Download to read offline

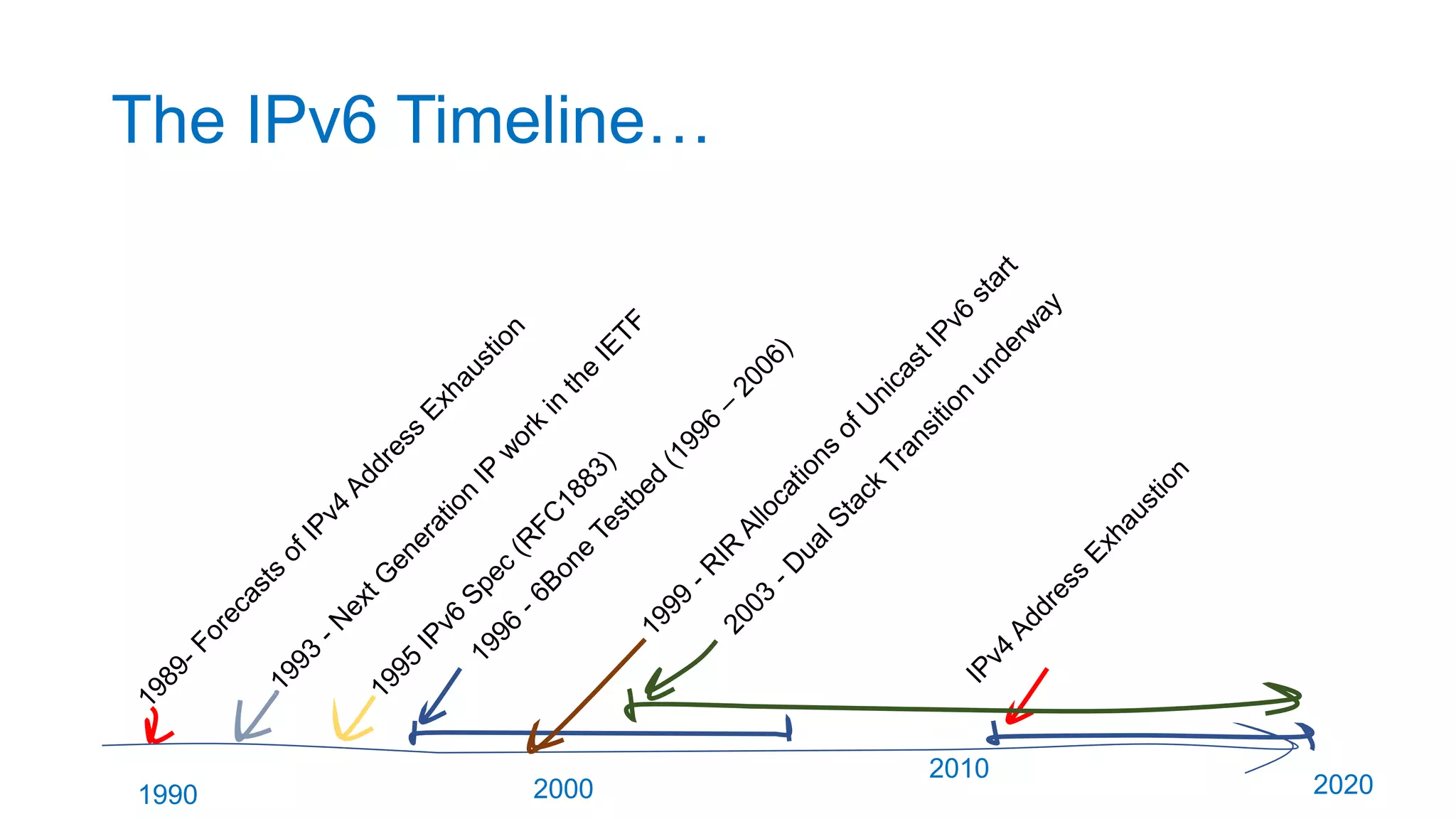
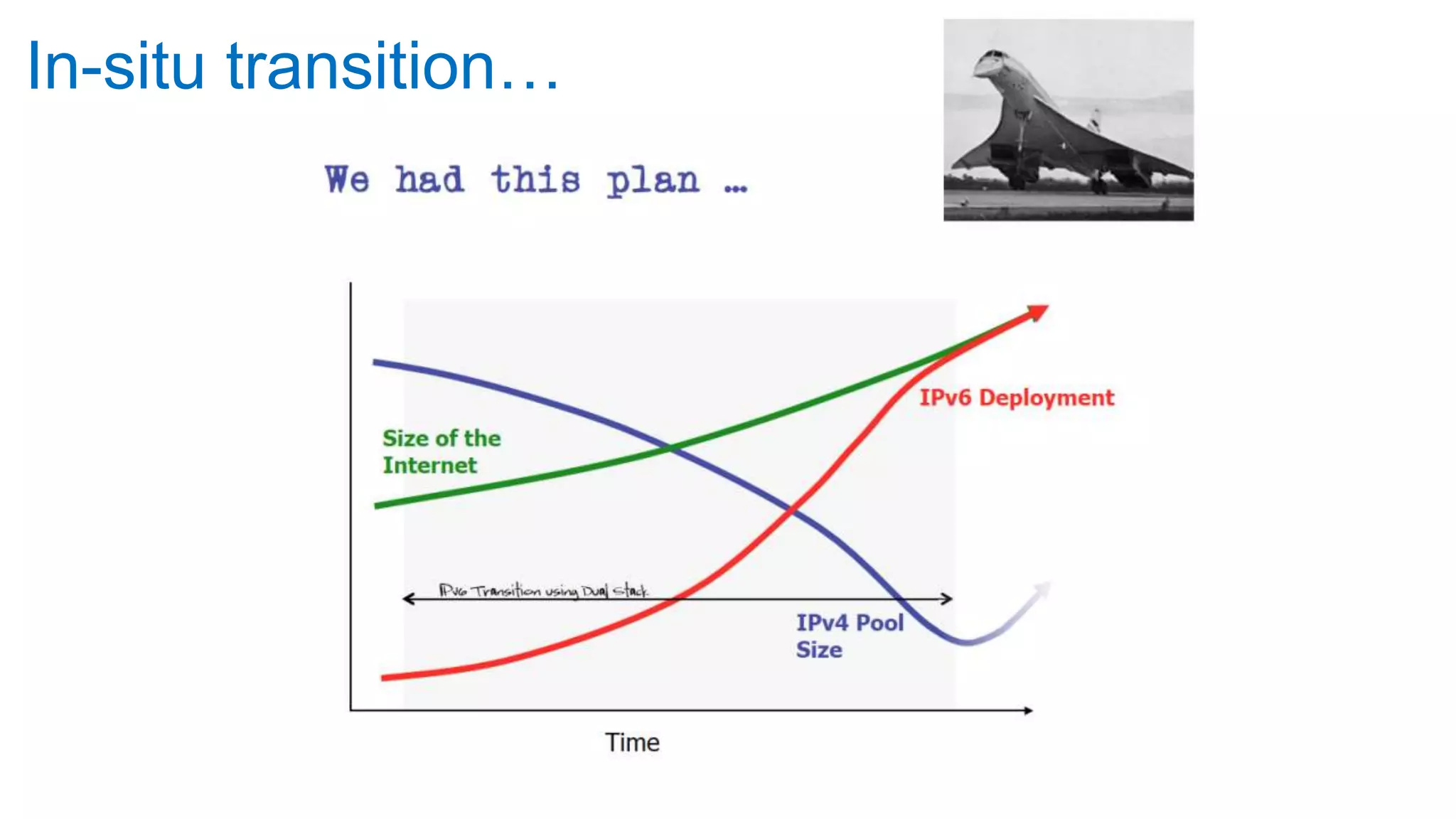
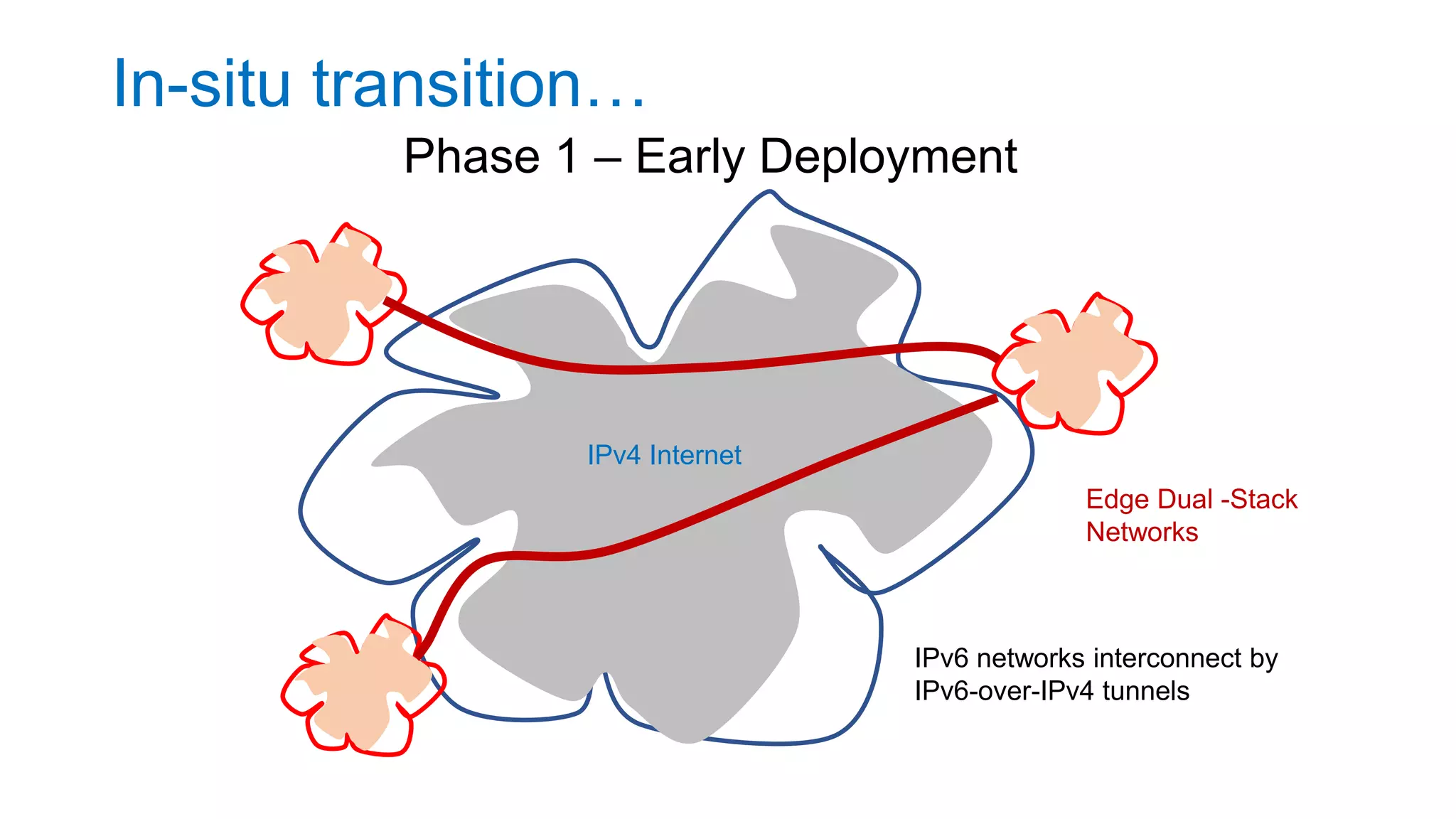
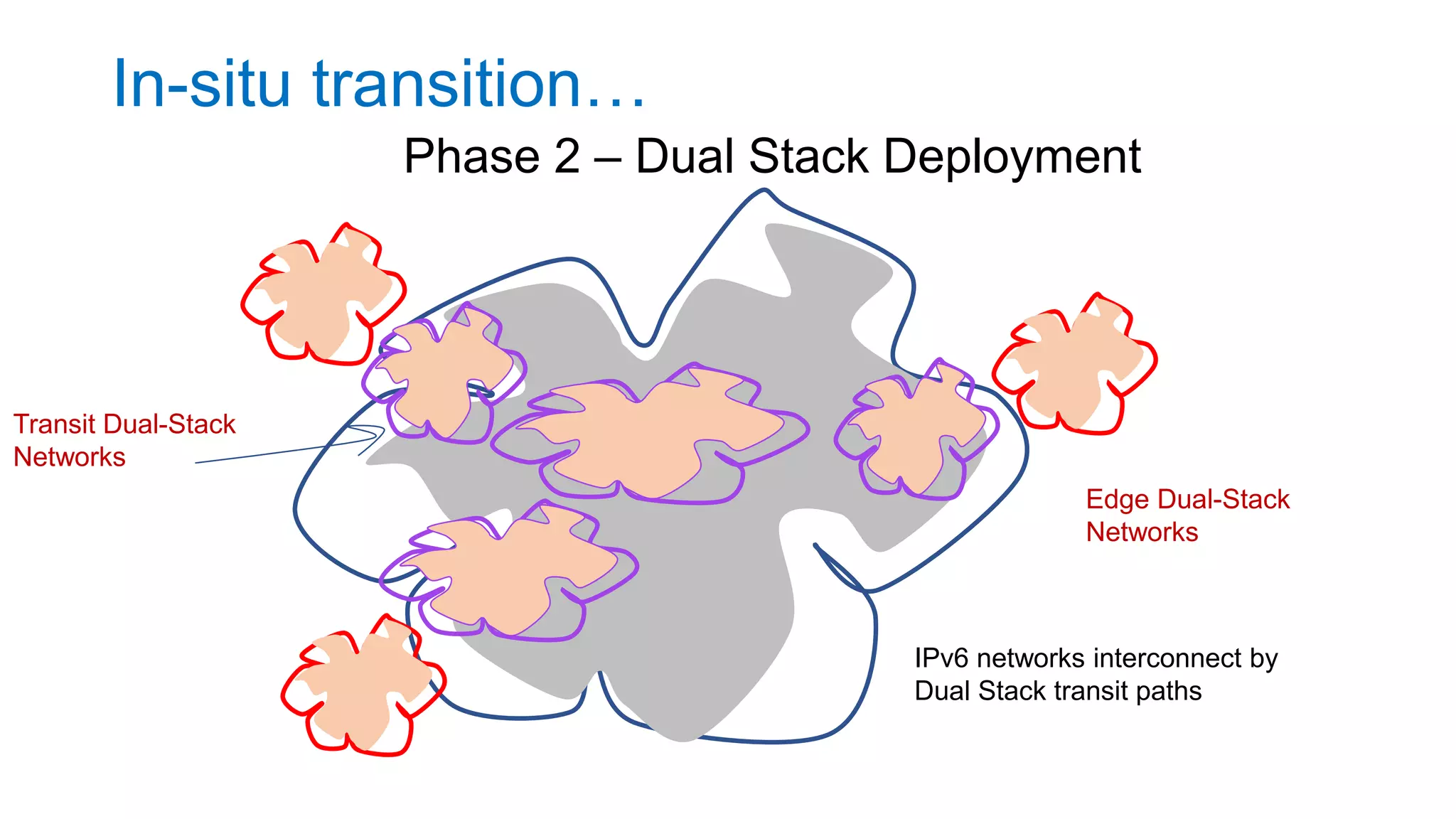
