Downloaded 16 times
















![Discovery
isMaster command:
setName: <name>,
ismaster: true, secondary: false, arbiterOnly:
hosts: [ <visible nodes> ],
passives: [ <prio:0 nodes> ],
arbiters: [ <nodes> ],
primary: <active primary>,
tags: {<tags>},
me: <me>](https://image.slidesharecdn.com/advancedreplicationinternals-130514163514-phpapp02/75/Advanced-Replication-Internals-18-2048.jpg)
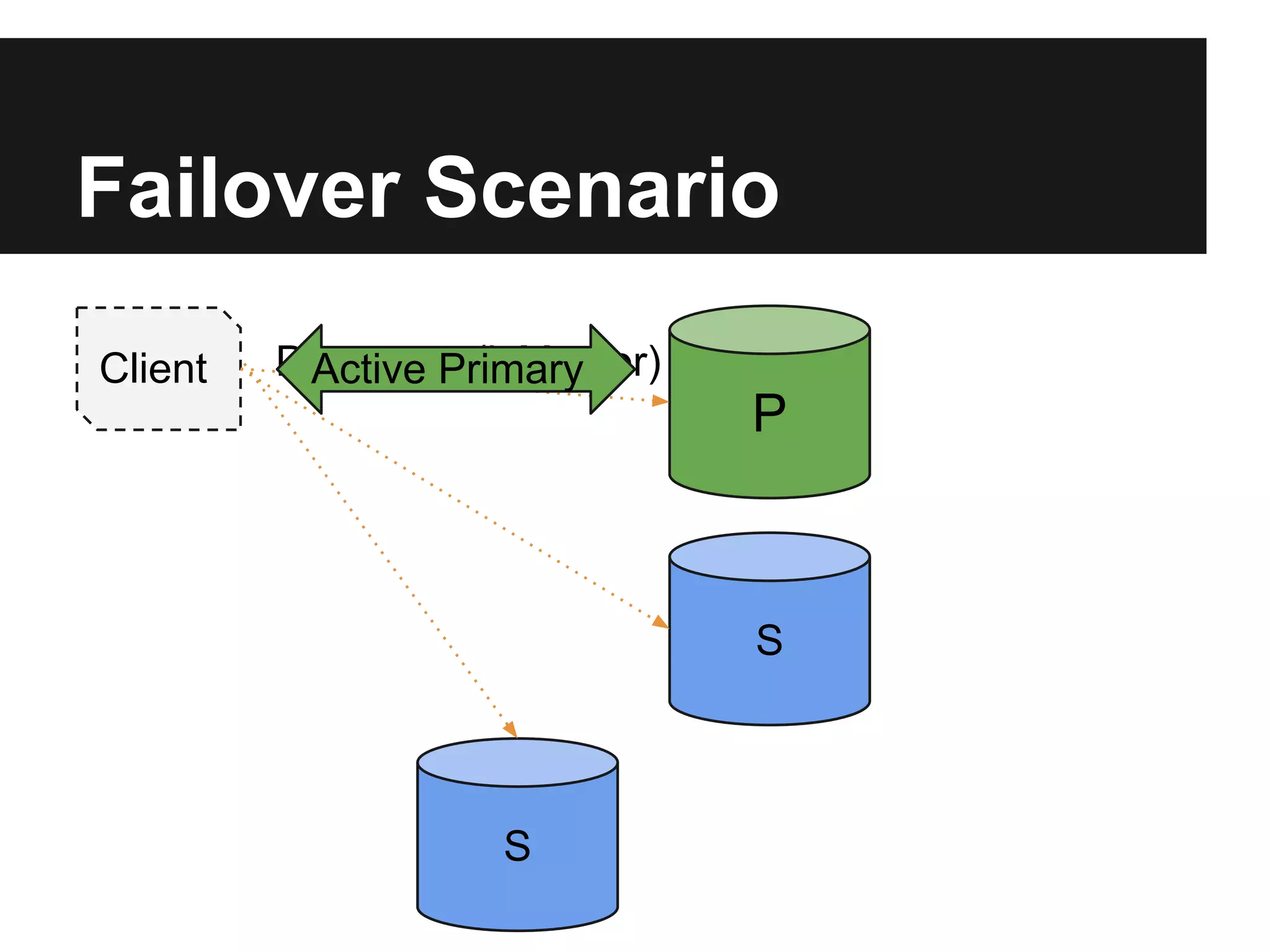
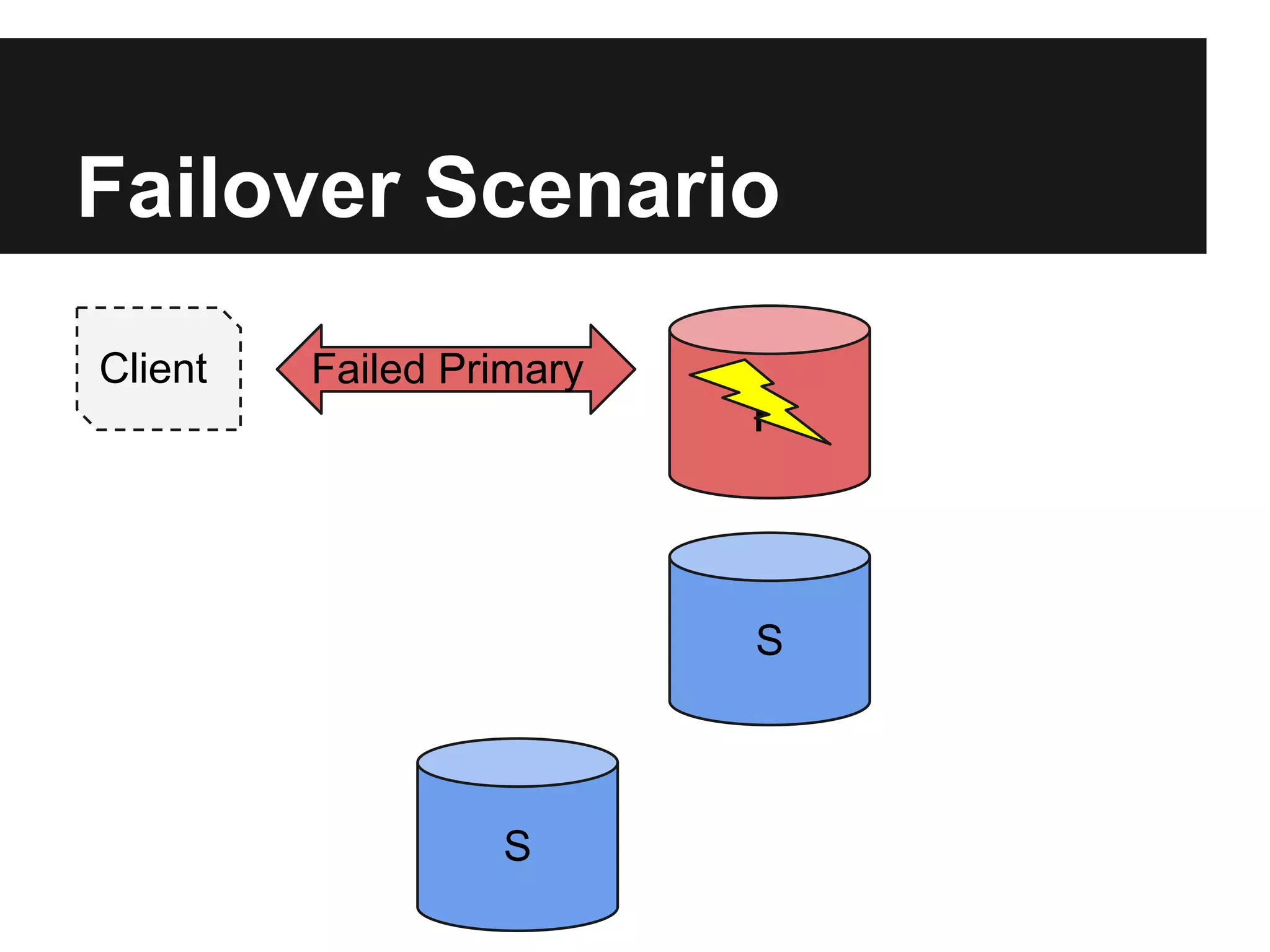
