Download as PDF, PPTX







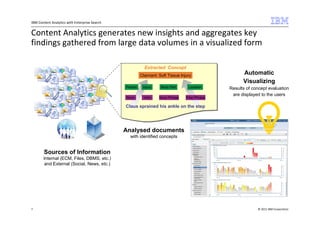




The document outlines IBM's commitment to open source and the integration of Apache Lucene within its Content Analytics and Enterprise Search offerings. It highlights IBM's contributions to the Apache community and showcases the capabilities of its analytics tools in generating insights from large volumes of data, including a demonstration using automotive complaints from the NHTSA. Additionally, it mentions the successful launch of IBM's OmniFind Yahoo! edition as a no-cost entry-level enterprise search product.























































































