Download as PDF, PPTX





![5 | FluentD vs. Logstash: How to Decide
⬢ Adding to the challenge of scale, just the act of collecting logs can be tedious when dealing
with the reality of an enterprise application landscape devoid of standards
⬢ Some applications produce multi-line logs such as stack traces without clear delimiters
⬢ Attempts at standards have arisen, but these standards vary across languages – for instance
Java has log4j which formats differently than winston for Node.js
⬢ Bottom line, not all applications produce logs in the same format:
Challenges with Logging
2020-02-03 13:32:12 (info) [SalesCRM]
00230 Invalid password attempt for user
‘gmhopper’
2019-06-14T3:56:16.000+0000 [ERROR] AUTH:
(ServiceApp) Failed login attempt user
‘gmhopper’](https://image.slidesharecdn.com/fluentd-vs-logstash-211105183613/85/FluentD-vs-Logstash-5-320.jpg)




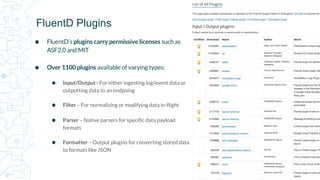









The document compares Fluentd and Logstash as solutions for enterprise log management, emphasizing the challenges of handling diverse log formats and the increasing volume of log data generated by modern applications. It highlights that while Logstash offers simpler architecture, Fluentd provides a more extensive plugin library and sophisticated routing capabilities, albeit with potentially more complex initial setup. The choice between the two ultimately depends on the specific needs and future direction of an enterprise's logging infrastructure.








![[WSO2Con EU 2018] Deploying Applications in K8S and Docker](https://cdn.slidesharecdn.com/ss_thumbnails/deployingapplicationsink8sanddocker-wso2conusa2018-181114045319-thumbnail.jpg?width=640&height=640&fit=bounds)














































































