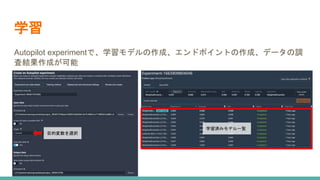
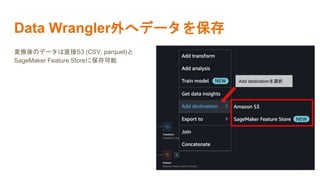
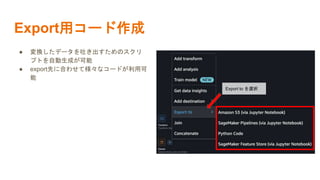
機械学習の社会実装勉強会第15回の発表で利用した資料です。 https://machine-learning-workshop.connpass.com/event/258733/ 動画はこちら https://youtu.be/0CL94gXWyAc









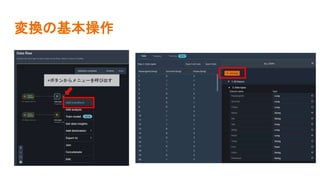
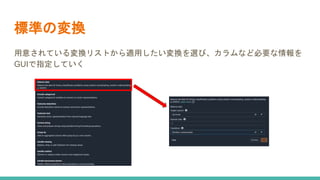


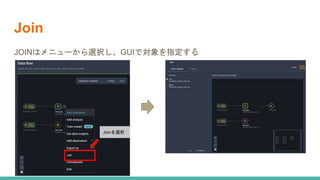
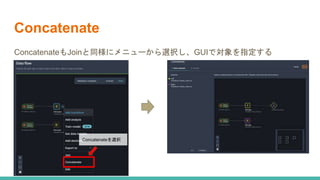













![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[CTO Night & Day 2019] ML services: MLOps #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessionml-191027185903-thumbnail.jpg?width=640&height=640&fit=bounds)





























