Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
西岡 賢一郎
PPTX, PDF
127 views
Amazon SageMaker Foundation Modelsで事前学習済みモデルを利用する
機械学習の社会実装勉強会第21回 (https://machine-learning-workshop.connpass.com/event/275945/) の発表の資料です。
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 18
2
/ 18
3
/ 18
4
/ 18
5
/ 18
6
/ 18
7
/ 18
8
/ 18
9
/ 18
10
/ 18
11
/ 18
12
/ 18
13
/ 18
14
/ 18
15
/ 18
16
/ 18
17
/ 18
18
/ 18
More Related Content
PPTX
Amazon SageMaker JumpStart
by
西岡 賢一郎
PPTX
機械学習用のデータを準備する Amazon SageMaker Data Wrangler - ノーコードで前処理から学習まで
by
西岡 賢一郎
PPTX
機械学習プラットフォーム5つの課題とAmazon SageMakerの4つの利点
by
西岡 賢一郎
PPTX
機械学習の社会実装勉強会 - データサイエンスチームをつくる
by
西岡 賢一郎
PDF
[CTO Night & Day 2019] ML services: MLOps #ctonight
by
Amazon Web Services Japan
PPTX
MLOps NYC 2019 and Strata Data Conference NY 2019 report nttdata
by
NTT DATA Technology & Innovation
PPTX
Amazon SageMakerを使った機械学習モデル管理運用システム構築事例
by
Seongduk Cheon
PPTX
ML Ops NYC 19 & Strata Data Conference 2019 NewYork 注目セッションまとめ
by
Tetsutaro Watanabe
Amazon SageMaker JumpStart
by
西岡 賢一郎
機械学習用のデータを準備する Amazon SageMaker Data Wrangler - ノーコードで前処理から学習まで
by
西岡 賢一郎
機械学習プラットフォーム5つの課題とAmazon SageMakerの4つの利点
by
西岡 賢一郎
機械学習の社会実装勉強会 - データサイエンスチームをつくる
by
西岡 賢一郎
[CTO Night & Day 2019] ML services: MLOps #ctonight
by
Amazon Web Services Japan
MLOps NYC 2019 and Strata Data Conference NY 2019 report nttdata
by
NTT DATA Technology & Innovation
Amazon SageMakerを使った機械学習モデル管理運用システム構築事例
by
Seongduk Cheon
ML Ops NYC 19 & Strata Data Conference 2019 NewYork 注目セッションまとめ
by
Tetsutaro Watanabe
Similar to Amazon SageMaker Foundation Modelsで事前学習済みモデルを利用する
PPTX
Small Language Model Local Launch on AI Tour Tokyo
by
Takao Tetsuro
PDF
機械学習デザインパターンおよび機械学習システムの品質保証の取り組み
by
Hironori Washizaki
PPTX
数式がわからなくたってDeep Learningやってみたい!人集合- dots. DeepLearning部 発足!
by
Hideto Masuoka
PPTX
LF AI & DataでのOSS活動と、それを富士社内で活用する話 - LF AI & Data Japan RUG Kick Off
by
Kosaku Kimura
PPTX
Amazon SageMakerのNotebookからJobを作成する
by
西岡 賢一郎
PPTX
先駆者に学ぶ MLOpsの実際
by
Tetsutaro Watanabe
PDF
[Track3-1] ビジネスで役立つAIリテラシーから機械学習エンジニアリングまで実践形式で学ぶ課題解決型AI人材育成とは?〜国内最大AIコンペサイトの...