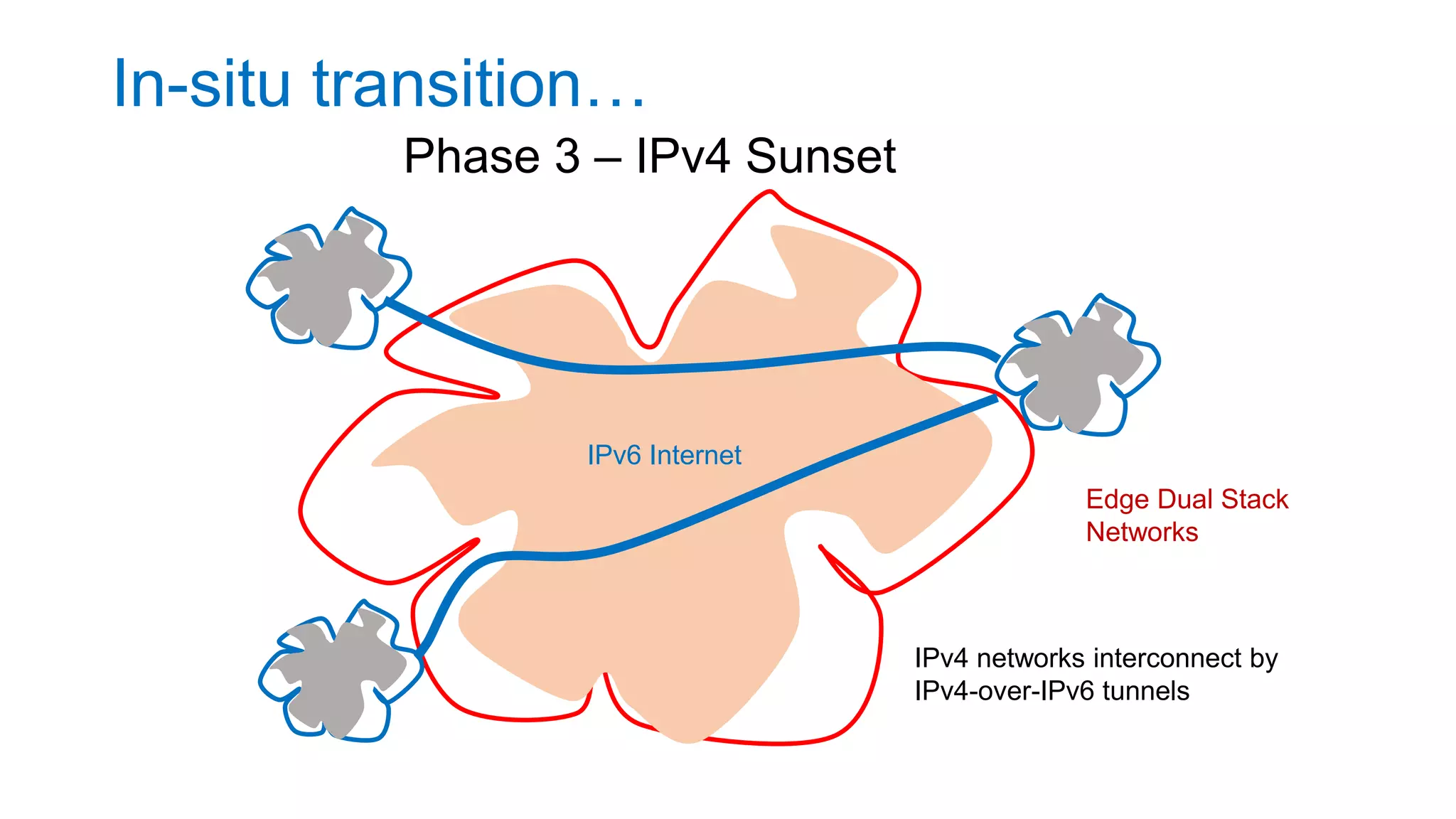
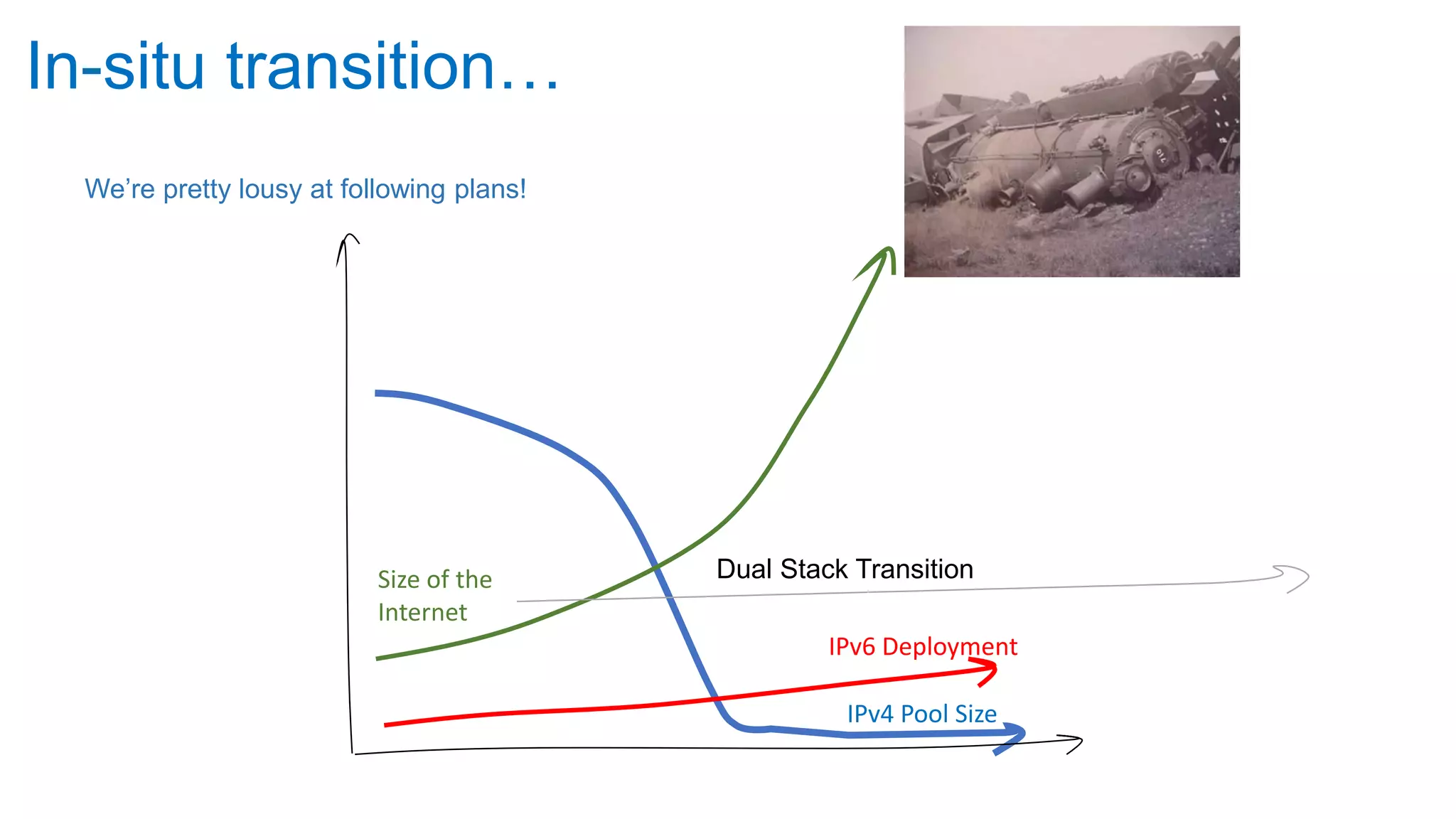
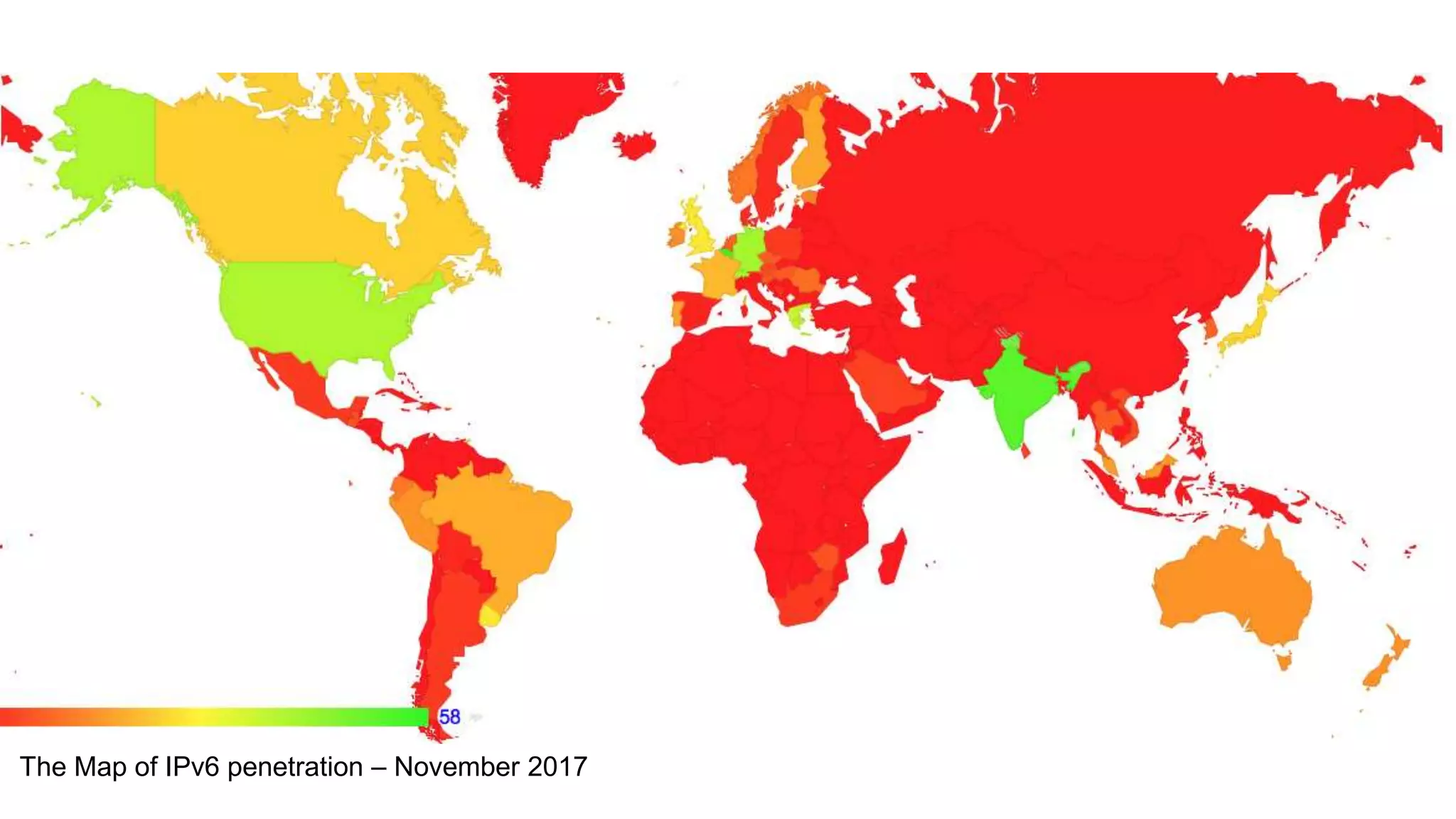
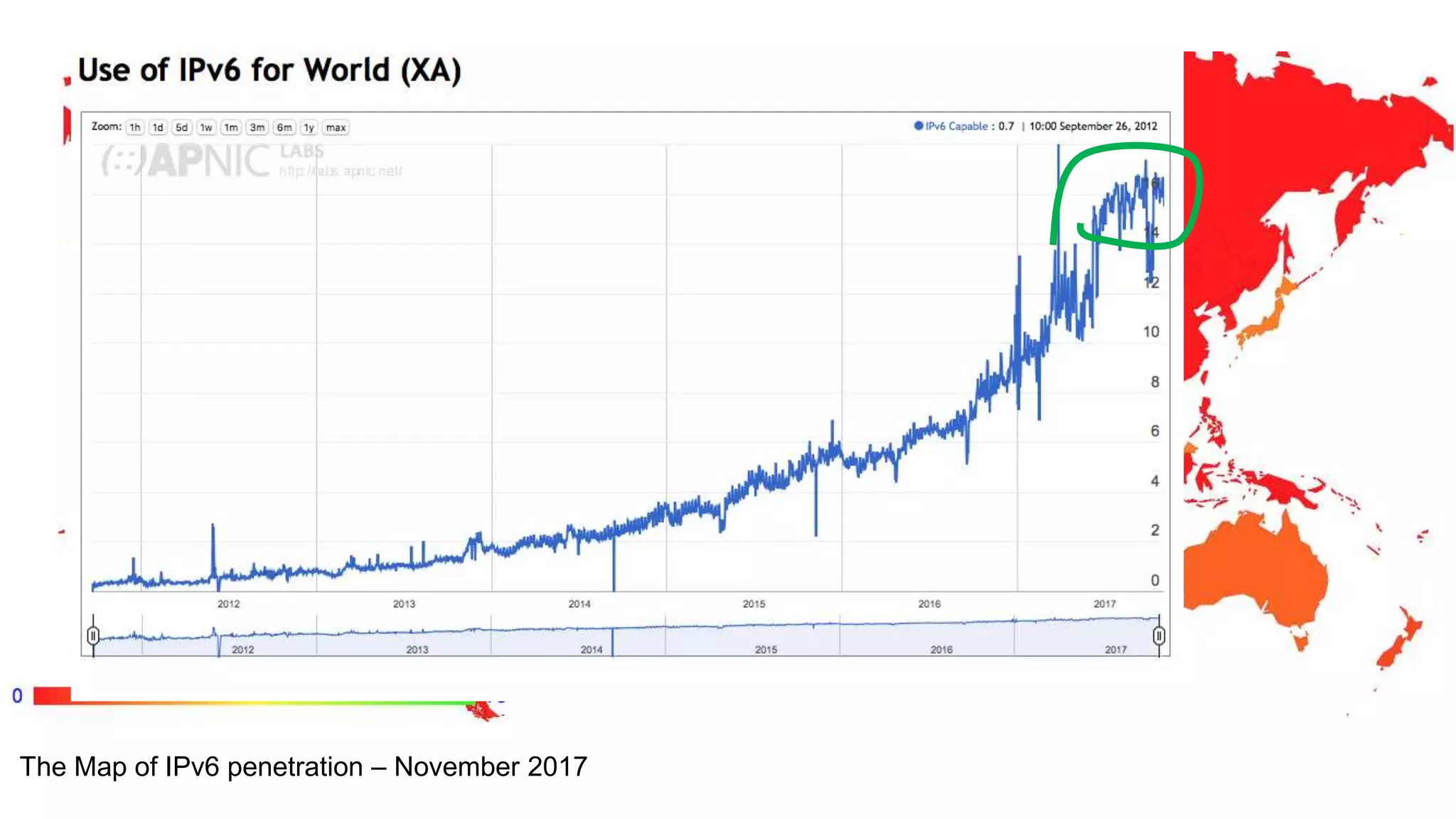







