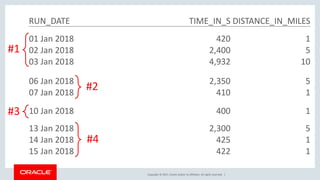
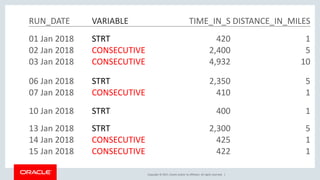
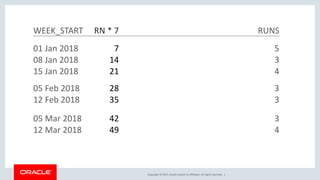
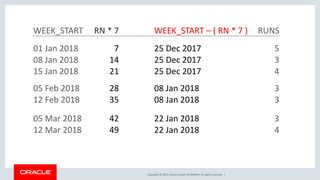
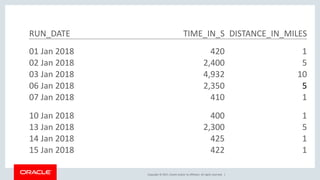
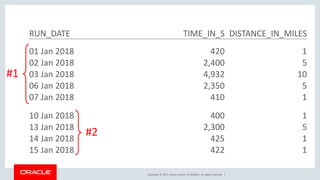
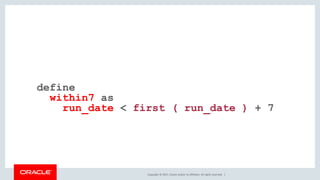
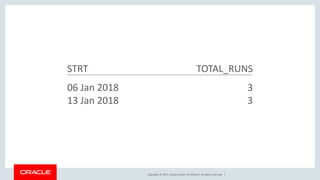
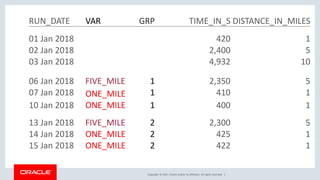
The document discusses various SQL techniques for finding patterns in data, including identifying consecutive dates and dates that fall within the same week. It provides examples of using regular expressions, window functions, and Oracle Database 12c's MATCH_RECOGNIZE clause to analyze a sample running log dataset and determine consecutive runs, runs within the same week, and consecutive weeks with a minimum number of runs. The document compares different approaches like MATCH_RECOGNIZE versus the Tabibitosan method.











































































![Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
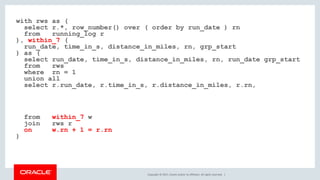
select * from running_log
model
dimension by ( row_number() over ( order by run_date ) rn )
measures ( run_date, 1 grp, run_date grp_start )
rules (
grp_start[1] = run_date[cv()],
grp_start[any] =
case
when run_date[cv()] < grp_start[cv()-1] + 7 then
grp_start[cv() - 1]
else run_date[cv()]
end ,
grp[any] =
case
when run_date[cv()] < grp_start[cv()-1] + 7 then
grp[cv() - 1]
else nvl(grp[cv() - 1] + 1, 1)
end
);](https://image.slidesharecdn.com/how-to-find-patterns-in-your-data-181004112811/85/How-to-Find-Patterns-in-Your-Data-with-SQL-84-320.jpg)















































![Copyright © 2017, Oracle and/or its affiliates. All rights reserved. |
(Regular) [exprsion]+ are easy to missteak](https://image.slidesharecdn.com/how-to-find-patterns-in-your-data-181004112811/85/How-to-Find-Patterns-in-Your-Data-with-SQL-134-320.jpg)














![[Pgday.Seoul 2017] 2. PostgreSQL을 위한 리눅스 커널 최적화 - 김상욱](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106040432-thumbnail.jpg?width=640&height=640&fit=bounds)






































































