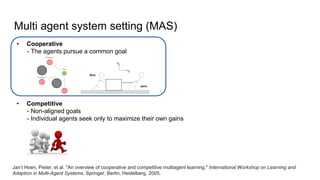
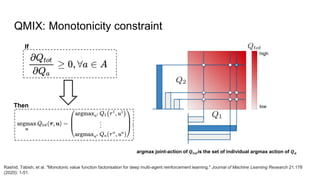
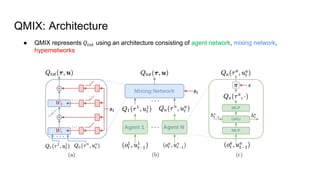
QMIX is a deep multi-agent reinforcement learning method that allows for centralized training with decentralized execution. It represents the joint action-value function as a factored and monotonic combination of individual agent value functions. This ensures greedy policies over the individual value functions correspond to greedy policies over the joint value function. Experiments in StarCraft II micromanagement tasks show QMIX outperforms independent learners and value decomposition networks by effectively learning cooperative behaviors while ensuring scalability.



![CTDE Approach
Independent Q learning
(IQL) [Tan 1993]
Counterfactual multi-agent policy gradient
(COMA) [Foerster 2018]
Value Decomposition network
(VDN) [Sunehg 2017]
policy 1
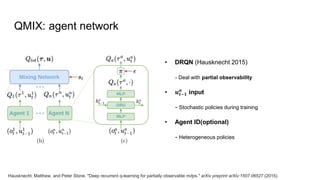
𝑸𝒕𝒐𝒕
policy 2 policy 3
How to learn action-value function 𝑸𝒕𝒐𝒕 and extract decentralized policy?
𝑸𝒕𝒐𝒕
Qa1
Qa2
Qa3
+
+
policy 3
𝑸𝒂𝟑
Greedy
policy 2
𝑸𝒂𝟐
Greedy
policy 1
𝑸𝒂𝟏
Greedy
Learn independent individual action-value function
policy 1
policy 2
policy 3
+ Simplest Option
+ Learn decentralized policy trivially
- Cannot handle non-stationary case
Learn centralized, but factored action-value function Learn centralized full state action-value function
+ Lean 𝑸𝒕𝒐𝒕 directly with actor-critic framework
- On policy: sample inefficient
- Less scalability
+ Lean 𝑸𝒕𝒐𝒕
+ Easy to extract decentralized policy
- Limited representation capacity
- Do not use additional global state information
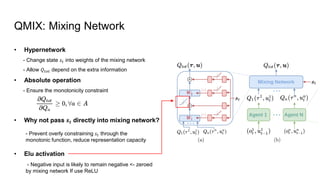
● Learn 𝑸𝒕𝒐𝒕 -
> figure out effectiveness of agent’s actions
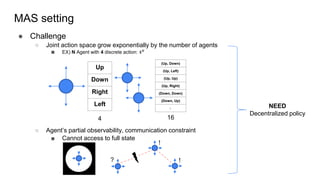
● Extract decentralized policy <- joint-action space growth problem, local observability, communication constraint
QMIX !
Other agents also learning and
change the strategies
-> no guarantee convergence](https://image.slidesharecdn.com/qmix-210429162704/85/QMIX-monotonic-value-function-factorization-paper-review-5-320.jpg)

![Background: Value decomposition
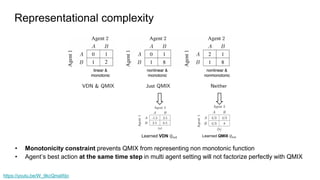
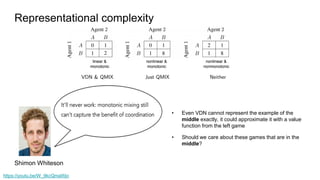
VDN full factorization
Utility function, not value function
Does not estimate an expected return
Guestrin, Carlos, Daphne Koller, and Ronald Parr. "Multiagent Planning with Factored MDPs." NIPS. Vol. 1. 2001.
Sunehag, Peter, et al. "Value-decomposition networks for cooperative multi-agent learning." arXiv preprint arXiv:1706.05296 (2017).
Factored joint value function [Guestrin 2001]
Subset of the agents
Factored value function reduce the parameters that have to be learned
https://youtu.be/W_9kcQmaWjo
Improve scalability](https://image.slidesharecdn.com/qmix-210429162704/85/QMIX-monotonic-value-function-factorization-paper-review-7-320.jpg)




![Experiment: SC2
• Observation (Sight range)
- distance
- relative x, y
- unit_type
• Action
- move[direction]
- attack[enemy_id] (Shooting range)
- stop
- noop
• Reward
- joint reward: total damage (each time step)
- bonus1 : 10 (killing each opponent)
- bonus2 : 100 (killing all opponent)
enemy
• Global state (hidden from agents)
(distance from center, health, shield, cooldown, last action)](https://image.slidesharecdn.com/qmix-210429162704/85/QMIX-monotonic-value-function-factorization-paper-review-19-320.jpg)




























![[Phd Thesis Defense] CHAMELEON: A Deep Learning Meta-Architecture for News Re...](https://cdn.slidesharecdn.com/ss_thumbnails/chameleondefesadoutorado1-191209202516-thumbnail.jpg?width=640&height=640&fit=bounds)








































