Download as ODP, PPTX





![require "csv"
data = CSV.open("data.csv")
output = data.readlines.map do |line|
line.map do |col|
col.downcase.gsub(/b('?[a-z])/) { $1.capitalize } }
end
end
File.open("output.csv", "w+") do |f|
f.write output.join("n")
end
Unoptimized Program](https://image.slidesharecdn.com/adymorailsconfimproveperformance-140425151802-phpapp02/75/Alexander-Dymo-RailsConf-2014-Improve-performance-Optimize-Memory-and-Upgrade-to-Ruby-2-1-9-2048.jpg)
![require "csv"
output = File.open("output.csv", "w+")
CSV.open("examples/data.csv", "r").each do |line|
output.puts line.map do |col|
col.downcase!
col.gsub!(/b('?[a-z])/) { $1.capitalize! }
end.join(",")
end
Memory Optimized Program](https://image.slidesharecdn.com/adymorailsconfimproveperformance-140425151802-phpapp02/75/Alexander-Dymo-RailsConf-2014-Improve-performance-Optimize-Memory-and-Upgrade-to-Ruby-2-1-11-2048.jpg)





![Ruby GC Tuning Goal
Goal: balance the number of GC runs and peak memory usage
How to check:
> GC.stat[:minor_gc_count]
> GC.stat[:major_gc_count]