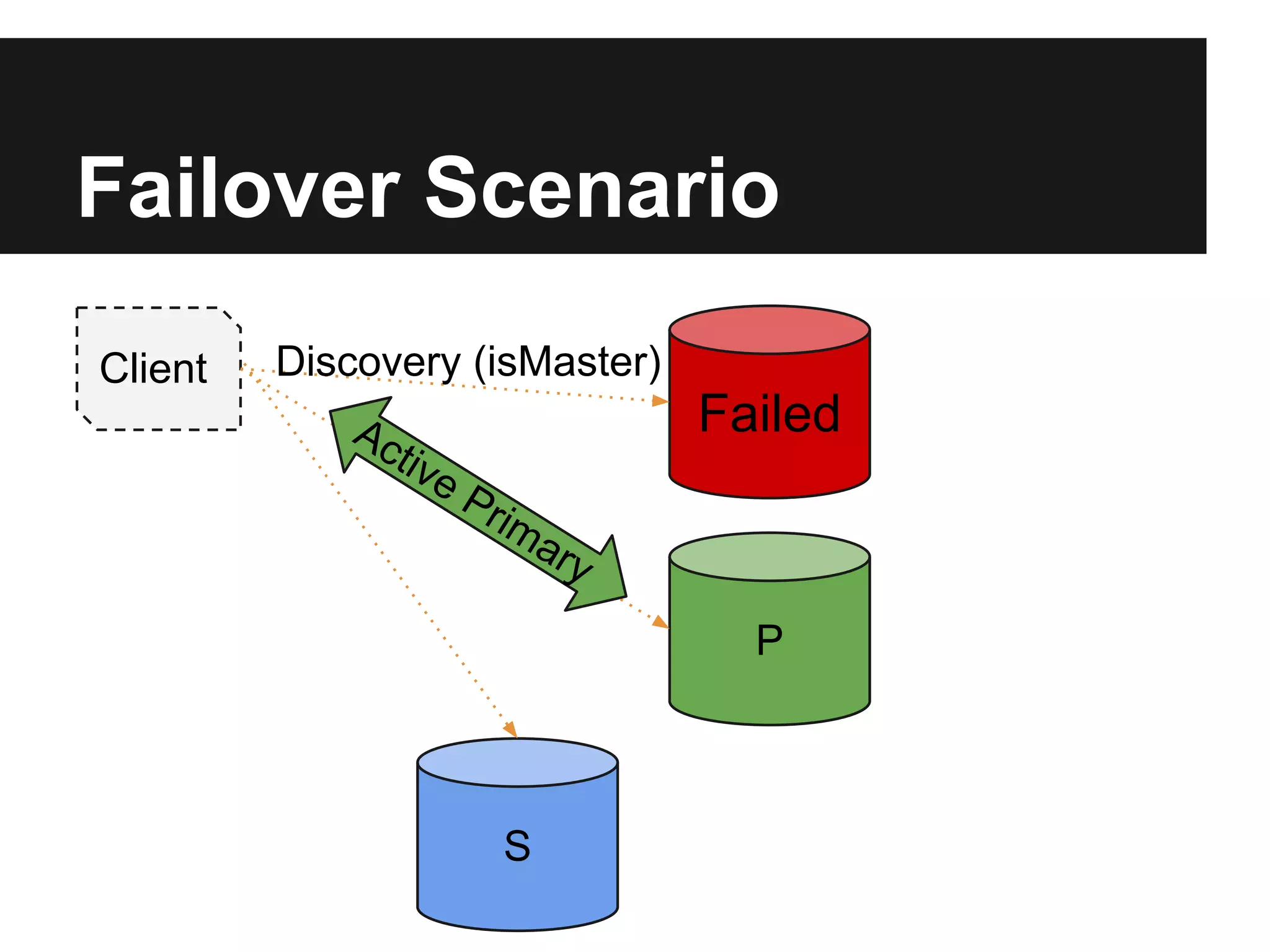

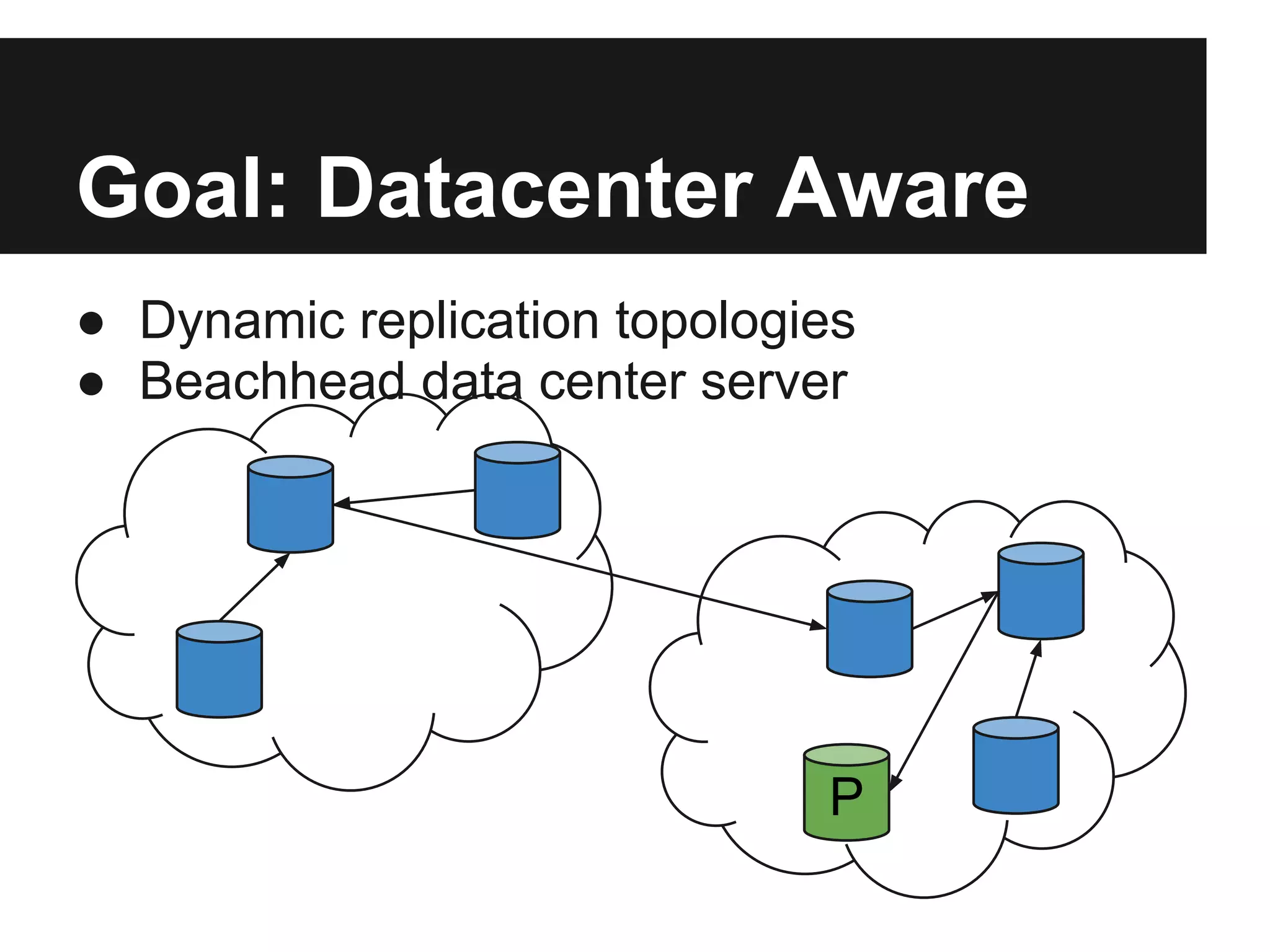
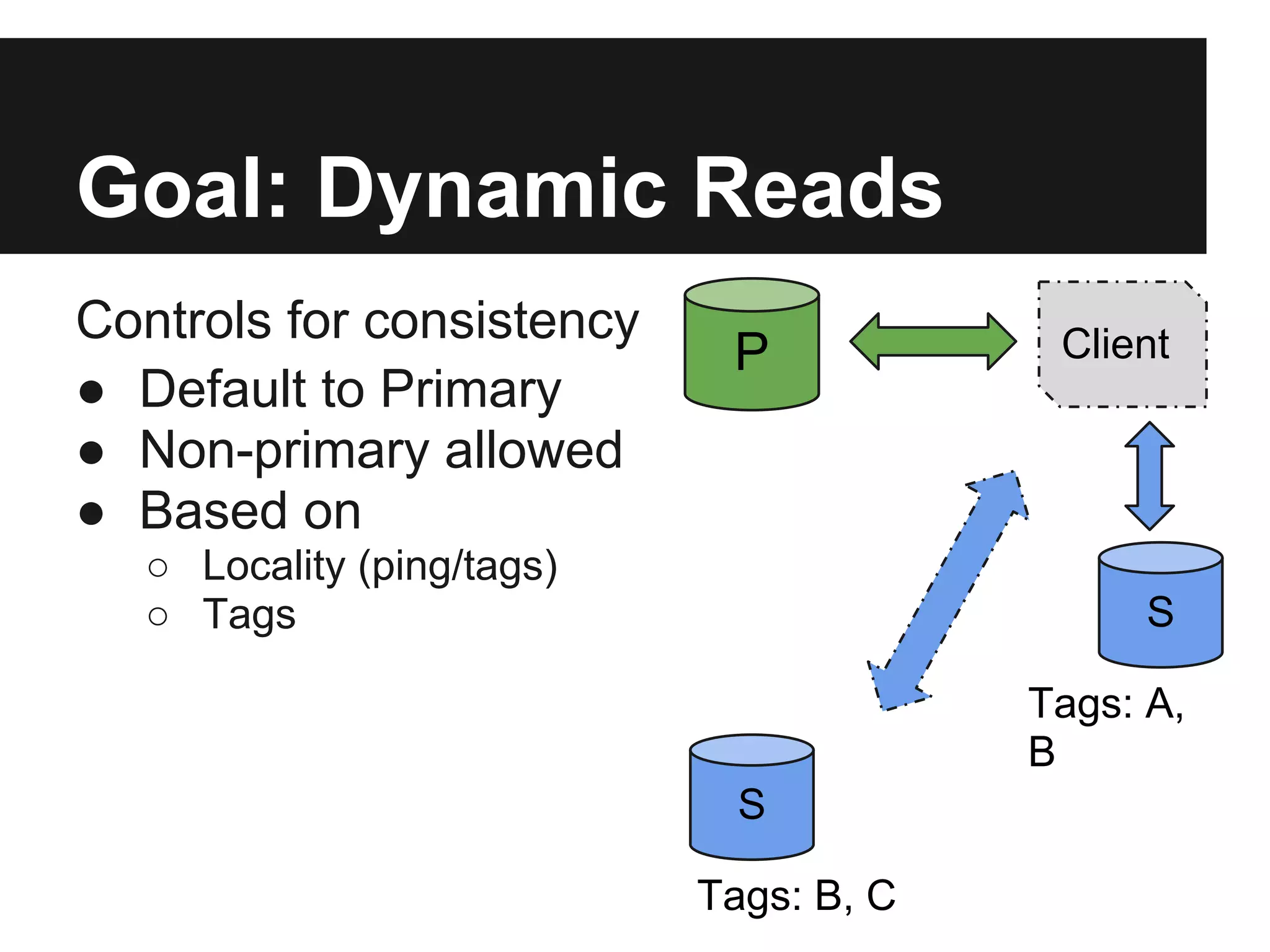





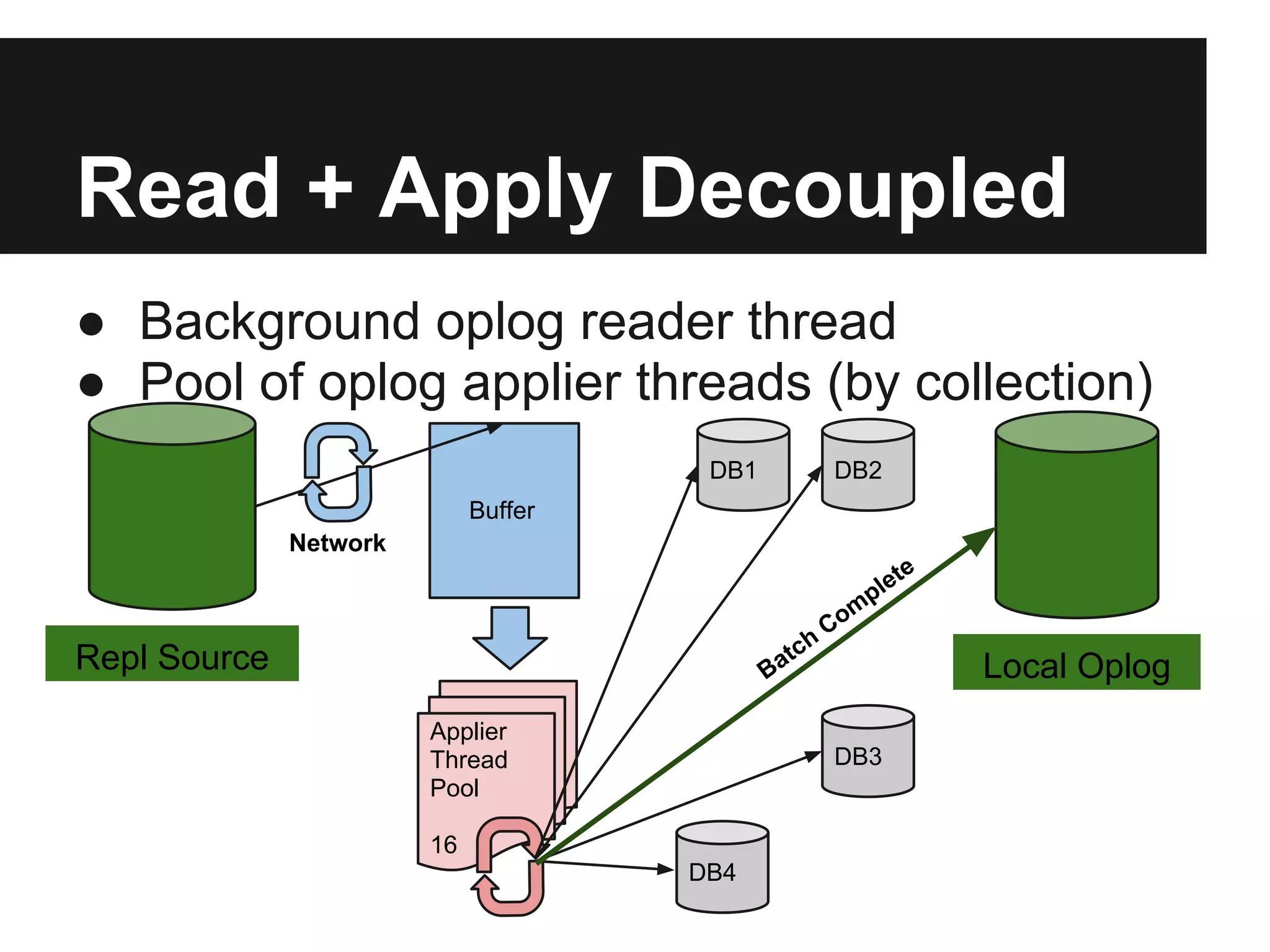
The document outlines the design and goals of an advanced replication system focusing on high availability, consistent data, automatic failover, and dynamic read capabilities across multi-region deployments. It details operational aspects including node redundancy, record operations, election processes for primary nodes, and client discovery methods. Additionally, the document highlights replication metrics and exceptional conditions that need to be addressed for maintaining system integrity and performance.























![[DSC] Introduction to Binary Exploitation](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontobinaryexploitation-210201095832-thumbnail.jpg?width=640&height=640&fit=bounds)






















































