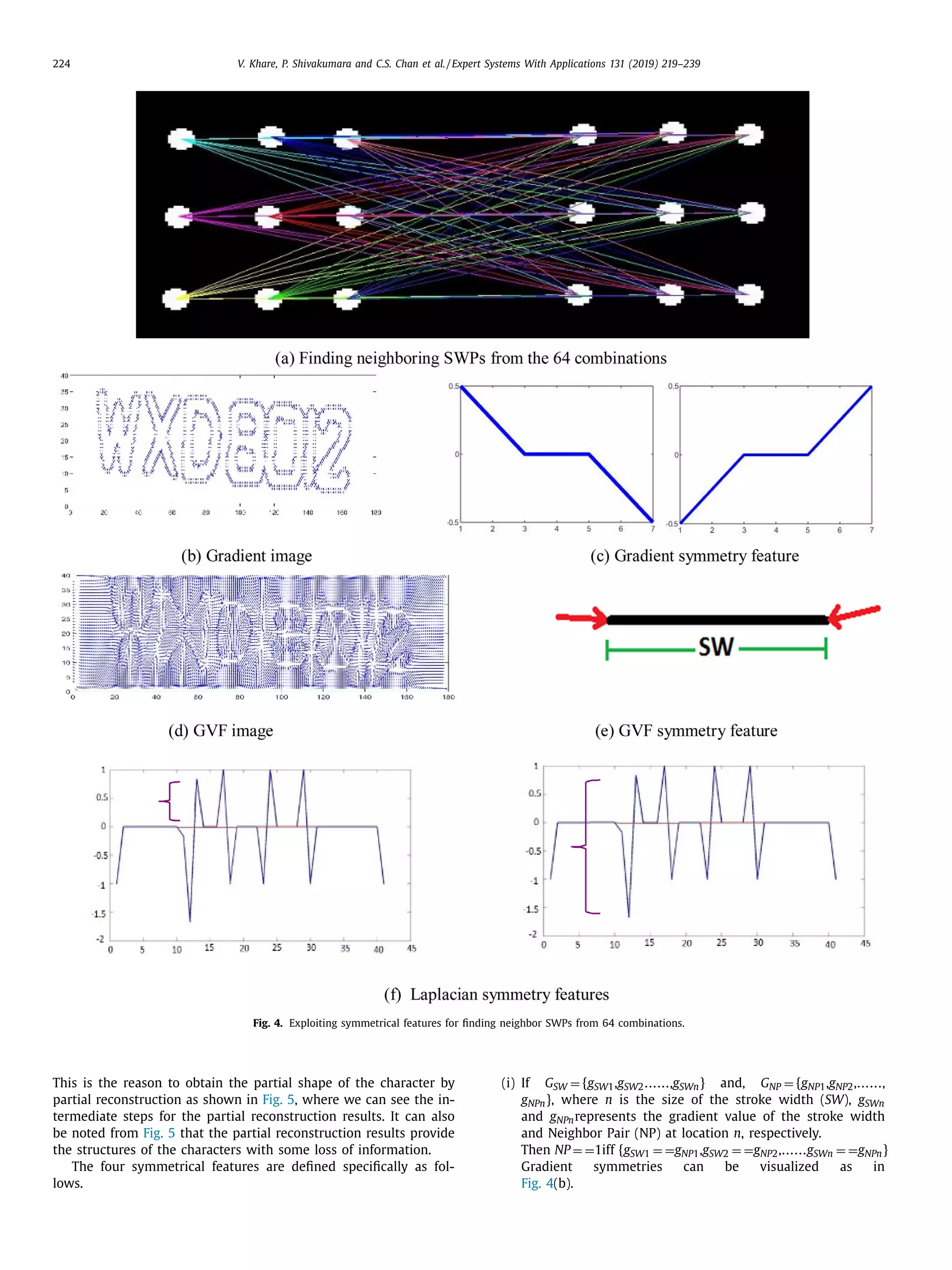
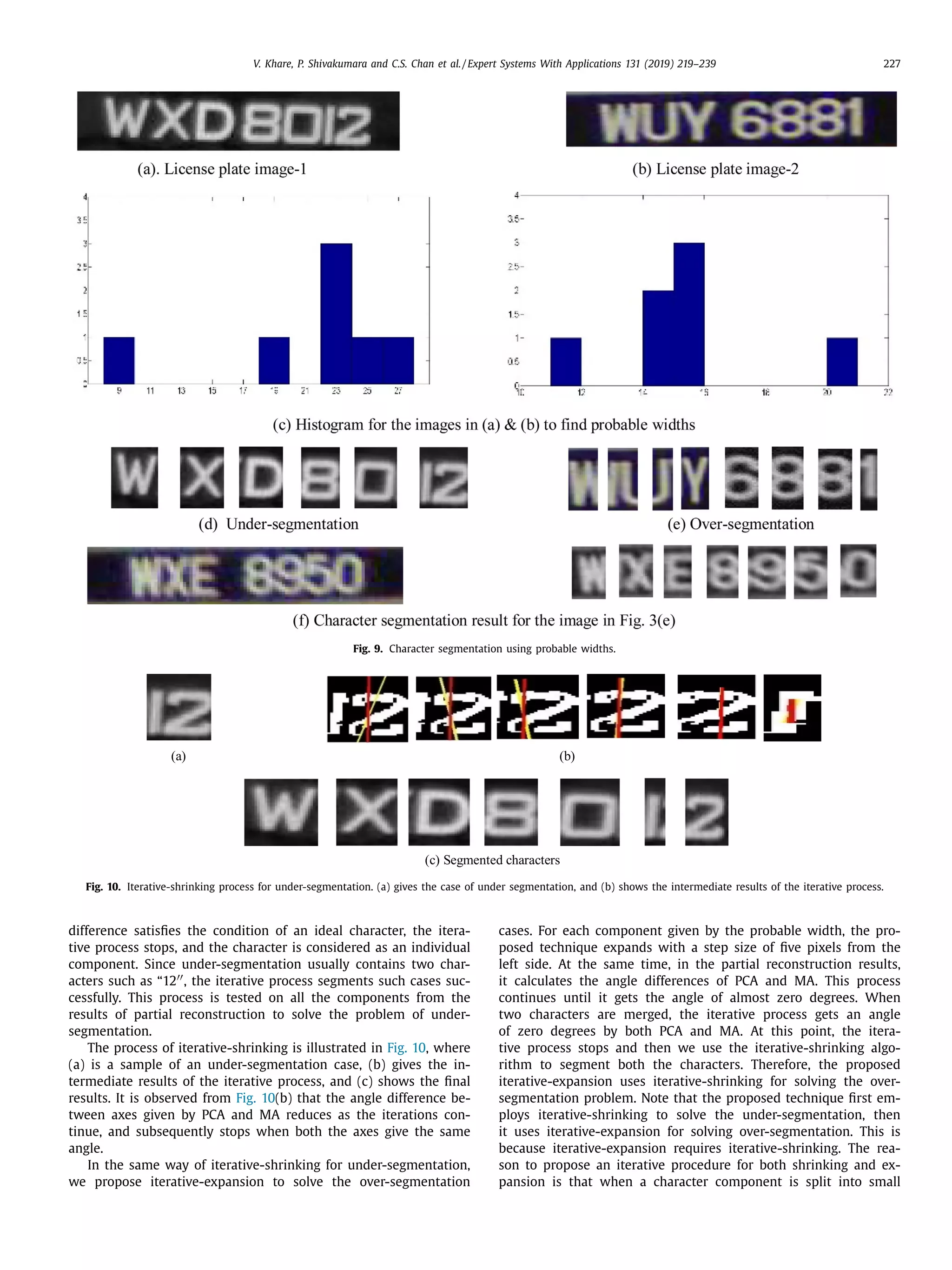
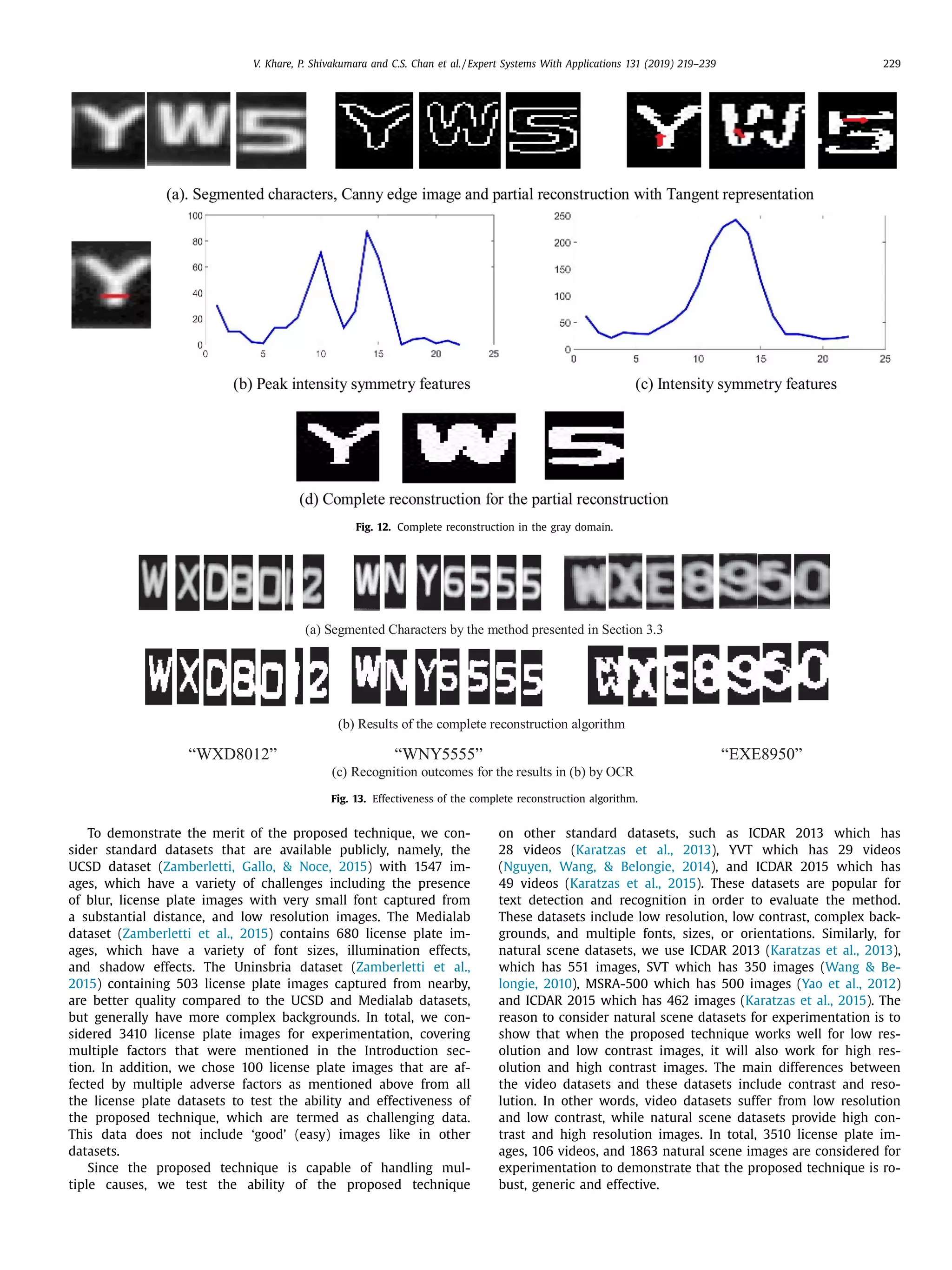
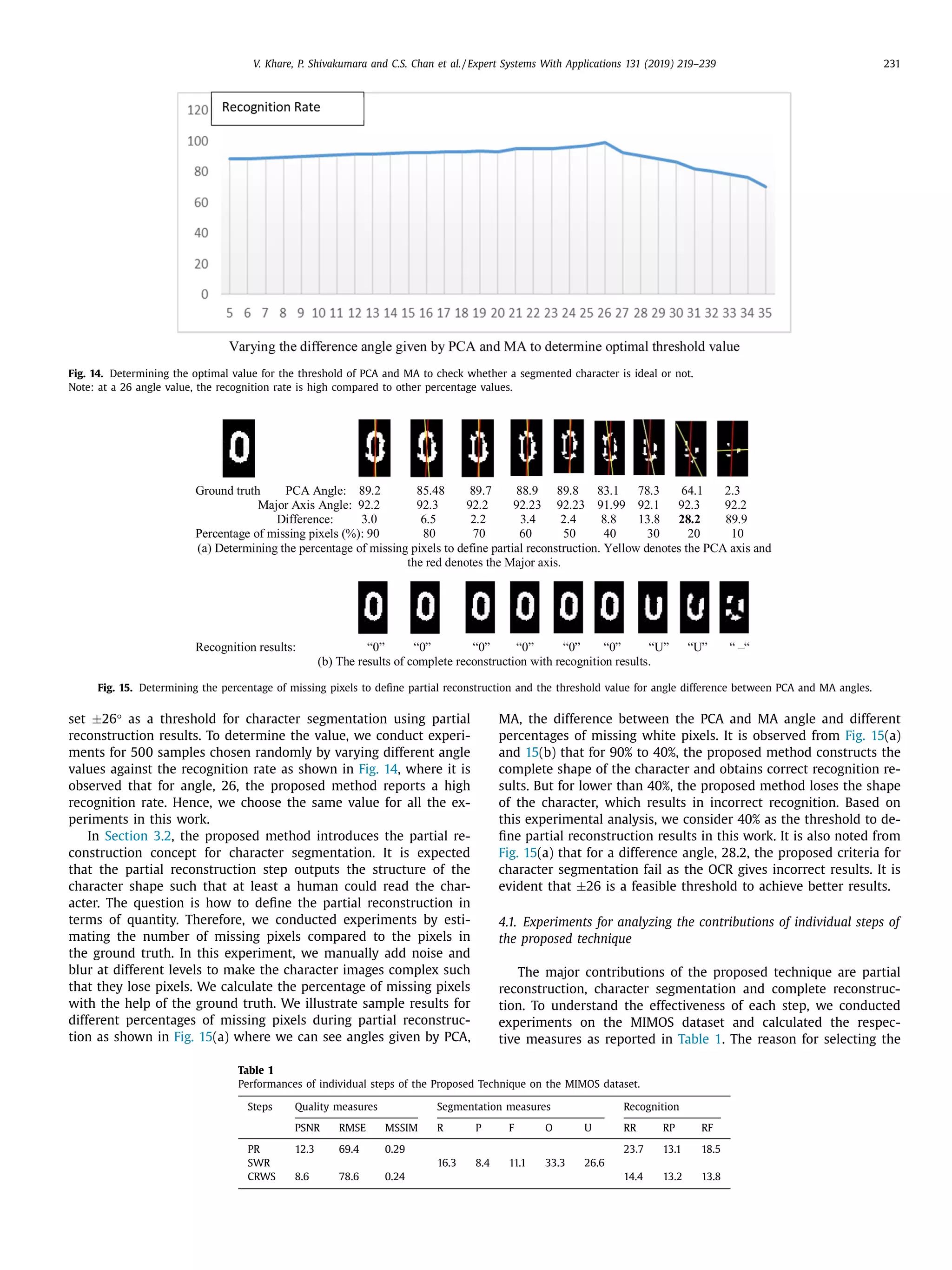
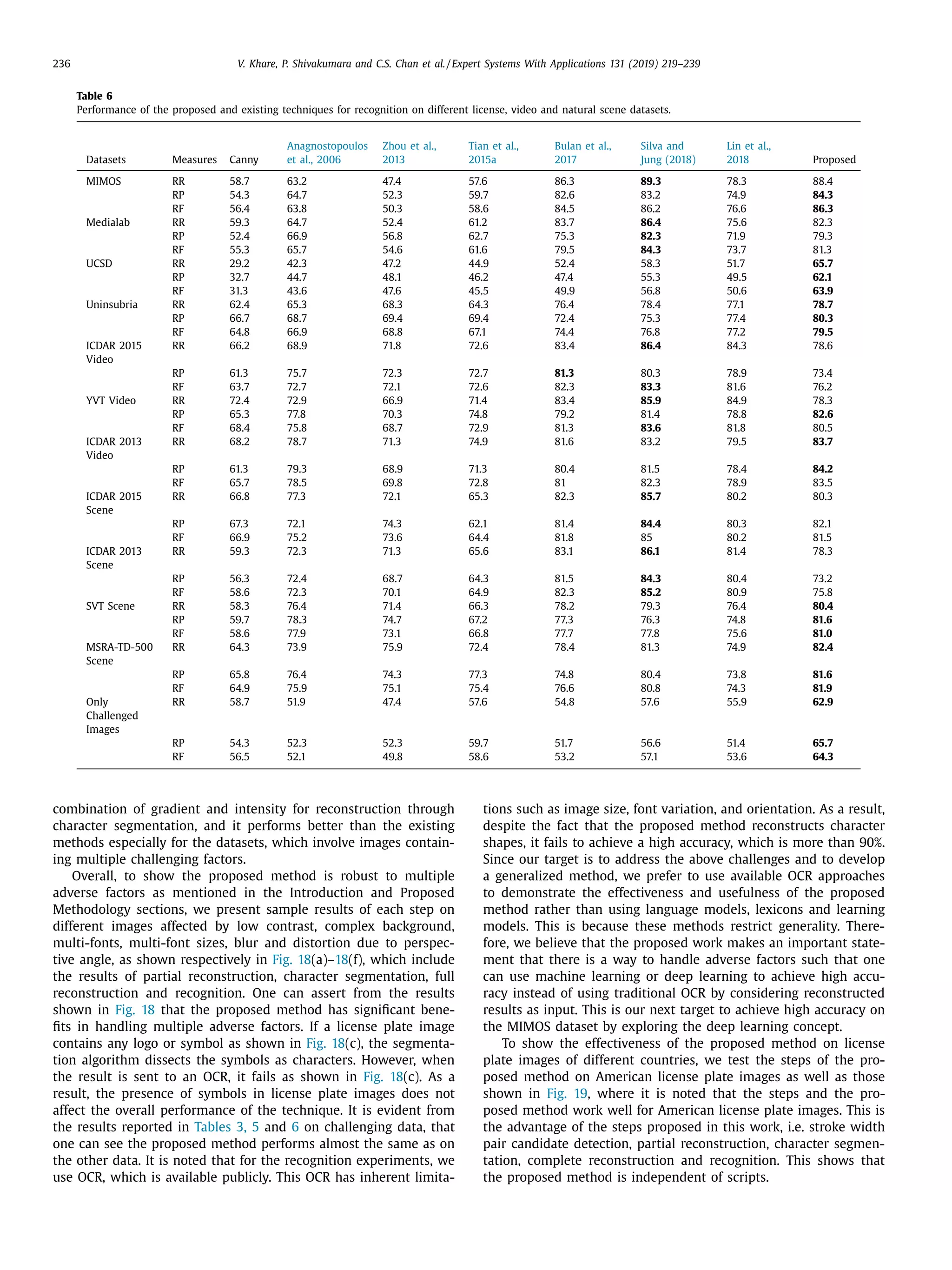
The document discusses a novel approach for license plate recognition that involves character segmentation through partial reconstruction and complete reconstruction for recognition. It aims to develop a system that can handle multiple adverse factors like low resolution, blurring, complex backgrounds, etc. that affect license plate images. The proposed approach uses characteristics of stroke width in the Laplacian and gradient domain to segment character components with incomplete shapes. It then studies the angular information and aspect ratios of character components to further segment characters. Finally, it uses the same stroke width properties to reconstruct the complete shape of each character for improved recognition rates. Experimental results on several benchmark and real-world databases demonstrate the effectiveness of the proposed technique.



















































































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)








