The document presents a session from IBM discussing the JSON storage model and SQL APIs in DB2 for z/OS. It emphasizes the integration of JSON with enterprise data to enhance agility and efficiency in application development while outlining key features and examples of JSON functionalities, including conversion functions and built-in features for JSON data extraction. The session addresses the motivations for NoSQL in enterprise environments and provides a comprehensive agenda detailing various aspects of JSON technology in DB2.





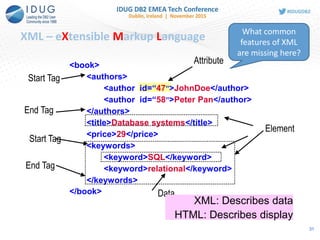
![JSON is the Language of the Web
• JavaScript Object Notation
• Lightweight data interchange format
• Specified in IETF RFC 4627
• http://www.JSON.org
• Designed to be minimal, portable, textual
and a subset of JavaScript
• Only 6 kinds of values!
• Easy to implement and easy to use
• Text format, so readable by humans and
machines
• Language independent, most languages
have features that map easily to JSON
• Used to exchange data between programs
written in all modern programming
languages
{
"firstName“ : "John",
"lastName" : "Smith",
"age" : 25,
“active” : true,
“freqflyer_num : null,
"address" :
{
"streetAddress“ : "21 2nd Street",
"city" : "New York",
"state" : "NY",
"postalCode" : "10021"
},
"phoneNumber“ :
[
{
"type" : "home",
"number“ : "212 555-1234"
},
{
"type" : “mobile",
"number“ : "646 555-4567"
}
]
}
5](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-5-320.jpg)


![JSON in SQL – First Steps
Extend JSON API Building blocks for external use
New functions released in DB2 11 only
• JSON2BSON - convert JSON string into BSON format
• BSON2JSON - convert BSON LOB into JSON string
• JSON_VAL - retrieve specific value from inside a
BSON object (also in V10)
INSERT INTO EMPLOYEE(data) VALUES (SYSTOOLS.JSON2BSON
(‘{ name: "Joe", age:28, isManager: false, jobs :[“QA”, “Developer”] } ’))
SELECT SYSTOOLS.BSON2JSON(data) FROM EMPLOYEE
UPDATE EMPLOYEE SET DATA =
SYSTOOLS.JSON2BSON('{ name: "Jane", age:18, isManager: false, jobs
:["Developer", "Team Lead"] } ')
JSON is stored internally as BSON format in inline BLOB column
9](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-9-320.jpg)



![SQL APIs Examples – Insert a JSON document
INSERT INTO JSONPO VALUES (
123,
SYSTOOLS.JSON2BSON(
'{"PO":{"@id": 101,
"@orderDate": "2014-11-18",
"customer": {"@cid": 999},
"items": {
"item": [{"@partNum": "872-AA",
"productName": "Lawnmower",
"quantity": 1,
"USPrice": 149.99,
"shipDate": "2014-11-20"
},
{"@partNum": "945-ZG",
"productName": "Sapphire Bracelet",
"quantity": 2,
"USPrice": 178.99,
"comment": "Not shipped"
}
]
}
} }'))
JSON2BSON () is used
to convert text format of
JSON to BSON
13](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-13-320.jpg)



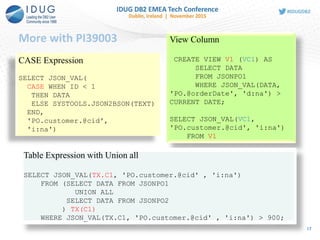
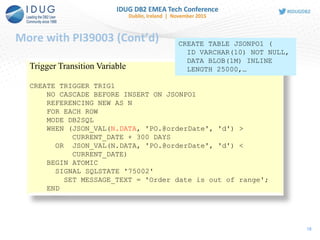
![More with PI39003 (Cont’d)
19
SQL PL Variable/Parameter
CREATE TYPE INTARRAY AS INTEGER ARRAY [20]!
CREATE PROCEDURE MYSP1(IN JSONDATA BLOB(16M))
LANGUAGE SQL
BEGIN
DECLARE POID INTARRAY;
DECLARE CUSTID INTEGER;
SET POID =
ARRAY[SELECT JSON_VAL(DATA, 'PO.@id', 'i:na')
FROM JSONPO1];
SELECT JSON_VAL(JSONDATA, 'PO.customer.@cid', 'i:na')
INTO CUSTID
FROM SYSIBM.SYSDUMMY1;
END!](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-19-320.jpg)

