Downloaded 117 times







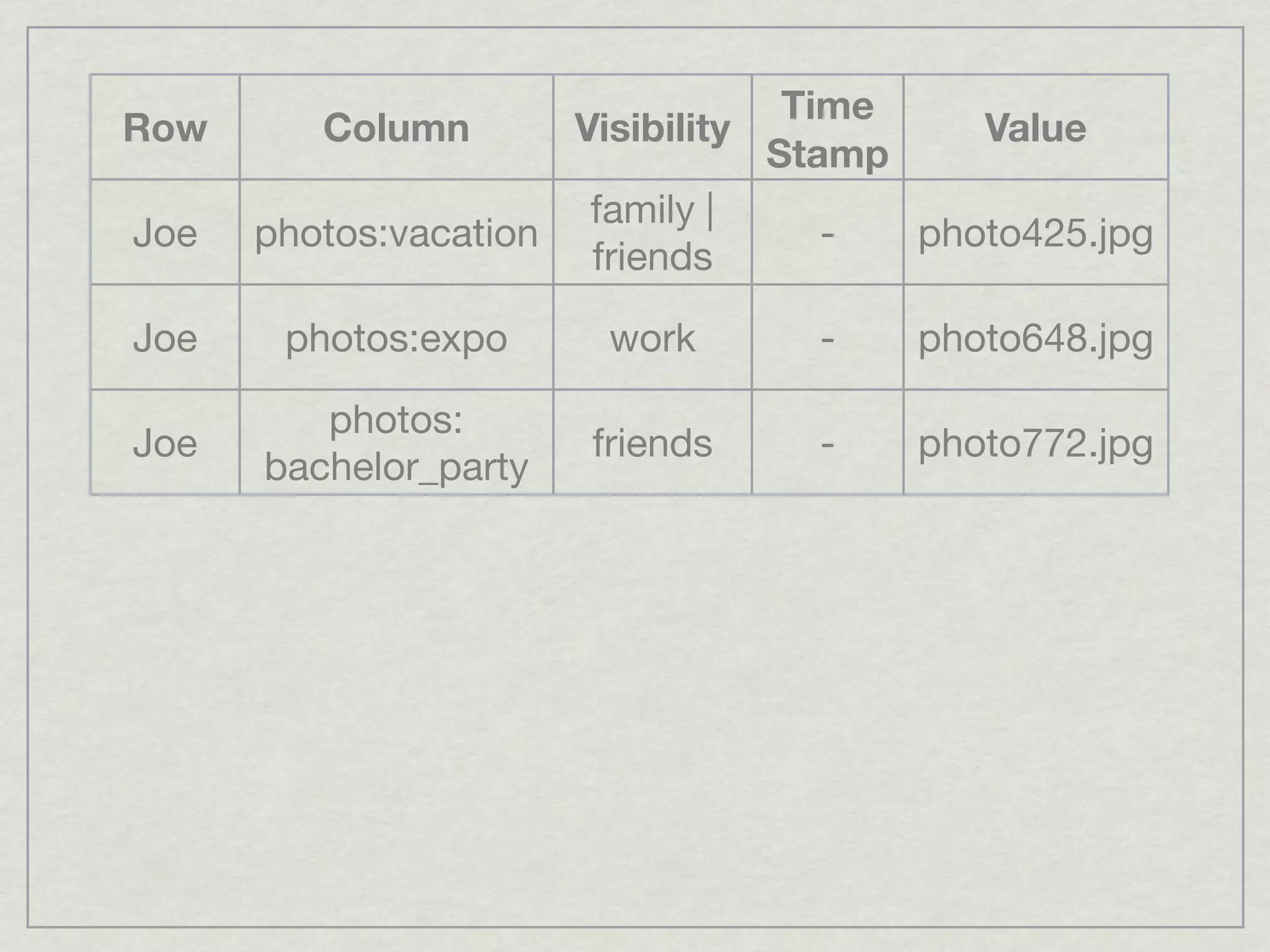
