






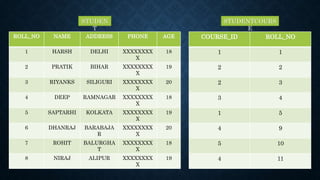












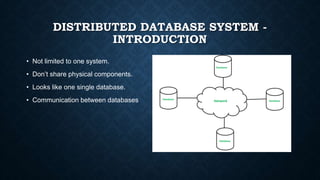






The document provides an overview of database management concepts, focusing on joins, sorting, and distributed database systems. It discusses various types of SQL joins (inner, left, right, and full), their syntax, and how to sort data based on columns or their numerical representation. Additionally, it covers the characteristics and advantages of distributed databases, including replication and fragmentation techniques.
































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)