![SYSTOOLS.JSON_LEN
21
CREATE FUNCTION SYSTOOLS.JSON_LEN
( INJSON BLOB(16M)
, INELEM VARCHAR(2048)
)
RETURNS INTEGER
This function returns the size of
array of elements in JSON data,
and returns NULL if an
element is not an array. '{"PO":{"@id": 101,
"@orderDate": "2014-11-18",
"customer": {"@cid": 999},
"items": {
"item": [{"@partNum": "872-AA",
"productName": "Lawnmower",
"quantity": 1,
"USPrice": 149.99,
"shipDate": "2014-11-20"
},
{"@partNum": "945-ZG",
"productName": "Sapphire Bracelet",
"quantity": 2,
"USPrice": 178.99,
"comment": "Not shipped"
}
]
}
}
}
Example:
SELECT SYSTOOLS.JSON_LEN(DATA,
'PO.items.item') AS "# of entry in
PO.items.item"
FROM JSONPO;
Output:
# of entry in PO.items.item
2
1 record(s) selected](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-21-320.jpg)
![SYSTOOLS.JSON_TYPE
22
CREATE FUNCTION SYSTOOLS.JSON_TYPE
( INJSON BLOB(16M)
, INELEM VARCHAR(2048)
, MAXLENGTH INTEGER
)
RETURNS INTEGER
This function returns the type of
JSON data.
'{"PO":{"@id": 101,
"@orderDate": "2014-11-18",
"customer": {"@cid": 999},
"items": {
"item": [{"@partNum": "872-AA",
"productName": "Lawnmower",
"quantity": 1,
"USPrice": 149.99,
"shipDate": "2014-11-20"
},
{"@partNum": "945-ZG",
"productName": "Sapphire Bracelet",
"quantity": 2,
"USPrice": 178.99,
"comment": "Not shipped"
}
]
}
}
}
Example:
SELECT SYSTOOLS.JSON_TYPE(DATA,
'PO.items.item.productName', 20) AS
"JSON_TYPE“ FROM JSONPO;
JSON_TYPE
2
Example:
SELECT SYSTOOLS.JSON_TYPE(DATA,
'PO.items.item.USPrice', 20) AS "JSON_TYPE“
FROM JSONPO;
JSON_TYPE
1](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-22-320.jpg)
![SYSTOOLS.JSON_TABLE
23
CREATE FUNCTION
SYSTOOLS.JSON_TABLE
( INJSON BLOB(16M)
, INELEM VARCHAR(2048)
, RETTYPE VARCHAR(100)
)
RETURNS TABLE
( TYPE INTEGER
, VALUE VARCHAR(2048)
)
This function returns array of
elements in JSON data.
Example:
SELECT X.* FROM JSONPO,
TABLE(SYSTOOLS.JSON_TABLE(DATA,
'PO.items.item.productName', 's:20')) X
Output:
TYPE VALUE
2 Lawnmower
2 Sapphire Bracelet
'{"PO":{"@id": 101,
"@orderDate": "2014-11-18",
"customer": {"@cid": 999},
"items": {
"item": [{"@partNum": "872-AA",
"productName": "Lawnmower",
"quantity": 1,
"USPrice": 149.99,
"shipDate": "2014-11-20"
},
{"@partNum": "945-ZG",
"productName": "Sapphire Bracelet",
"quantity": 2,
"USPrice": 178.99,
"comment": "Not shipped"
}
]
}
}
}](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-23-320.jpg)
![SYSTOOLS.JSON_TABLE
24
Example:
SELECT X.* FROM JSONPO,
TABLE(SYSTOOLS.JSON_TABLE(DATA,
'PO.items.item', 's:200')) X
'{"PO":{"@id": 101,
"@orderDate": "2014-11-18",
"customer": {"@cid": 999},
"items": {
"item": [{"@partNum": "872-AA",
"productName": "Lawnmower",
"quantity": 1,
"USPrice": 149.99,
"shipDate": "2014-11-20"
},
{"@partNum": "945-ZG",
"productName": "Sapphire Bracelet",
"quantity": 2,
"USPrice": 178.99,
"comment": "Not shipped"
}
]
}
}
}
Output:
TYPE VALUE
3 {@partNum:"872-
AA",productName:"Lawnmower",quantity:1,USPrice:149.990000,shipDate:"2014-11-
20"}
3 {@partNum:"945-ZG",productName:"Sapphire
Bracelet",quantity:2,USPrice:178.990000,comment:"Not shipped"}](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-24-320.jpg)