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
1028 TECH & BRIDGE MEETING
by
健司 亀本
PDF
『生成AIによるソフトウェア開発』(鷲崎弘宜, 鵜林尚靖, 中川尊雄, 増田航太, 徳本晋, 近藤将成, 石川冬樹, 竹之内啓太, 小川秀人, スマートエ...
by
Hironori Washizaki
PDF
LLM/生成AI&エージェントによるソフトウェア開発の実践と展望(SES2025チュートリアル)
by
Hironori Washizaki
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
PDF
Machine learning 15min TensorFlow hub
by
Junya Kamura
PPTX
ChatGPT Impact - その社会的/ビジネス価値を考える -
by
Daiyu Hatakeyama
PPTX
機械学習応用システムの開発技術 (機械学習工学) の現状と今後の展望
by
Nobukazu Yoshioka
PDF
SparkMLlibで始めるビッグデータを対象とした機械学習入門
by
Takeshi Mikami
PDF
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PPTX
未来のカタチ x AI
by
西岡 賢一郎
PPTX
機械学習応用のためのソフトウェアエンジニアリングパターン
by
HironoriTAKEUCHI1
PDF
Amazon SageMaker: 機械学習の民主化から工業化へ(in Japanese)
by
Toshihiko Yamakami
Small Language Model Local Launch on AI Tour Tokyo
by
Takao Tetsuro
機械学習デザインパターンおよび機械学習システムの品質保証の取り組み
by
Hironori Washizaki
数式がわからなくたってDeep Learningやってみたい!人集合- dots. DeepLearning部 発足!
by
Hideto Masuoka
LF AI & DataでのOSS活動と、それを富士社内で活用する話 - LF AI & Data Japan RUG Kick Off
by
Kosaku Kimura
Amazon SageMakerのNotebookからJobを作成する
by
西岡 賢一郎
先駆者に学ぶ MLOpsの実際
by
Tetsutaro Watanabe
[Track3-1] ビジネスで役立つAIリテラシーから機械学習エンジニアリングまで実践形式で学ぶ課題解決型AI人材育成とは?〜国内最大AIコンペサイトの...
by
Deep Learning Lab(ディープラーニング・ラボ)
1028 TECH & BRIDGE MEETING
by
健司 亀本
『生成AIによるソフトウェア開発』(鷲崎弘宜, 鵜林尚靖, 中川尊雄, 増田航太, 徳本晋, 近藤将成, 石川冬樹, 竹之内啓太, 小川秀人, スマートエ...
by
Hironori Washizaki
LLM/生成AI&エージェントによるソフトウェア開発の実践と展望(SES2025チュートリアル)
by
Hironori Washizaki
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
Machine learning 15min TensorFlow hub
by
Junya Kamura
ChatGPT Impact - その社会的/ビジネス価値を考える -
by
Daiyu Hatakeyama
機械学習応用システムの開発技術 (機械学習工学) の現状と今後の展望
by
Nobukazu Yoshioka
SparkMLlibで始めるビッグデータを対象とした機械学習入門
by
Takeshi Mikami
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
未来のカタチ x AI
by
西岡 賢一郎
機械学習応用のためのソフトウェアエンジニアリングパターン
by
HironoriTAKEUCHI1
Amazon SageMaker: 機械学習の民主化から工業化へ(in Japanese)
by
Toshihiko Yamakami
More from 西岡 賢一郎
PPTX
Amazon SageMaker Ground Truthを使って手動のラベル付けを簡略化する
by
西岡 賢一郎
PPTX
リモートワークで知っておきたい コミュニケーション時の過大な期待
by
西岡 賢一郎
PPTX
リモートワークで意識すべき7つのこと
by
西岡 賢一郎
PPTX
Amazon SageMaker ML Governance 3つの機能紹介
by
西岡 賢一郎
PPTX
Feature StoreのOnline StoreとOffline Storeの違いについて理解する