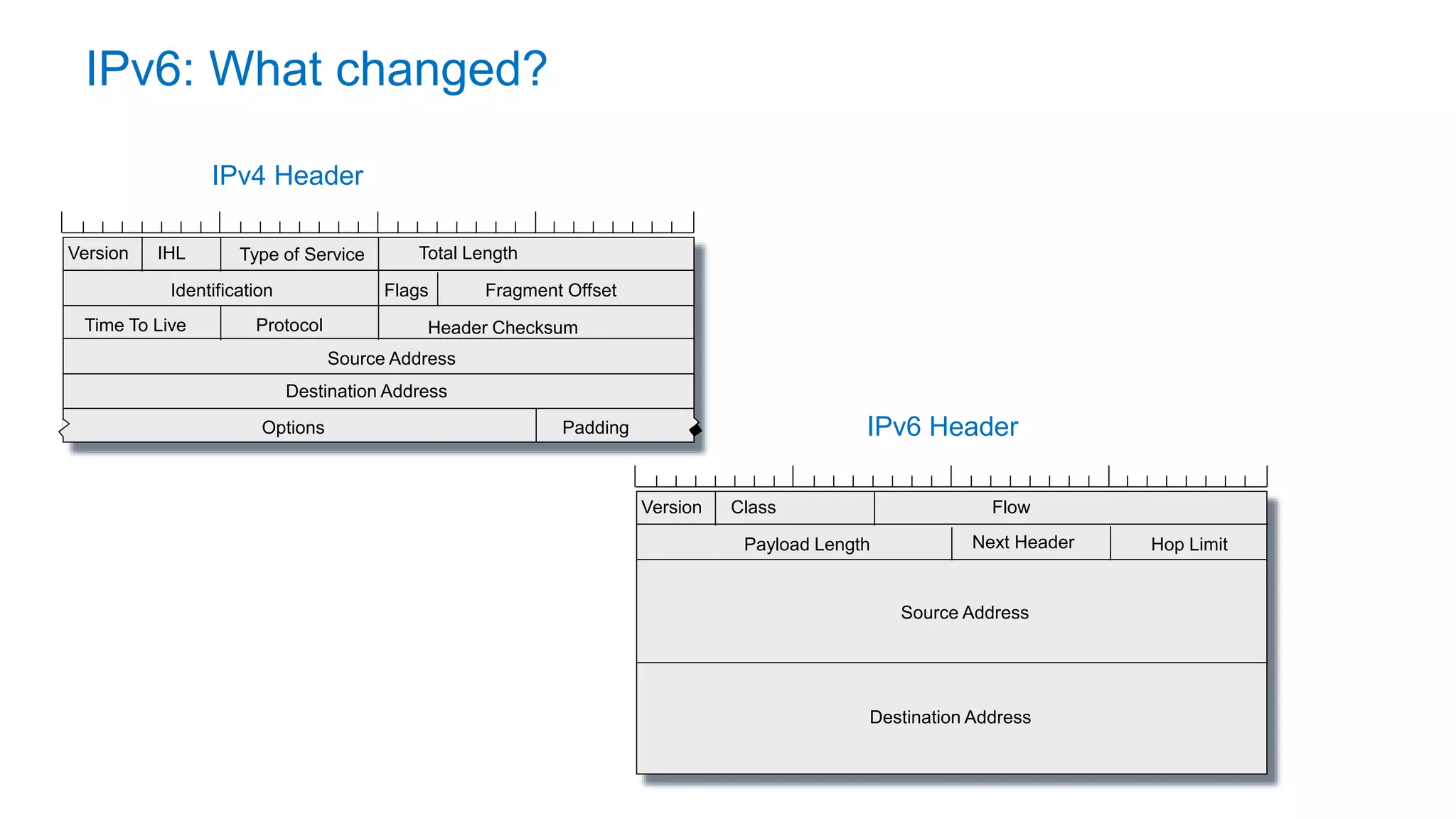

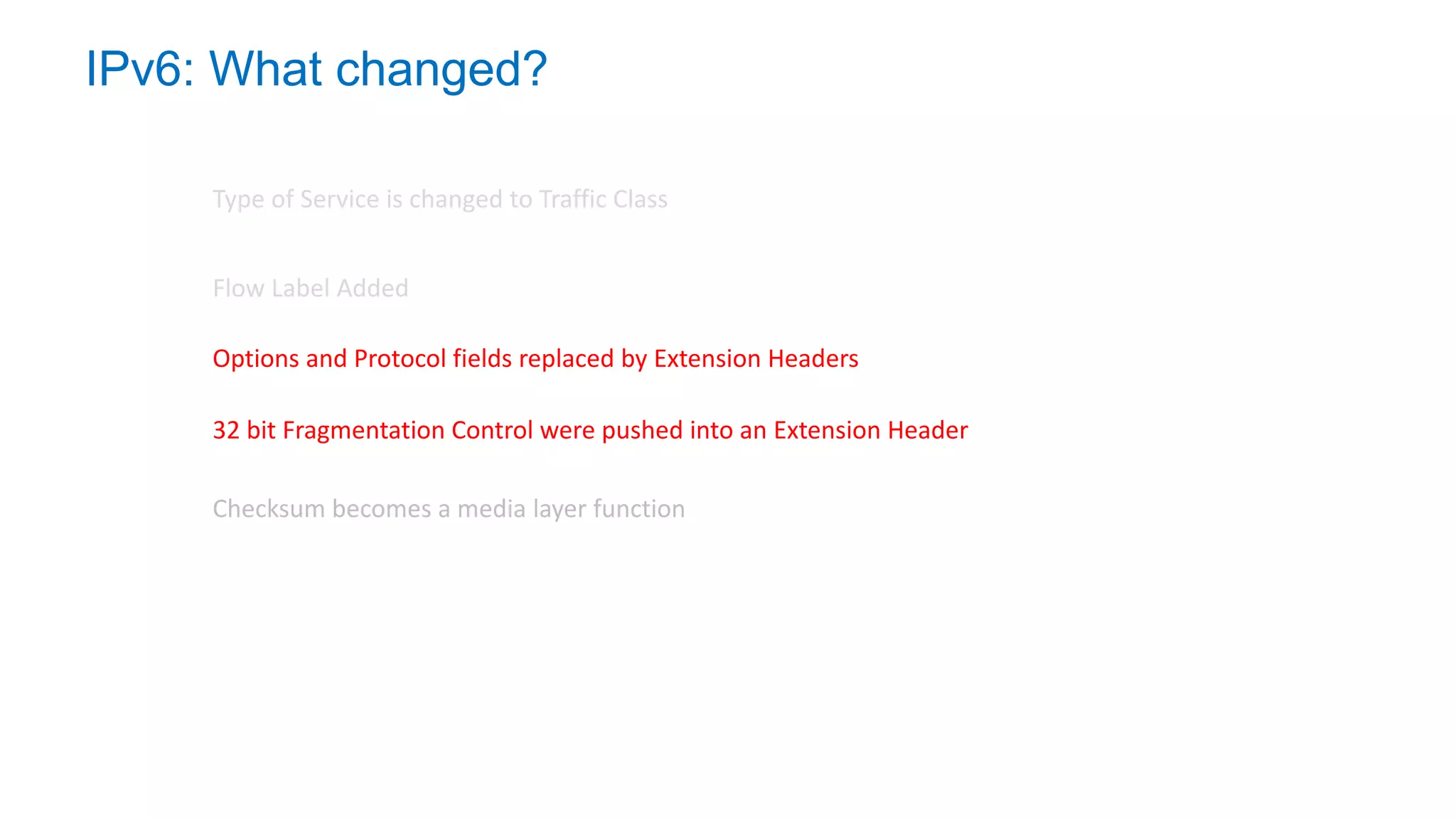

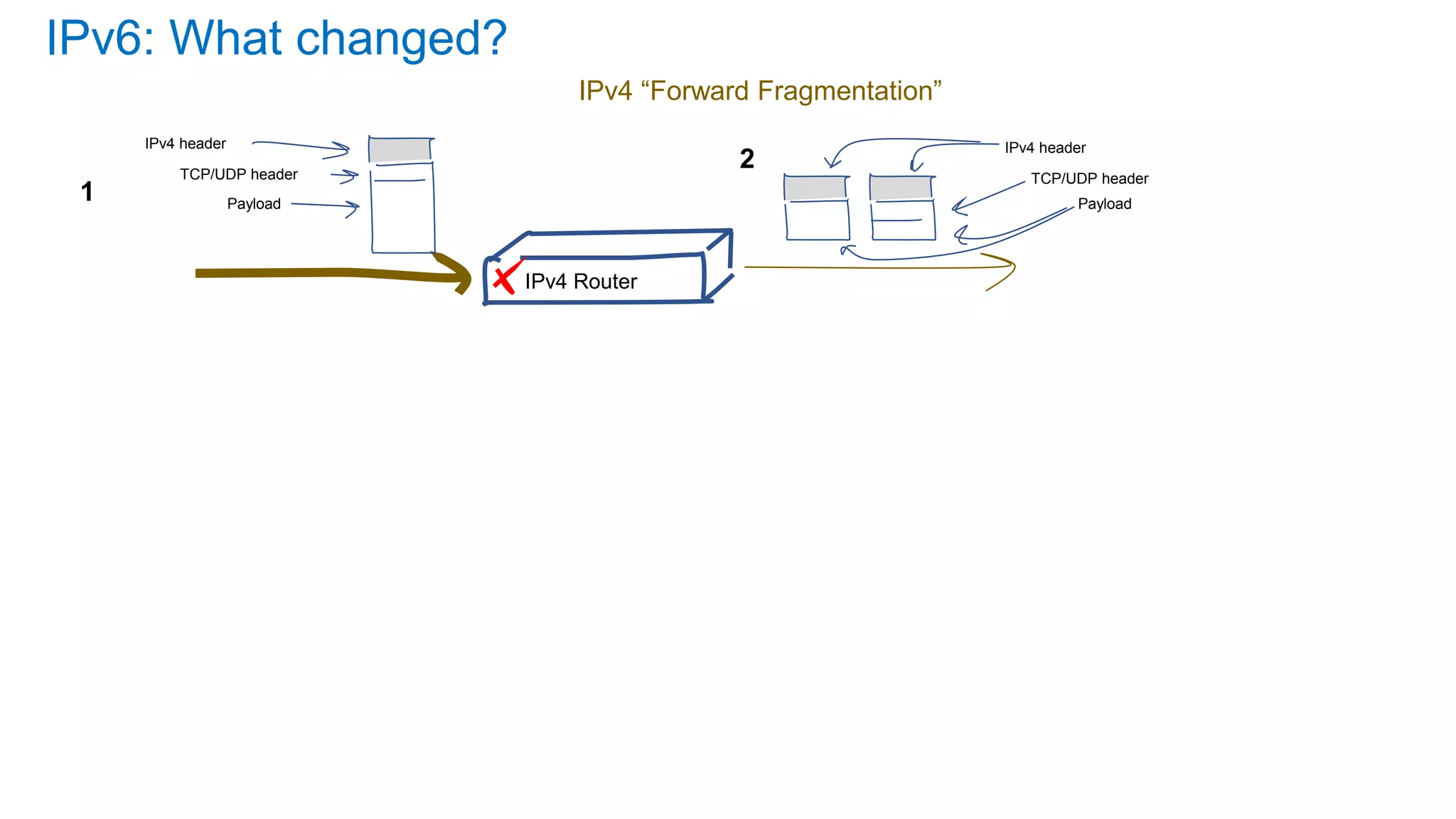
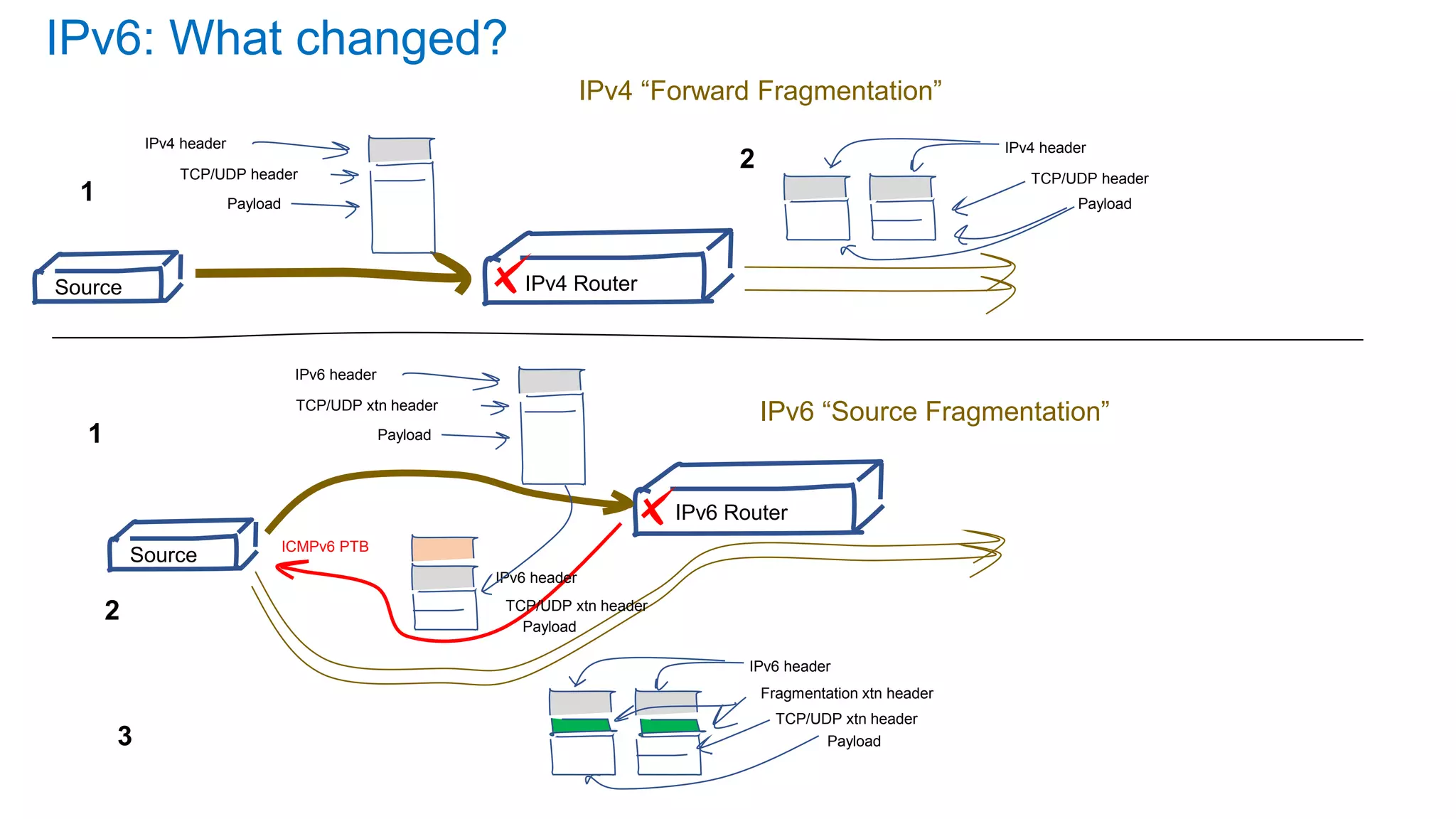
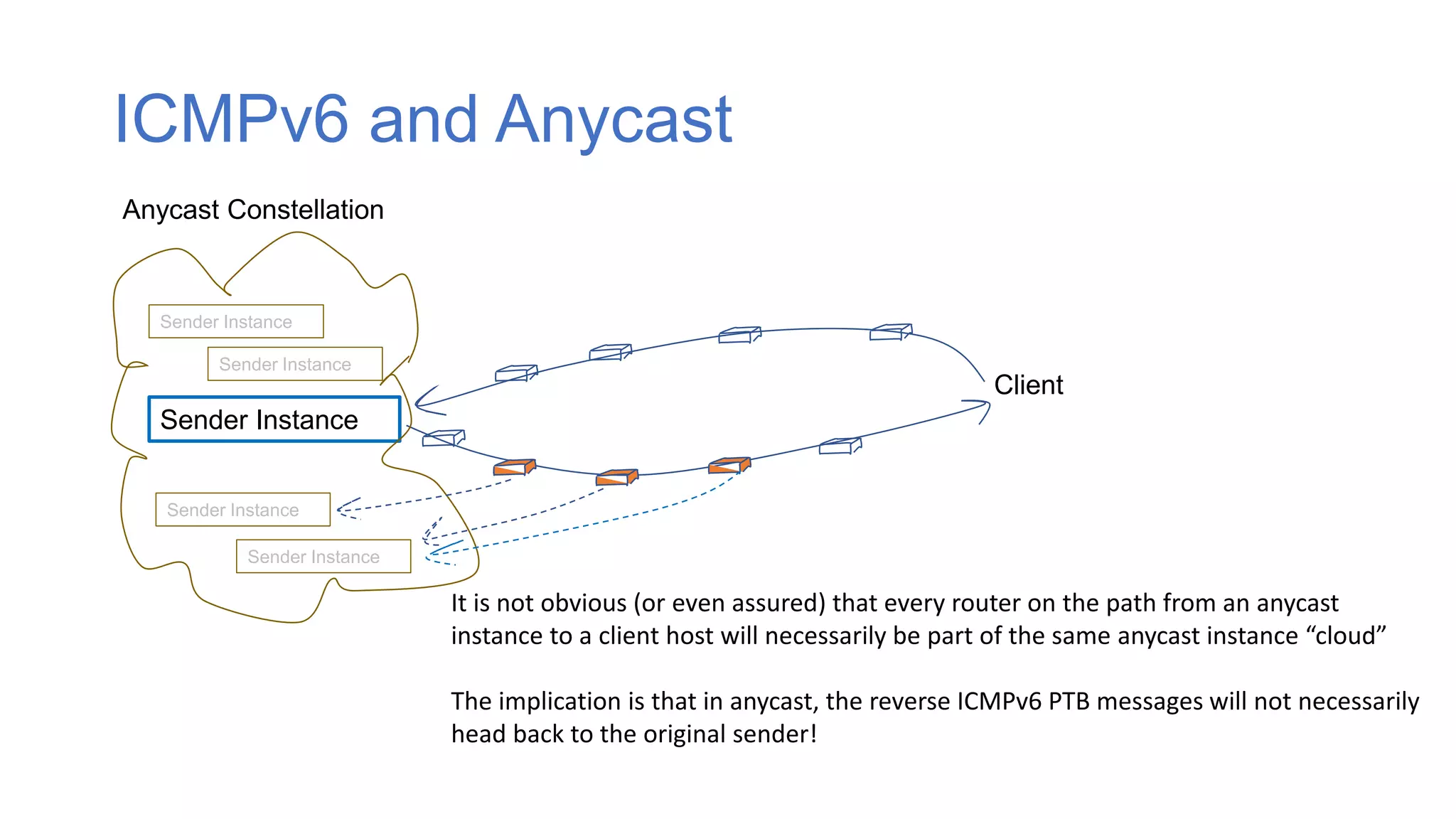