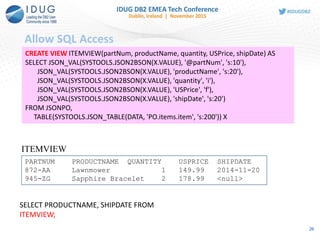
![Parameter to Table
27
CREATE TABLE T1 (
PARTNUM VARCHAR(10),
PRODUCTNAME VARCHAR(20),
QUANTITY INT,
USPRICE DECFLOAT,
SHIPDATE VARCHAR(20));
PARTNUM PRODUCTNAME QUANTITY USPRICE SHIPDATE
872-AA Lawnmower 1 149.99 2014-11-20
945-ZG Sapphire Bracelet 2 178.99 <null>
T1
'{"PO":{"@id": 101,
"@orderDate": "2014-11-18",
"customer": {"@cid": 999},
"items": {
"item": [{"@partNum": "872-AA",
"productName": "Lawnmower",
"quantity": 1,
"USPrice": 149.99,
"shipDate": "2014-11-20"
},
{"@partNum": "945-ZG",
"productName": "Sapphire Bracelet",
"quantity": 2,
"USPrice": 178.99,
"comment": "Not shipped"
}
] …
INSERT INTO T1
SELECT JSON_VAL(SYSTOOLS.JSON2BSON(X.VALUE), '@partNum', 's:10'),
JSON_VAL(SYSTOOLS.JSON2BSON(X.VALUE), 'productName', 's:20') ,
JSON_VAL(SYSTOOLS.JSON2BSON(X.VALUE), 'quantity', 'i'),
JSON_VAL(SYSTOOLS.JSON2BSON(X.VALUE), 'USPrice', 'f') ,
JSON_VAL(SYSTOOLS.JSON2BSON(X.VALUE), 'shipDate', 's:20')
FROM
TABLE(SYSTOOLS.JSON_TABLE(
SYSTOOLS.JSON2BSON(?), 'PO.items.item', 's:200')) X](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-27-320.jpg)

