Downloaded 10 times




![IMPRESSION LOG
AD SITE COOKIE IMPRESSIONS CLICKS SEGMENTS
bmw_X5 forbes.com 13e835610ff0d95 10 1 [a.m, b.rk, c.rh, d.sn, ...]
mercedes_2015 forbes.com 13e8360c8e1233d 5 0 [a.f, b.rk, c.hs, d.mr, ...]
nokia gizmodo.com 13e3c97d526839c 8 0 [a.m, b.tk, c.hs, d.sn, ...]
apple_music reddit.com 1357a253f00c0ac 3 1 [a.m, b.rk, d.sn, e.gh, ...]
nokia cnn.com 13b23555294aced 2 1 [a.f, b.tk, c.rh, d.sn, ...]
apple_music facebook.com 13e8333d16d723d 9 1 [a.m, d.sn, g.gh, s.hr, ...]](https://image.slidesharecdn.com/btrofimov-collective-reporting-151008091043-lva1-app6892/75/Audience-counting-at-Scale-6-2048.jpg)






![IMPRESSION LOG TRANSFORMATION
AD SITE COOKIE IMPRESSIONS CLICKS SEGMENTS
bmw_X5 forbes.com 13e835610ff0d95 10 1 [a.m, b.rk, c.rh, d.sn, ...]
mercedes_2015 forbes.com 13e8360c8e1233d 5 0 [a.f, b.rk, c.hs, d.mr, ...]
nokia gizmodo.com 13e3c97d526839c 8 0 [a.m, b.tk, c.hs, d.sn, ...]
apple_music reddit.com 1357a253f00c0ac 3 1 [a.m, b.rk, d.sn, e.gh, ...]
nokia cnn.com 13b23555294aced 2 1 [a.f, b.tk, c.rh, d.sn, ...]
apple_music facebook.com 13e8333d16d723d 9 1 [a.m, d.sn, g.gh, s.hr, ...]
Splitting original impression log table into
two separate aggregated tables
• by campaign
• by segmentsSegments](https://image.slidesharecdn.com/btrofimov-collective-reporting-151008091043-lva1-app6892/75/Audience-counting-at-Scale-17-2048.jpg)




