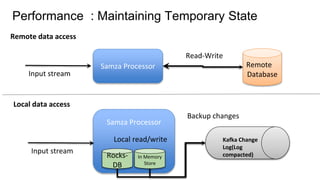
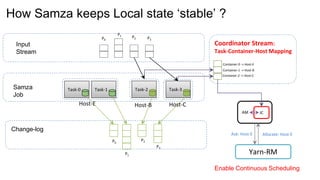
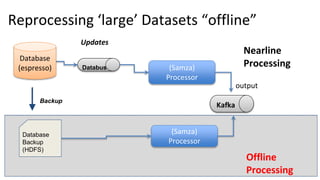
The document provides an overview of Apache Samza, including its key differentiators and future plans. It discusses Samza's performance advantages from using local state instead of remote databases. Samza allows stateful stream processing and incremental checkpointing for applications with terabytes of state. It supports a variety of input sources, processing as a service on YARN or embedded as a library. Upcoming features include a high-level API, support for event time windows, pipelines, and exactly-once processing while auto-scaling local state.