by
西岡 賢一郎
PPTX
機械学習の特徴量を管理するAmazon SageMaker Feature Store
by
西岡 賢一郎
PPTX
Amazon SageMakerでカスタムコンテナを使った学習
by
西岡 賢一郎
PPTX
Amazon SageMakerでscikit-learnで作ったモデルのEndpoint作成
by
西岡 賢一郎
PPTX
Amazon AthenaでSageMakerを使った推論
by
西岡 賢一郎
PPTX
Amazon Athenaで独自の関数を使う Amazon Athena UDF - AthenaでTweetの感情分析
by
西岡 賢一郎
PPTX
TorchDataチュートリアル解説
by
西岡 賢一郎
PPTX
Amazon SageMaker Studio Lab紹介
by
西岡 賢一郎
PPTX
Amazon SageMaker Canvasを使ったノーコード機械学習
by
西岡 賢一郎
PPTX
PMFを目指すプロダクト開発組織が組織拡大するときににやるべきこと
by
西岡 賢一郎
PPTX
H2O Waveを使ったAIアプリケーション作成入門
by
西岡 賢一郎
PPTX
H2Oを使ったノーコードのAutoML
by
西岡 賢一郎
PPTX
AutoGluonではじめるAutoML
by
西岡 賢一郎
PPTX
XAI (説明可能なAI) の必要性
by
西岡 賢一郎
PPTX
ストリートビューから地域の豊かさを推定
by
西岡 賢一郎
PPTX
大域的探索から局所的探索へデータ拡張 (Data Augmentation)を用いた学習の探索テクニック
by
西岡 賢一郎
Amazon SageMaker Ground Truthを使って手動のラベル付けを簡略化する
by
西岡 賢一郎
リモートワークで知っておきたい コミュニケーション時の過大な期待
by
西岡 賢一郎
リモートワークで意識すべき7つのこと
by
西岡 賢一郎
Amazon SageMaker ML Governance 3つの機能紹介
by
西岡 賢一郎
Feature StoreのOnline StoreとOffline Storeの違いについて理解する
by
西岡 賢一郎
機械学習の特徴量を管理するAmazon SageMaker Feature Store
by
西岡 賢一郎
Amazon SageMakerでカスタムコンテナを使った学習
by
西岡 賢一郎
Amazon SageMakerでscikit-learnで作ったモデルのEndpoint作成
by
西岡 賢一郎
Amazon AthenaでSageMakerを使った推論
by
西岡 賢一郎
Amazon Athenaで独自の関数を使う Amazon Athena UDF - AthenaでTweetの感情分析
by
西岡 賢一郎
TorchDataチュートリアル解説
by
西岡 賢一郎
Amazon SageMaker Studio Lab紹介
by
西岡 賢一郎
Amazon SageMaker Canvasを使ったノーコード機械学習
by
西岡 賢一郎
PMFを目指すプロダクト開発組織が組織拡大するときににやるべきこと
by
西岡 賢一郎
H2O Waveを使ったAIアプリケーション作成入門
by
西岡 賢一郎
H2Oを使ったノーコードのAutoML
by
西岡 賢一郎
AutoGluonではじめるAutoML
by
西岡 賢一郎
XAI (説明可能なAI) の必要性
by
西岡 賢一郎
ストリートビューから地域の豊かさを推定
by
西岡 賢一郎
大域的探索から局所的探索へデータ拡張 (Data Augmentation)を用いた学習の探索テクニック
by
西岡 賢一郎
Amazon SageMaker Foundation Modelsで事前学習済みモデルを利用する
1.
Amazon SageMaker Foundation
Modelsで 事前学習済みモデルを利用する 大規模言語モデルを社会実装する 2023/03/25 第21回勉強会
2.
自己紹介 ● 名前: 西岡
賢一郎 ○ Twitter: @ken_nishi ○ note: 西岡賢一郎@研究者から経営者へ (https://note.com/kenichiro) ○ YouTube: 【経営xデータサイエンスx開発】西岡 賢一郎のチャンネル (https://www.youtube.com/channel/UCpiskjqLv1AJg64jFCQIyBg) ● 経歴 ○ 東京大学で位置予測アルゴリズムを研究し博士 (学術) を取得 ○ 東京大学の博士課程在学中にデータサイエンスをもとにしたサービスを提供する株式会社ト ライディアを設立 ○ トライディアを別のIT会社に売却し、CTOとして3年半務め、2021年10月末にCTOを退職 ○ CDPのスタートアップと株式会社データインフォームドの2つに所属 ○ 自社および他社のプロダクト開発チーム・データサイエンスチームの立ち上げ経験
3.