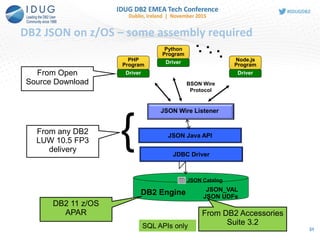



![Create tables to store XML and JSON, create indexes
XML
CREATE TABLE XMLT1 (ID INT, XMLPO XML) IN DB1.TS1;
CREATE TABLE XMLT2 (ID INT, XMLPO XML(XMLSCHEMA ID
SYSXSR.PO1)) IN DB1.TS1;
create index custidx1 on XMLT1(XMLPO)
generate key using
xmlpattern '/PO/customer/@cid' as sql decfloat
JSON – JAVA API
nosql>db.createCollection("JSONPO", {_id: "$oid"})
Collection: TEST."JSONPO" created. Use db.JSONPO.
nosql>db.JSONPO.ensureIndex({"PO.customer.@cid":[1,
"$int"]}, "myJSONIndex")
Create table
with XML col
associated
with an XML
schema
Create index on
/PO/customer/@
cid
JSON - SQL APIs
CREATE TABLE JSONPO( ID VARBIN(12) NOT NULL,
DATA BLOB(16M) INLINE LENGTH 25000,
PRIMARY KEY(ID)) CCSID UNICODE
CREATE INDEX IX1 ON JSONPO(
JSON_VAL(DATA, 'PO.customer.@cid','i:na'))
Create index on
PO.customer.@
cid 35](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-35-320.jpg)
![Insert
XML
INSERT INTO XMLT1 values(1,
'<PO id="123" orderDate="2013-11-18">
<customer cid="999"/>
<items>
……
</items>
</PO>')
JSON – JAVA API
nosql>db.JSONPO.insert(
{
"PO": {
"@id": 123,
"@orderDate": "2013-11-18",
"customer": { "@cid": 999 },
"items": {
…….
]
}
}
})
JSON – SQL API (V11 only)
INSERT INTO JSONPO(data) VALUES
(SYSTOOLS.JSON2BSON
(‘{ “PO”:{…} } ’))
JSON data is
converted to
BSON before
sending to DB2
XML parsing
and validation is
eligible for
offload to zIIP
36](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-36-320.jpg)
![Query – find productName for cid 999
XML
SELECT XMLQuery('/PO/items/item/productName' PASSING XMLPO)
FROM XMLT1
WHERE XMLEXISTS('/PO/customer[@cid=999]' PASSING XMLPO)
JSON – JAVA API
nosql>db.JSONPO.find({"PO.customer.@cid": 999}, {_id:0,
"PO.items.item.productName":1})
From trace:
SELECT CAST(SYSTOOLS.JSON_BINARY2(DATA,
'PO.items.item.productName', 2048) AS VARCHAR(2048) FOR BIT
DATA) AS "xPO_items_item_productName" FROM TEST."JSONPO"
WHERE (JSON_VAL(DATA, 'PO.customer.@cid', 'f:na')=?)
JSON – SQL API
SELECT JSON_VAL(DATA, 'PO.items.item.productName', 's:10')
FROM JSONPO
WHERE JSON_VAL(DATA,'PO.customer.@cid', 'i:na') = 999
37](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-37-320.jpg)
![Update – replace value
XML
-- replace the USPrice of SKII daily lotion
UPDATE XMLT1 SET XMLPO =
XMLModify('replace value of node
/PO/items/item[productName="SKII daily lotion"]/USPrice
with xs:decimal(200)')
WHERE XMLEXISTS('/PO[items/item/productName="SKII daily lotion"
and customer/@cid=111]'
PASSING XMLPO)
JSON – JAVA API
nosql>db.JSONPO.update(
{"PO.customer.@cid": 111,
"PO.items.item.productName":"SKII daily lotion"},
{ $set:{"PO.items.item.$.USPrice": 200}})
JSON – SQL API
UPDATE JSONPO
SET DATA = SYSTOOLS.JSON2BSON(‘{ …. }')
WHERE JSON_VAL(DATA, ‘PO.customer.@cid', 'i:na') = 111
AND JSON_VAL(DATA, ‘PO.items.item.productName', ‘s:na') ="SKII
daily lotion”
Whole
document
update
Whole
document
update
Sub-
document
update
38](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-38-320.jpg)
![Delete – delete the document for cid 111
XML
DELETE FROM XMLT1
WHERE XMLEXISTS('/PO/customer[@cid=111]'
PASSING XMLPO)
JSON – JAVA API
nosql> db.JSONPO.remove({"PO.customer.@cid": 111})
JSON – SQL API
DELETE JSONPO
WHERE JSON_VAL(DATA, ‘PO.Customer.@cid', 'i:na') = 111
39](https://image.slidesharecdn.com/idug2015emeajson-160821181634/85/JSON-Support-in-DB2-for-z-OS-39-320.jpg)