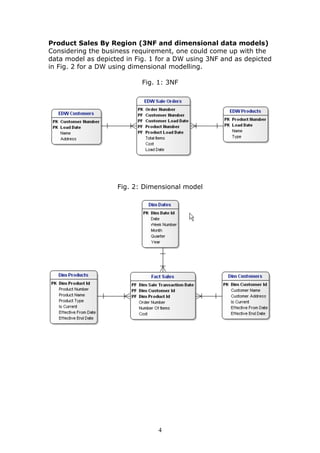
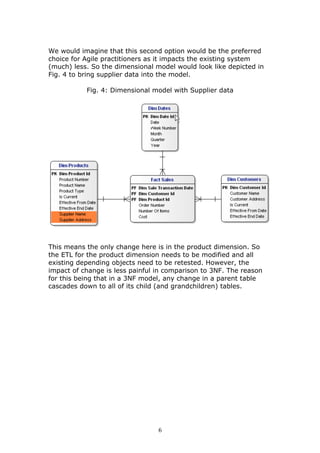
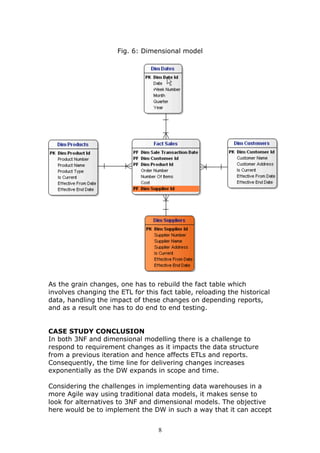
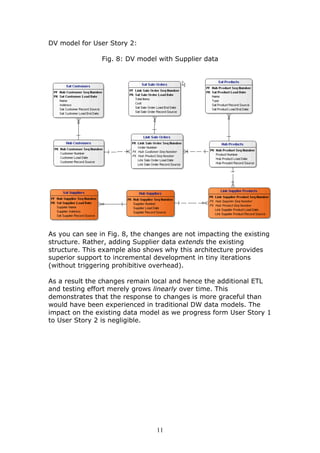
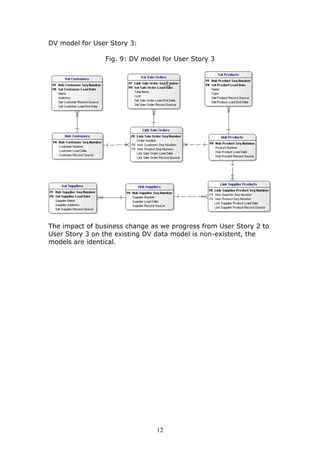
This document discusses adapting data warehouse architecture to benefit from agile methodologies. It presents a case study comparing traditional 3NF and dimensional data models to the Data Vault model. The case study shows that traditional models have challenges responding to changing requirements, while the Data Vault model more gracefully accommodates changes with minimal impact to the existing structure. The document concludes that agile development can be successfully adapted to data warehousing by using a hyper-normalized central hub like Data Vault that is resilient to changes in requirements.