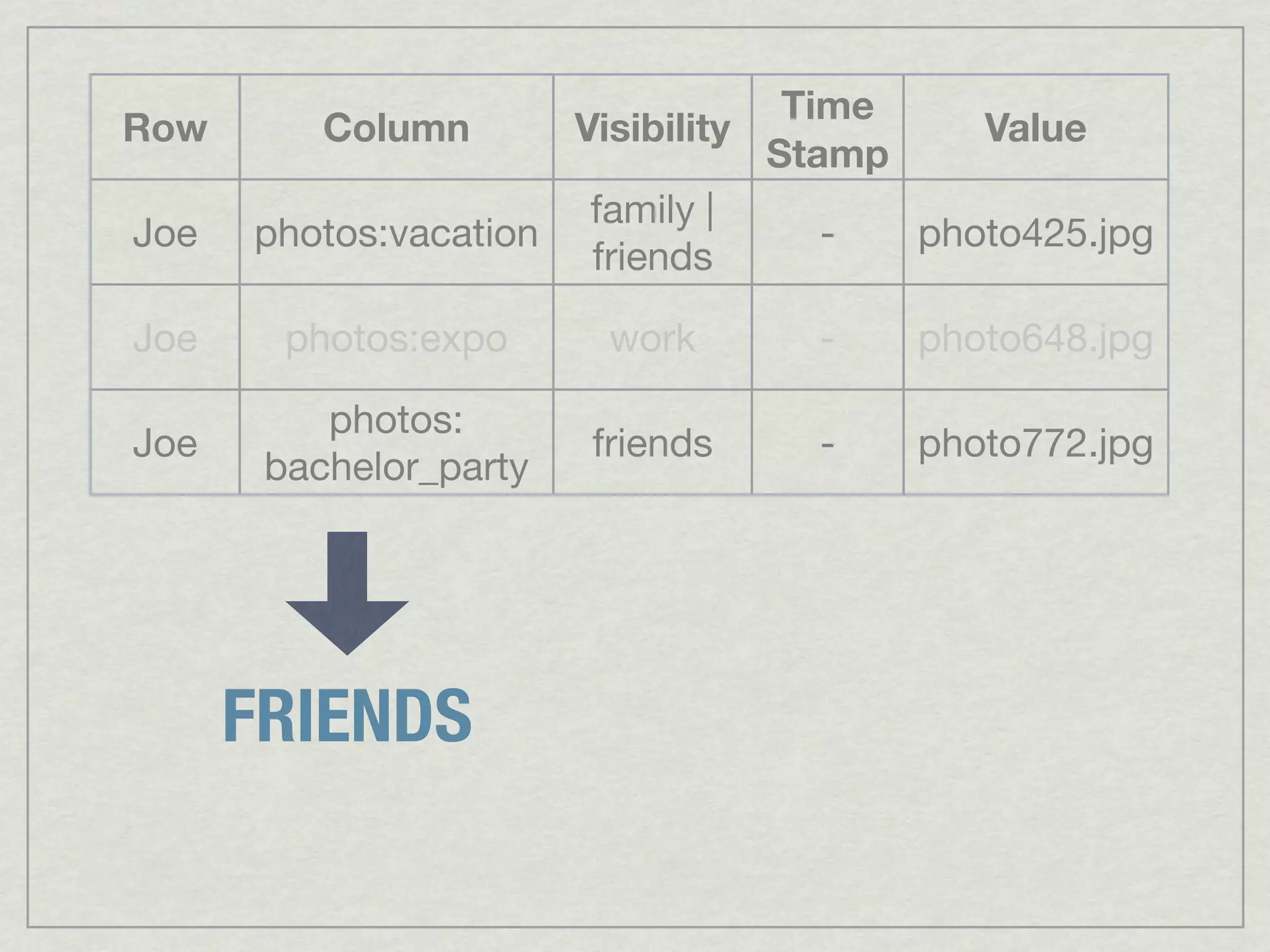