> `ps -o rss= -p #{Process.pid}`.chomp.to_i / 1024 #MB](https://image.slidesharecdn.com/adymorailsconfimproveperformance-140425151802-phpapp02/75/Alexander-Dymo-RailsConf-2014-Improve-performance-Optimize-Memory-and-Upgrade-to-Ruby-2-1-17-2048.jpg)


























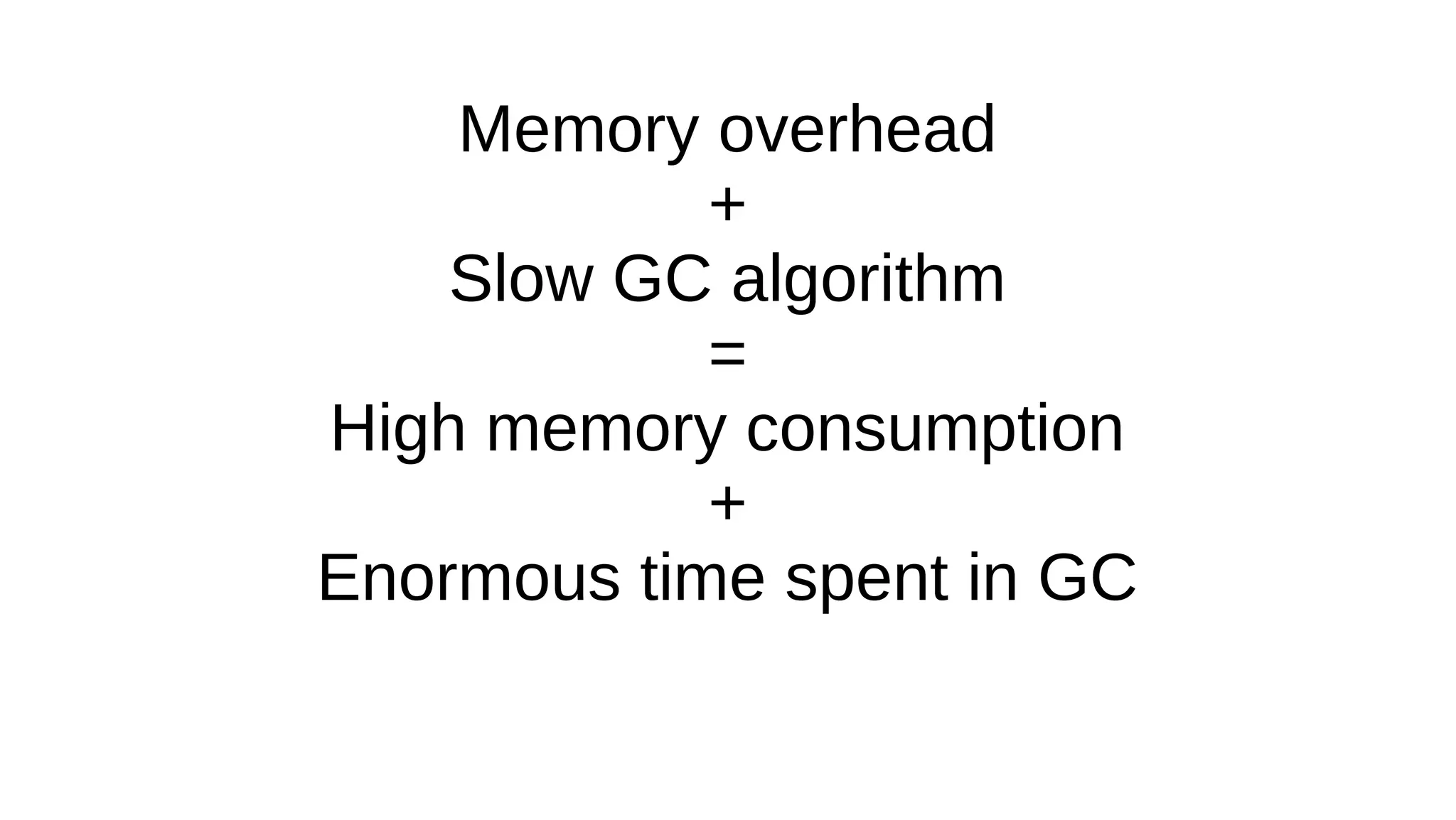
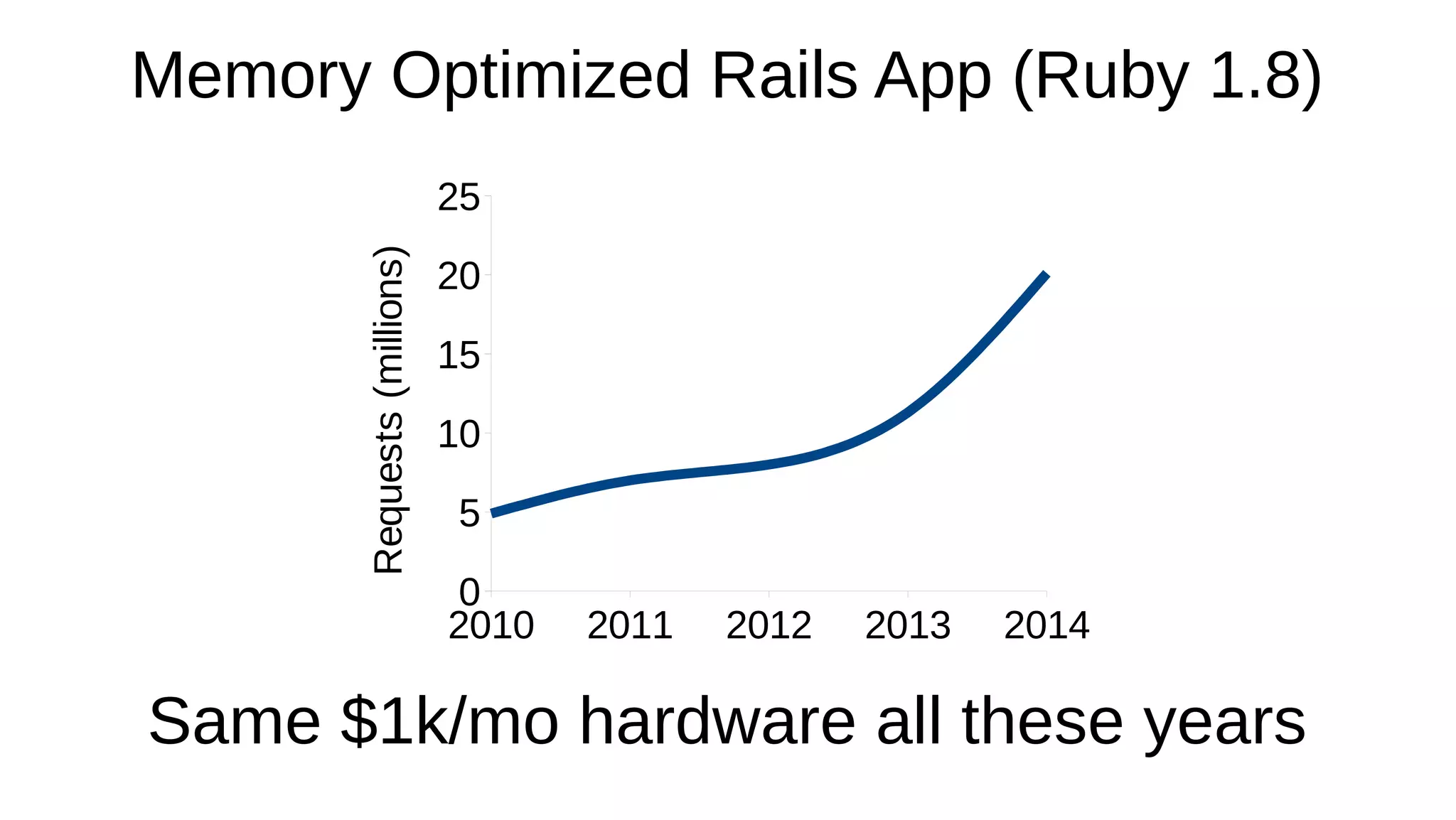
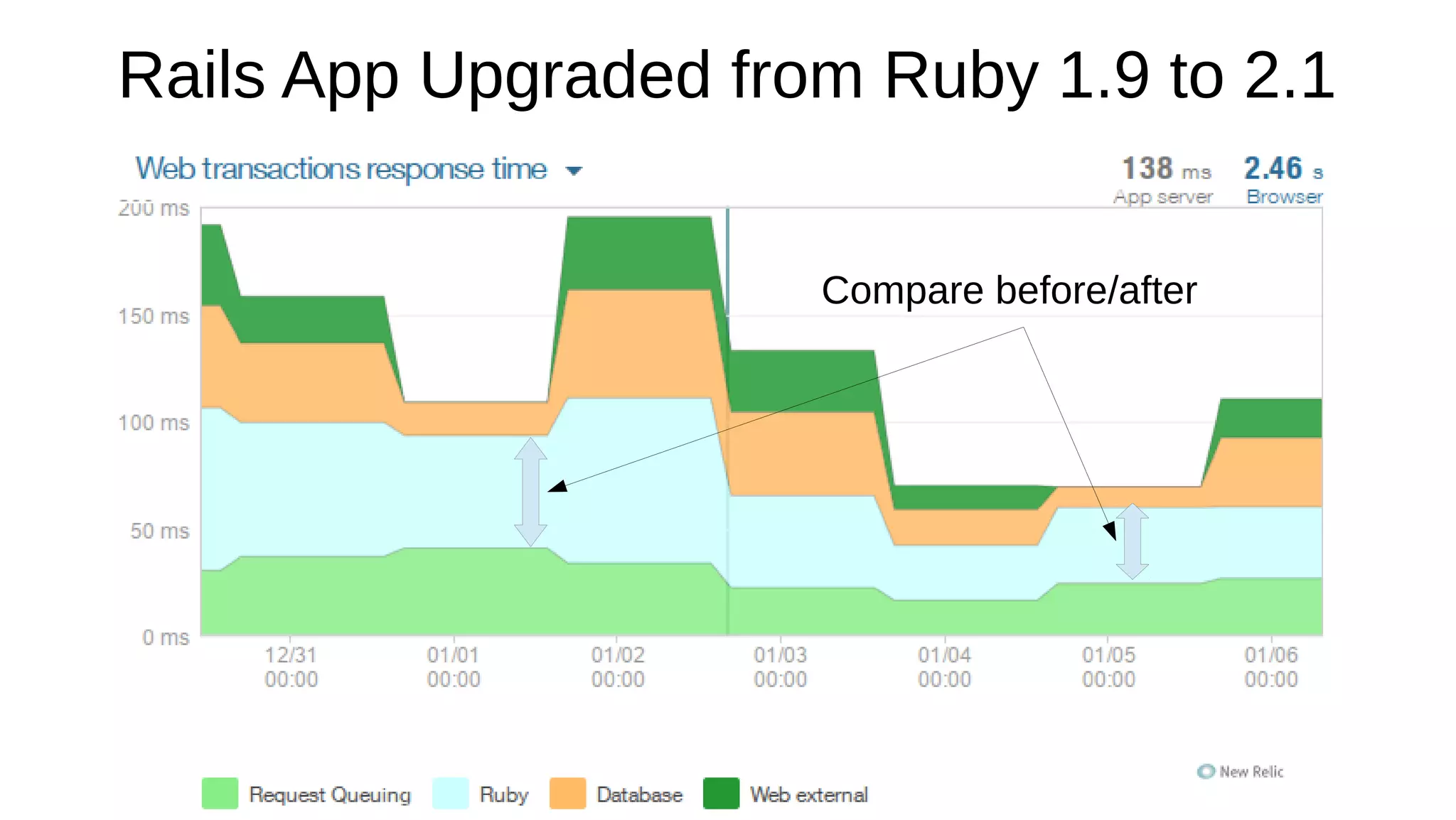
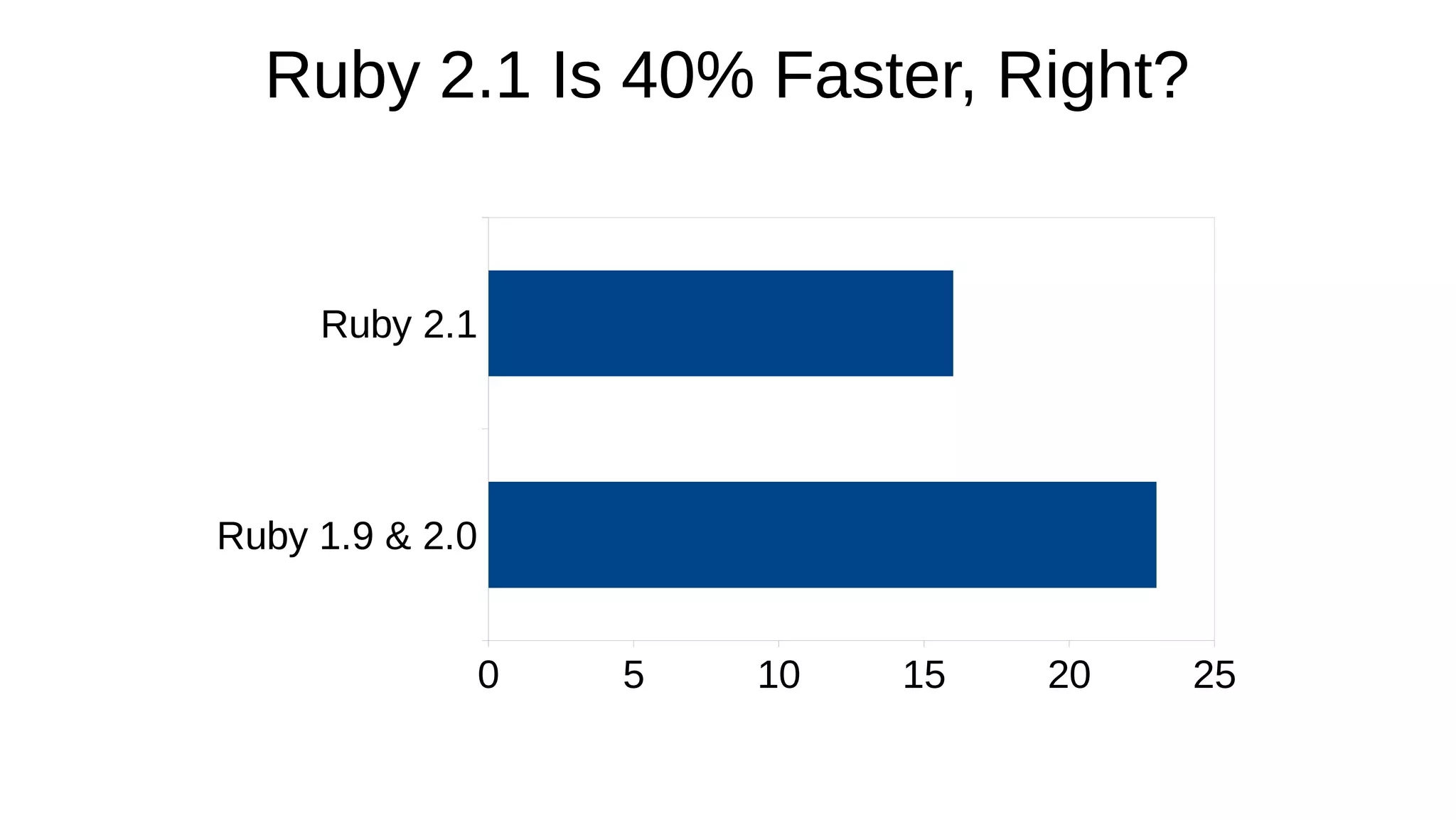
Memory optimization and upgrading to Ruby 2.1 can improve performance of Ruby applications. The document discusses 5 strategies for memory optimization: 1) tuning the garbage collector, 2) limiting growth of the Ruby instance, 3) controlling GC manually, 4) writing less Ruby code, and 5) avoiding memory-intensive Ruby and Rails features. It provides examples for each strategy and recommends tools like GC.stat and ObjectSpace for memory profiling. While Ruby 2.1 improves performance by default, optimizing memory is more important and can make applications perform the same in Ruby 1.9, 2.0 and 2.1.


































































