Download to read offline



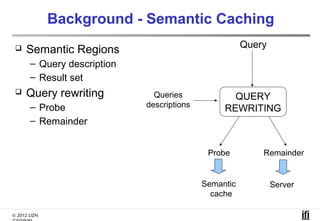





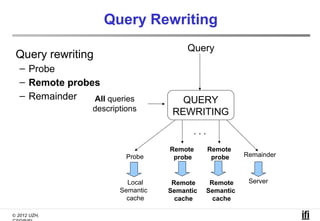


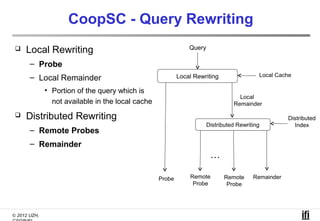
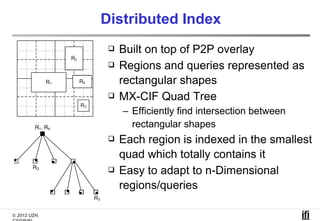


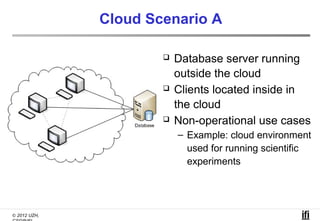
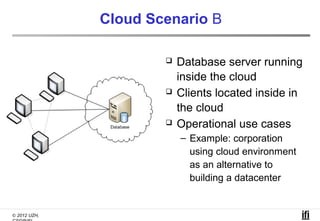


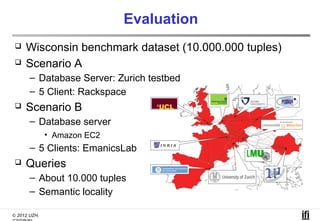
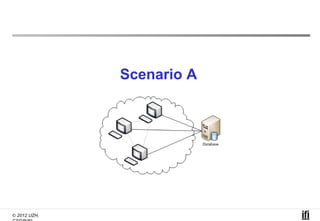
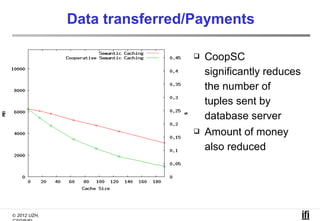
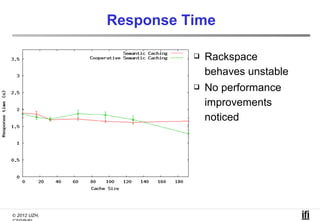
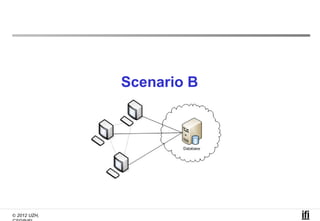
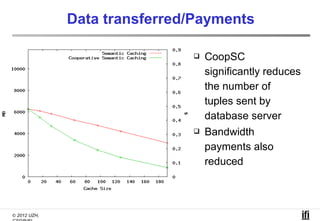
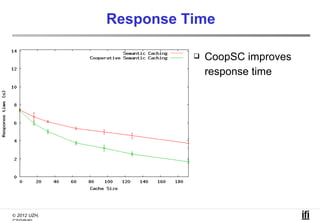
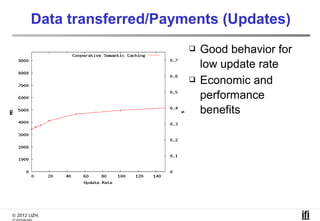
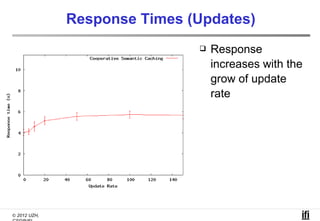



The document proposes a cooperative database caching approach called CoopSC to reduce load on database servers within cloud environments. CoopSC uses a distributed index to share cached query results between clients. It was evaluated using the Wisconsin benchmark dataset on the Amazon EC2 cloud. CoopSC significantly reduced the amount of data transferred and corresponding bandwidth payments compared to no caching. It also improved response times, especially with low update rates. However, performance benefits depended on cloud provider stability.

















































