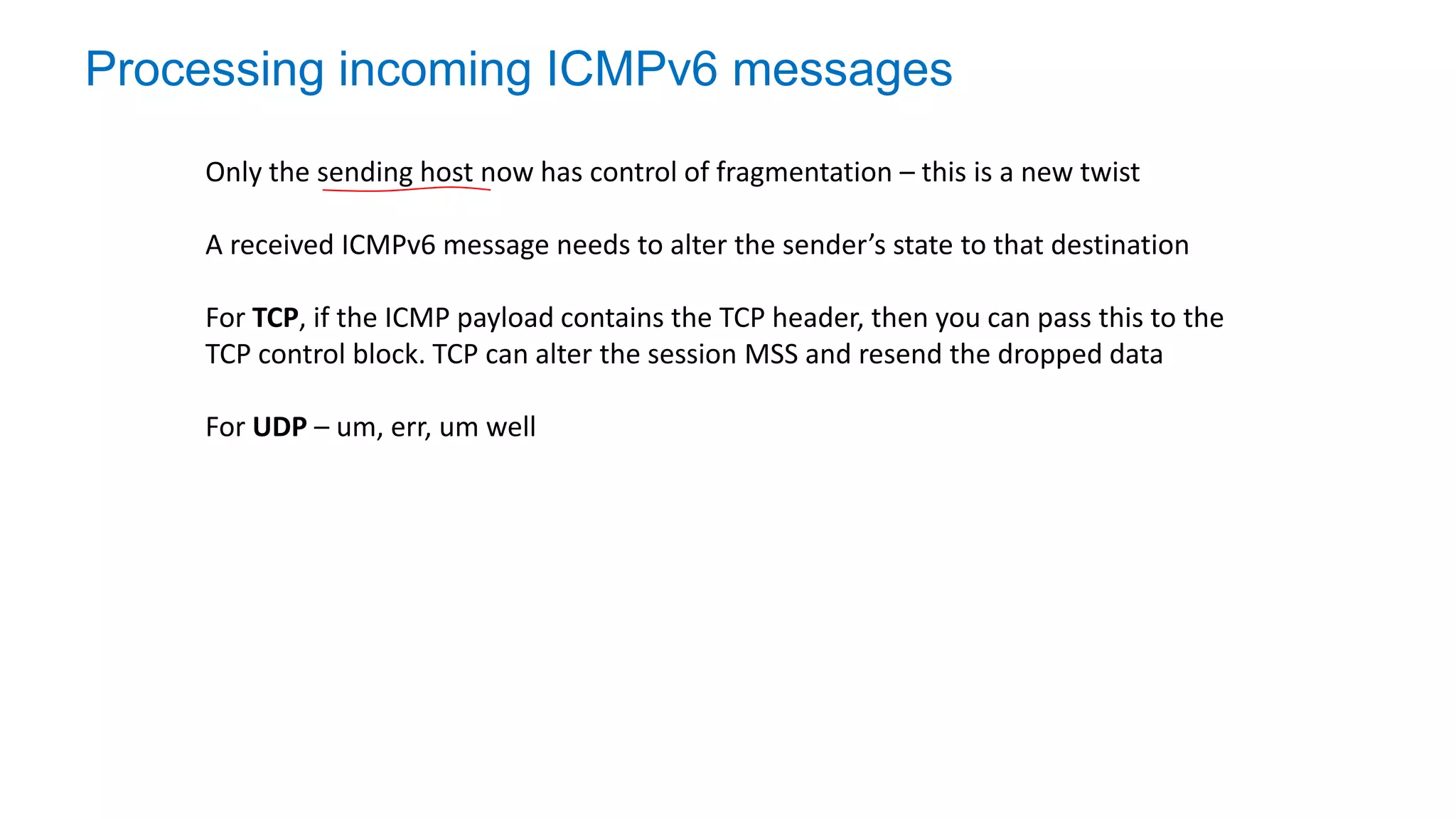




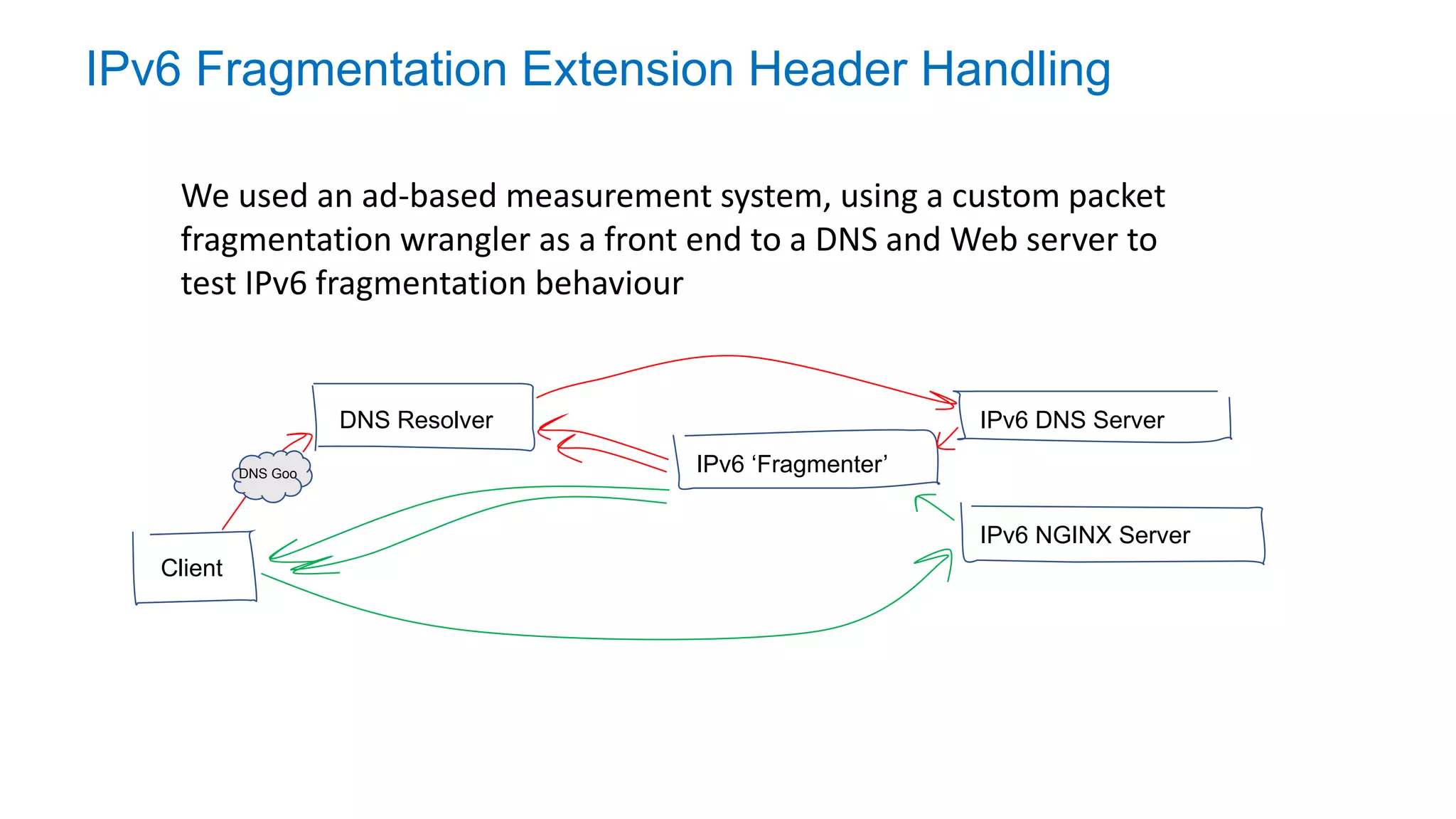






























The document discusses the challenges and current state of transitioning from IPv4 to IPv6, indicating that the internet is largely still reliant on IPv4 and is stuck in phase 2 of adoption. It outlines technical issues, particularly flaws in IPv6 fragmentation that lead to a significant drop rate, raising concerns about the viability of IPv6-only networks. Ultimately, the document concludes that the infrastructure and protocols necessary for a fully functional IPv6 internet are not yet in place, particularly regarding DNS functionality.







































































![Computer Networks 01[1 using all terms].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computernetworks011-251214040533-327dd9f8-thumbnail.jpg?width=640&height=640&fit=bounds)















