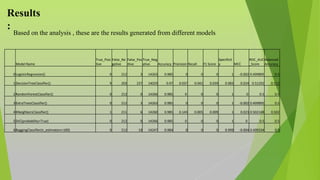
This document summarizes an AI internship completed by Manoj Kumar at Henotic Technology Private Limited from July 7th to September 6th 2022. The internship involved analyzing a travel insurance dataset containing 48260 observations using various machine learning models to predict whether a traveler could claim insurance or not. The models tested included logistic regression, decision trees, random forests, and more. Based on accuracy, F1 score, and ROC AUC score, the top models were found to be decision tree classifier, random forest classifier, and KNeighbors classifier.