
ity (and accuracy) overall was much moderate; the stability also
was worse.
For Objective 4, the authors evaluated a simple data fusion
technique, which joined the two feature types, HYP_PCA and
GL_HOG, and observed the possible performance gain or loss.
(a) (b)
(c) (d)
Fig. 7. Model performance: (a) F1 score with Test 1 data; (b) F1 score with Test 3 data; (c) AU-ROC with Test 1 data; and (d) AU-ROC with
Test 3 data.
© ASCE 04020057-12 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2021, 35(1): 04020057
Downloaded
from
ascelibrary.org
by
University
of
Liverpool
on
11/14/20.
Copyright
ASCE.
For
personal
use
only;
all
rights
reserved.](https://image.slidesharecdn.com/aryal-220629012212-d6bf204a/75/Aryal-pdf-12-2048.jpg)


























