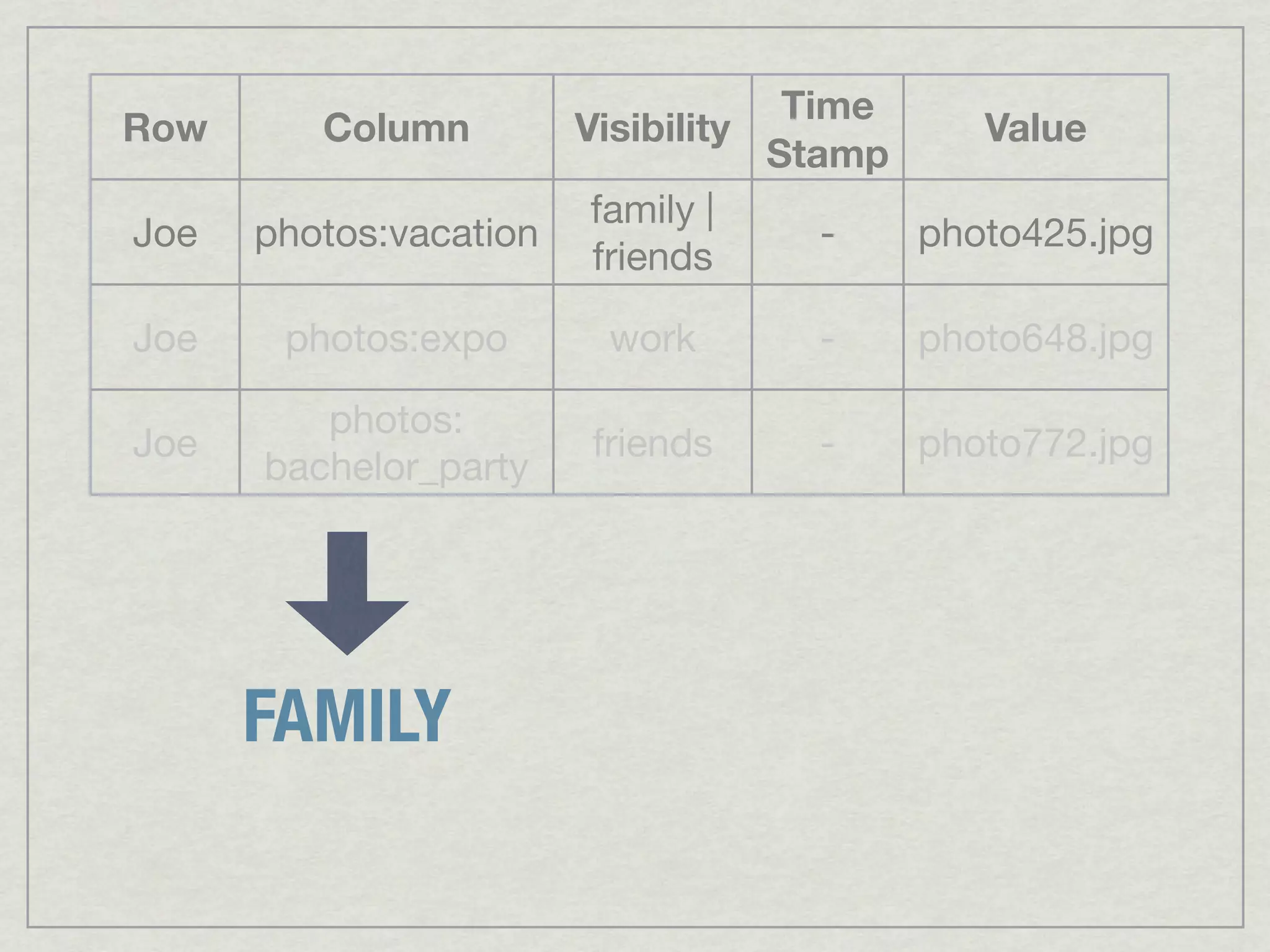