![WRITING OWN SPARK
AGGREGATION FUNCTIONS
case class MergeHLLPartition(child: Expression)
extends AggregateExpression with trees.UnaryNode[Expression] { ... }
case class MergeHLLMerge(child: Expression)
extends AggregateExpression with trees.UnaryNode[Expression] { ... }
case class MergeHLL(child: Expression)
extends PartialAggregate with trees.UnaryNode[Expression] {
override def asPartial: SplitEvaluation = {
val partial = Alias(MergeHLLPartition(child), "PartialMergeHLL")()
SplitEvaluation(
MergeHLLMerge(partial.toAttribute),
partial :: Nil )
}
}
def mergeHLL(e: Column): Column = MergeHLL(e.expr)
define function that will be
applied to each row
in RDD partition
define function that will take
results from different partitions
and merge them together
tell Spark how you want it to
split your computation
across RDD](https://image.slidesharecdn.com/btrofimov-collective-reporting-151008091043-lva1-app6892/75/Audience-counting-at-Scale-22-2048.jpg)
![AGGREGATION FUNCTIONS
PROS & CONS
Simple DSL and Native DataFrame look-like functions
Works much faster than solving this problem with Scala transformations on
top of RDD[Row]
Dramatic Performance Speed-Up via mutable state control (10x times)
UDF should be part of private Spark package, risk these interfaces might be