本日のお話 ● 大規模言語モデルの社会実装 ● 事前学習モデル ●
Amazon SageMaker Foundation Models ● デモ
4.
大規模言語モデルの社会実装
5.
言語モデルとそれを用いたサービスの普及 ● 言語モデルの研究が急速に進み、次々と大規模言語モデルが開発されている ○ GPT-3
(Generative Pre-trained Transformer 3): OpenAIが開発した自然言語処理モデル ○ T5 (Text-to-Text Transfer Transformer): Googleが開発した自然言語処理モデル ○ BERT (Bidirectional Encoder Representations from Transformers): Googleが開発した自 然言語処理モデル ○ RoBERTa (Robustly Optimized BERT Pretraining Approach): Facebookが開発した自然言 語処理モデル ○ DALL-E: OpenAIによって開発された大規模言語モデル ● これらを用いたサービス開発も盛んになってきている ○ e.g. チャットボット、記事・レポート作成、翻訳など ● 大規模言語モデルを用いたサービス開発では大規模言語モデルを構築すると きの課題を乗り越えなければならない
6.
大規模言語モデルを構築する難しさ ● 計算資源 ○ 多くのパラメータを持つため、トレーニングや推論の際に高いコンピューティングパワーが必要 ●
データ ○ トレーニングするために大量の多くのデータが必要 ○ 多くの場合、大量のデータを収集することは困難であり、また、データの品質やバランスを維持す ることも難しい。 ● トレーニング時間 ○ 大規模言語モデルをトレーニングするには、数週間から数ヶ月かかる ○ データの変化に対応するための定期的な再トレーニングのコストも高い ● パラメータ数の調整 ○ 多くのパラメータを持つため、適切なパラメータ数の決定が難しい ■ パラメータ数が多すぎると、トレーニング時間が長くなり、オーバーフィッティングのリスク が高くなる ■ パラメータ数が少なすぎると、モデルの表現力が制限される
7.
大規模言語モデルの社会実装 ● 大規模言語モデルを学習するには、膨大なデータセットと高度な計算資源が 必要。しかし、それらができるのは、一部の大手IT企業や研究機関に限られ る。 ● 自社のアプリケーションやサービスに対して自然言語処理を適用したくても、 データや計算資源に限界があるため、高品質の自然言語処理モデルを構築す ることが困難 事前学習モデルをファインチューニングして 自社の自然言語処理タスクに適用する
8.
事前学習モデル
9.
事前学習モデル ● 事前学習モデルは、深層学習など、パラメータ数が非常に多く、学習に膨大 な計算資源が必要とされるモデルでよく使われる ● 大量のデータを用いて事前に学習されたモデルであるため、少ないデータで も高い性能を発揮できる ●
画像認識や自然言語処理など大量の学習データが必要なモデルでよく使われ る ● 事前学習モデルをファインチューニングすることで、特定のタスクに対して 高い性能を発揮することができる
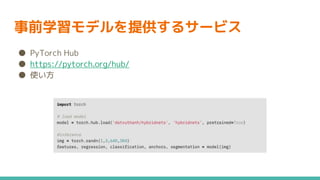
10.
事前学習モデルを提供するサービス ● PyTorch Hub ●
https://pytorch.org/hub/ ● 使い方
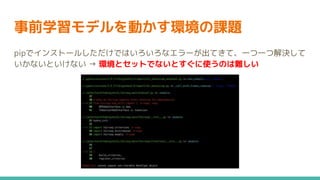
11.
事前学習モデルを動かす環境の課題 pipでインストールしただけではいろいろなエラーが出てきて、一つ一つ解決して いかないといけない → 環境とセットでないとすぐに使うのは難しい
12.
Amazon SageMaker Foundation
Models
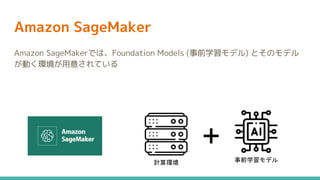
13.