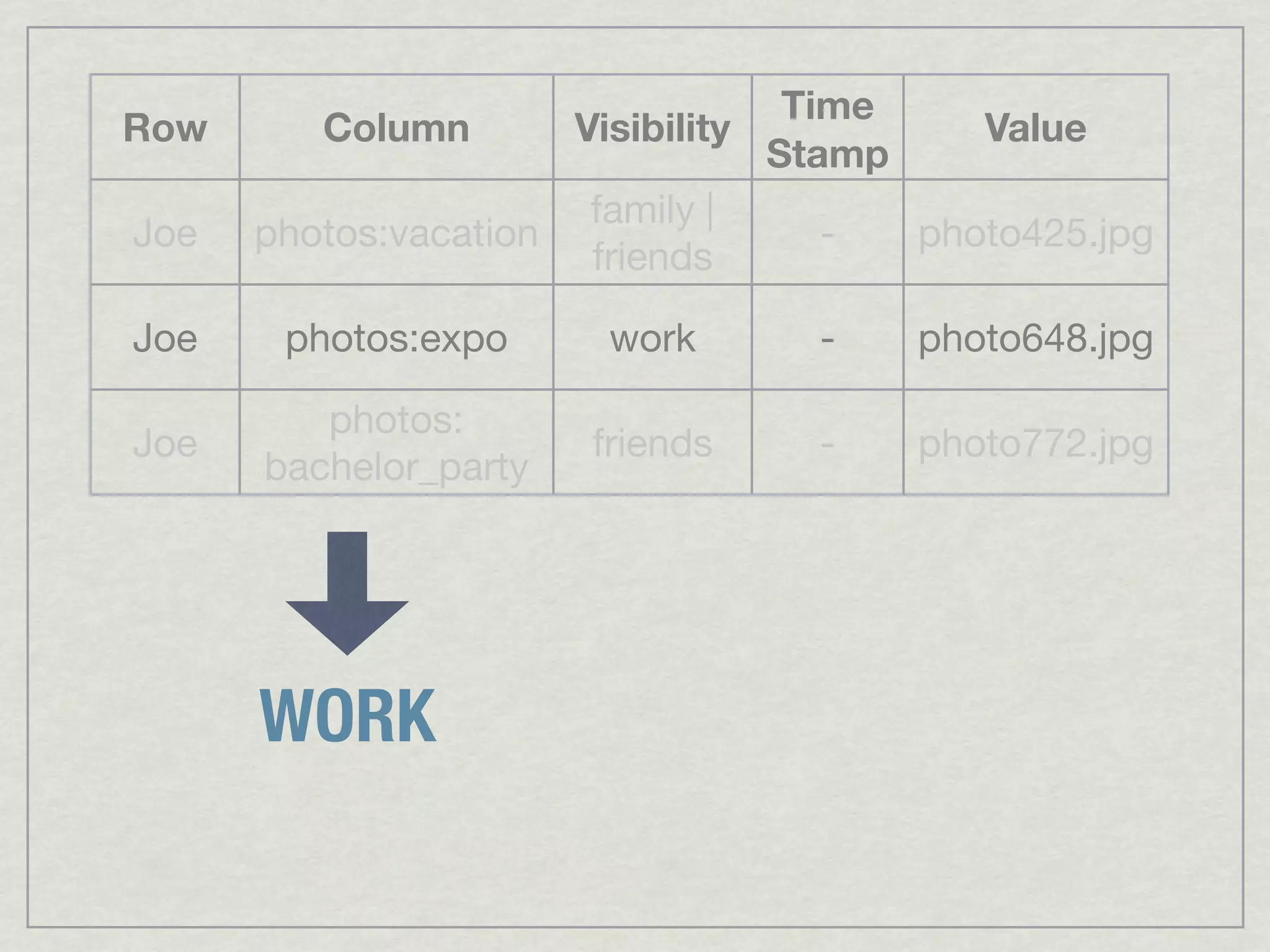