changed/abandoned in the future.](https://image.slidesharecdn.com/btrofimov-collective-reporting-151008091043-lva1-app6892/75/Audience-counting-at-Scale-23-2048.jpg)




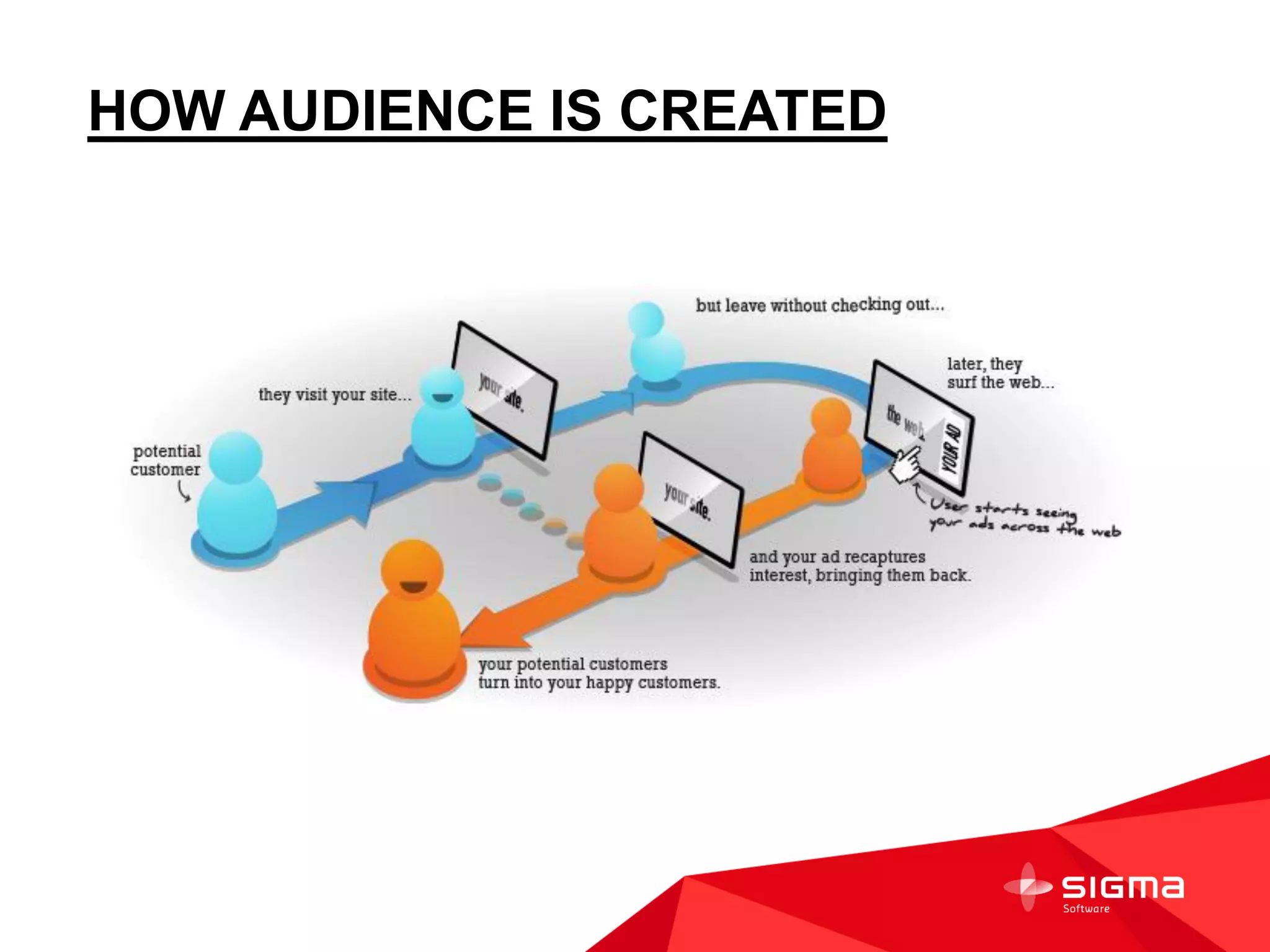
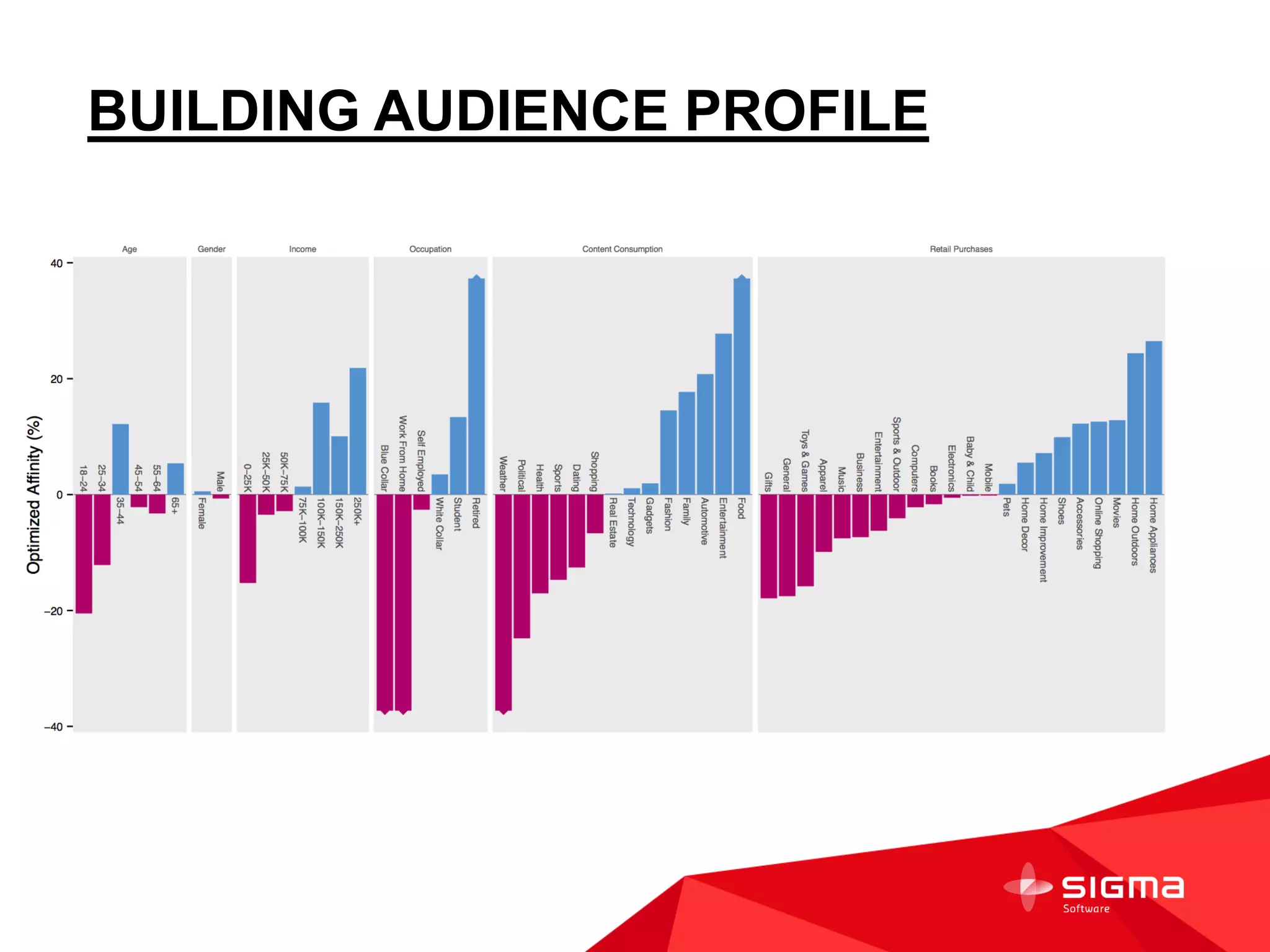
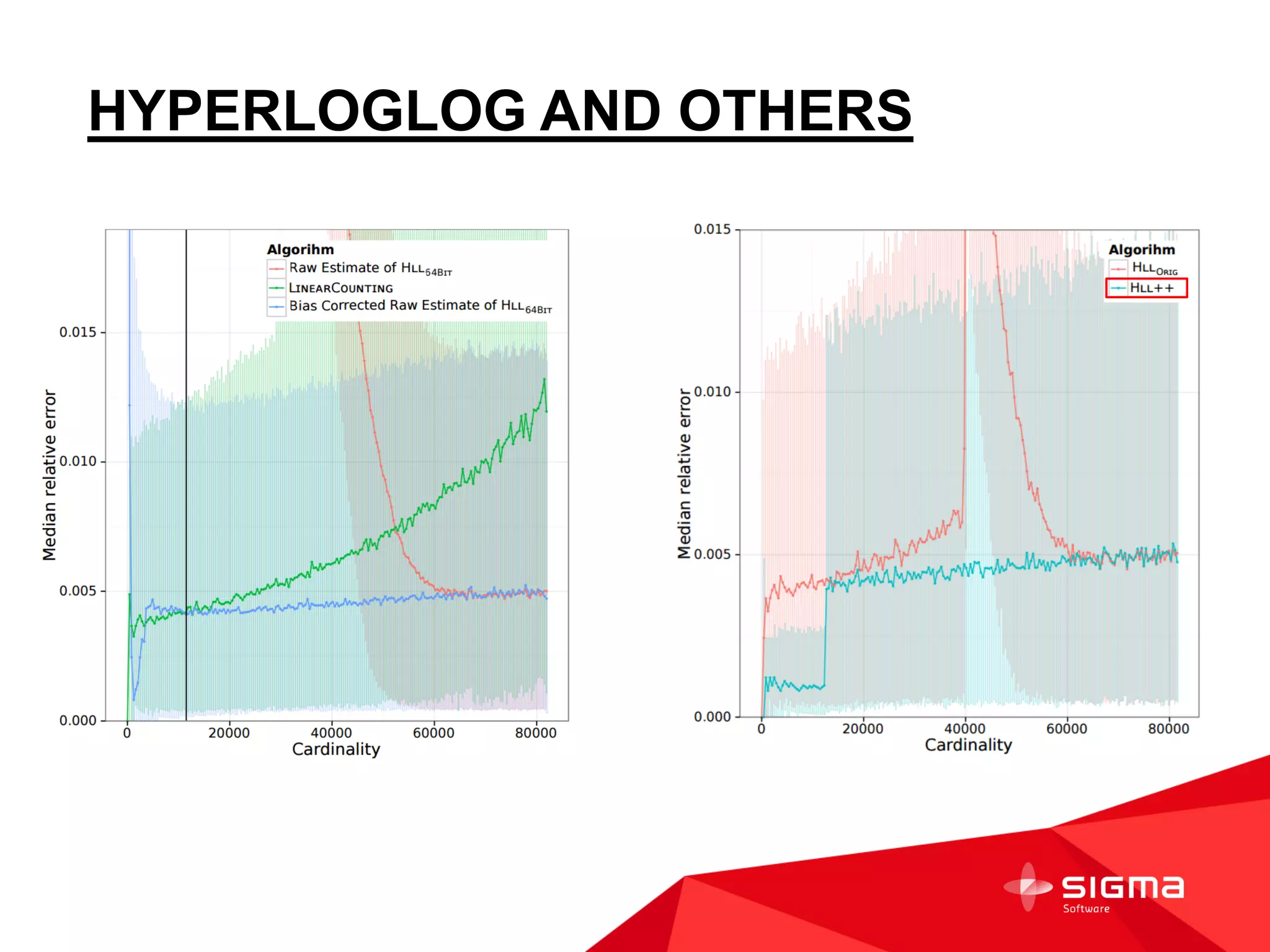
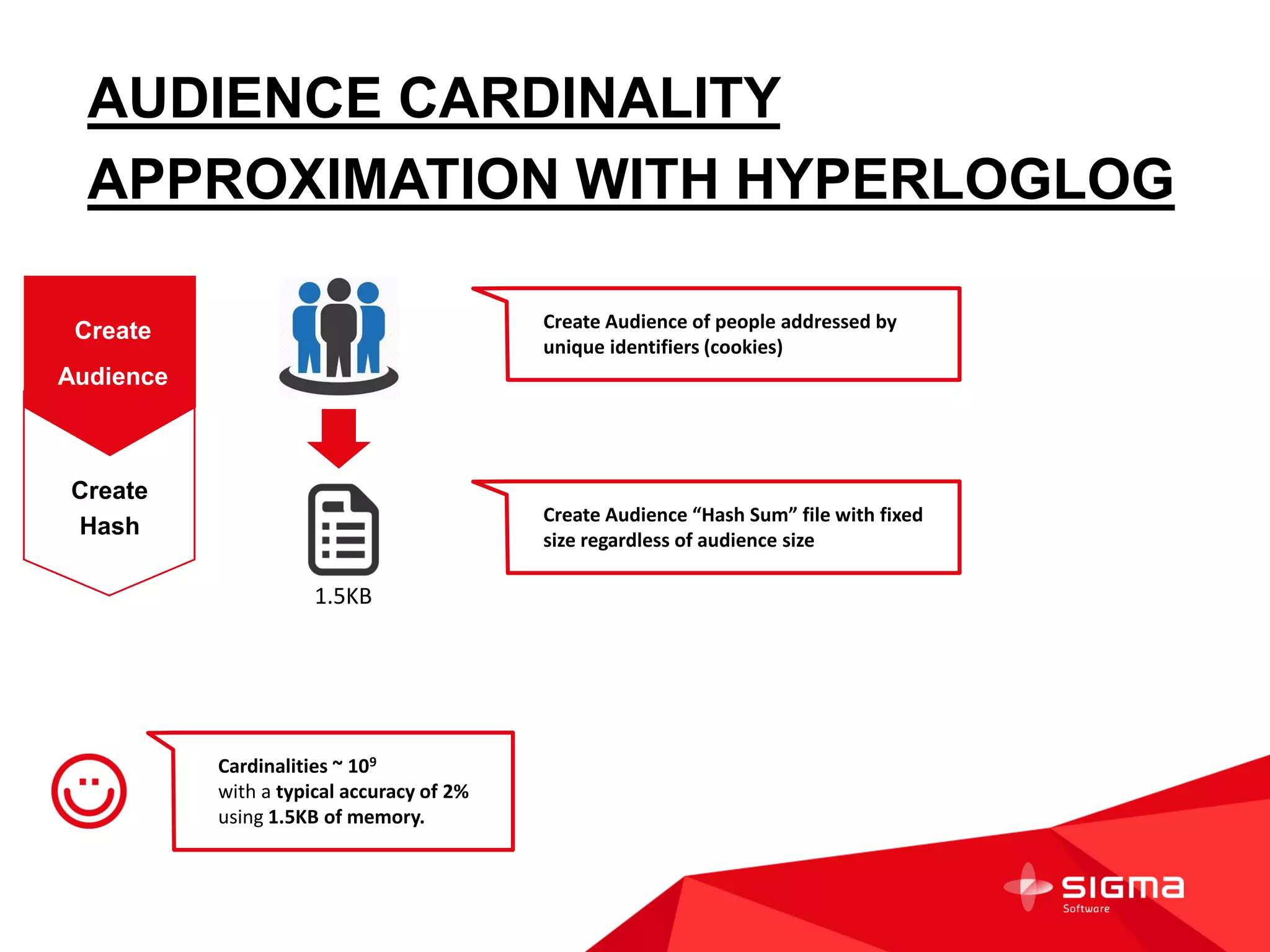
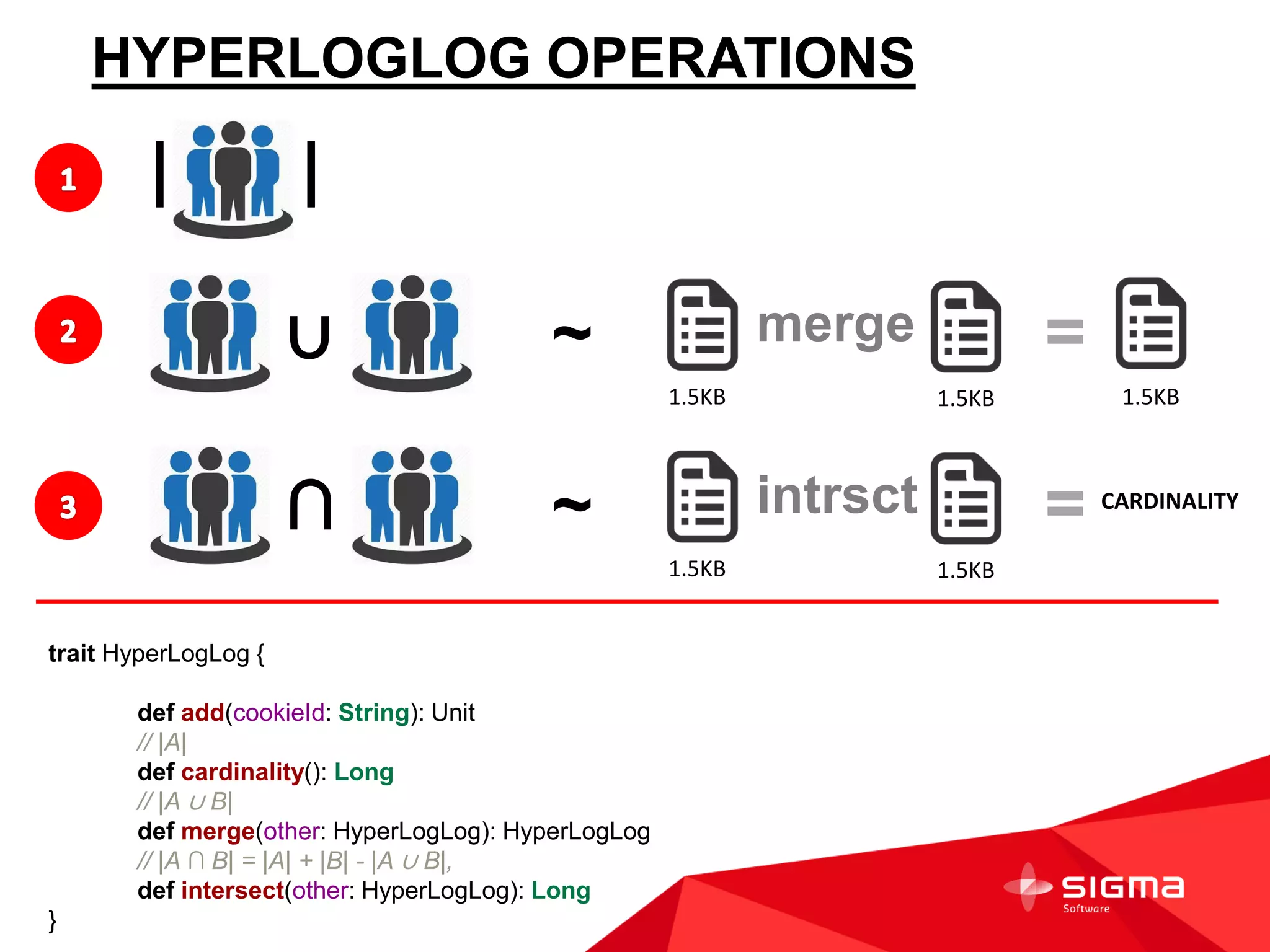
The document discusses audience counting at scale using Spark. It provides context on a customer that collects data on 1 billion user profiles to build models and make predictions. It then discusses motivation, counting fundamentals using HyperLogLog, and how to perform counting with Spark. Specifically, it shows how to transform log data into HyperLogLog summaries, work with the data in DataFrames, and provide examples of counting audiences and segments. It also provides some notes on writing custom Spark aggregation functions and using Spark as an in-memory SQL database for analytics.




























































![Learning from nature [slides from Software Architecture meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/learning-from-nature-200608115407-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Pavlov - There Is No Spoon: Inferring Vision from Neura...](https://cdn.slidesharecdn.com/ss_thumbnails/wg0v1umoqjm4nnbd3p0v-there-is-no-spoon-251205085715-6d81d6c5-thumbnail.jpg?width=640&height=640&fit=bounds)