Amazon SageMaker Amazon SageMakerでは、Foundation
Models (事前学習モデル) とそのモデル が動く環境が用意されている 事前学習モデル 計算環境
14.
提供されているFoundation Models ● AI21
Jurassic: AI21 Labsが開発した言語モデル ● Cohere Generate Model: Cohere Technologiesが開発した言語モデル ● Lyra-Fr 10B: フランス語のキュレーションデータで学習させた言語モデル ● Bloom: 産業規模の計算資源を用いて膨大な量のテキストデータに対してプ ロンプトからテキストを継続するように訓練されている ● FLAN-T5: 適切なプロンプトがあれば、テキストの要約、常識的な推論、自 然言語推論、質問と回答、文/感傷の分類、翻訳、代名詞解決などのゼロシ ョットNLPタスクを実行可能 ● Stable Diffusion: テキストからイメージを作成するモデル
15.
Foundation Modelsを使ってみる ● Amazon
SageMaker > Jump Start > Foundation Models でモデル一覧が参 照可能 ● TokyoリージョンなどJump Startがそもそも提供されていないリージョンも ある
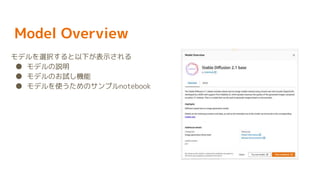
16.
Model Overview モデルを選択すると以下が表示される ● モデルの説明 ●
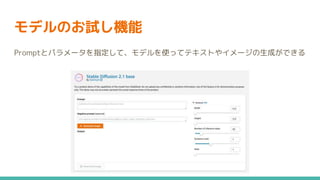
モデルのお試し機能 ● モデルを使うためのサンプルnotebook
17.
モデルのお試し機能 Promptとパラメータを指定して、モデルを使ってテキストやイメージの生成ができる
18.
デモ ● Flan T5
XLを使ったテキスト作成 ● https://github.com/knishioka/machine-learning- workshop/blob/main/sagemaker/foundation_models/flat-t5.ipynb
Editor's Notes
#3
こちらが私のプロフィールとなります。 機械学習には、大学時代の研究から携わっており、自分で立ち上げたスタートアップでも機械学習を使ったサービスを提供していました。 プロダクト開発チームやデータサイエンスチームの立ち上げなどもやっています。
#7
パフォーマンス:大規模言語モデルは、多くのパラメータを持つため、トレーニングや推論の際に高いコンピューティングパワーを必要とします。そのため、パフォーマンスの向上に対応するためには、高性能なハードウェアと効率的なアルゴリズムが必要です。 データ:大規模言語モデルをトレーニングするためには、多くのデータが必要です。しかし、多くの場合、大量のデータを収集することは困難であり、また、データの品質やバランスを維持することも難しい場合があります。 トレーニング時間:大規模言語モデルをトレーニングするには、通常、数週間から数ヶ月かかります。トレーニング時間が長くなると、データの変化に対応するために定期的に再トレーニングする必要があり、トレーニングコストが高くなることがあります。 パラメータ数の調整:大規模言語モデルは、多くのパラメータを持っています。パラメータ数が多すぎると、トレーニング時間が長くなり、オーバーフィッティングのリスクが高くなります。一方、パラメータ数が少なすぎると、モデルの表現力が制限されることがあります。適切なパラメータ数を決定することは、難しい問題です。
Download



















![[CTO Night & Day 2019] ML services: MLOps #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessionml-191027185903-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Track3-1] ビジネスで役立つAIリテラシーから機械学習エンジニアリングまで実践形式で学ぶ課題解決型AI人材育成とは?〜国内最大AIコンペサイトの...](https://cdn.slidesharecdn.com/ss_thumbnails/20200801deeplearningdigitalconferencecompressedsignate-200807090158-thumbnail.jpg?width=640&height=640&fit=bounds)
