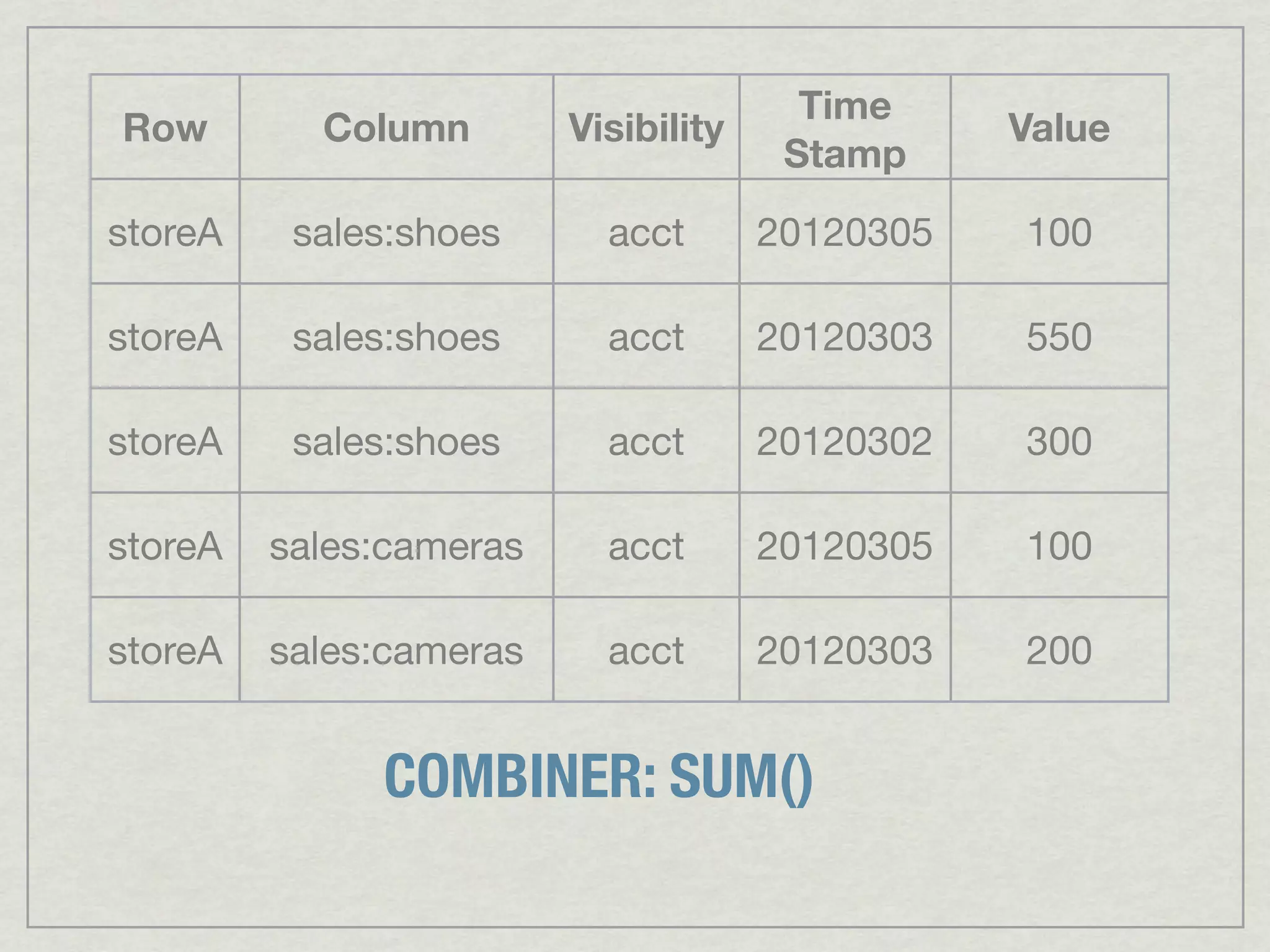








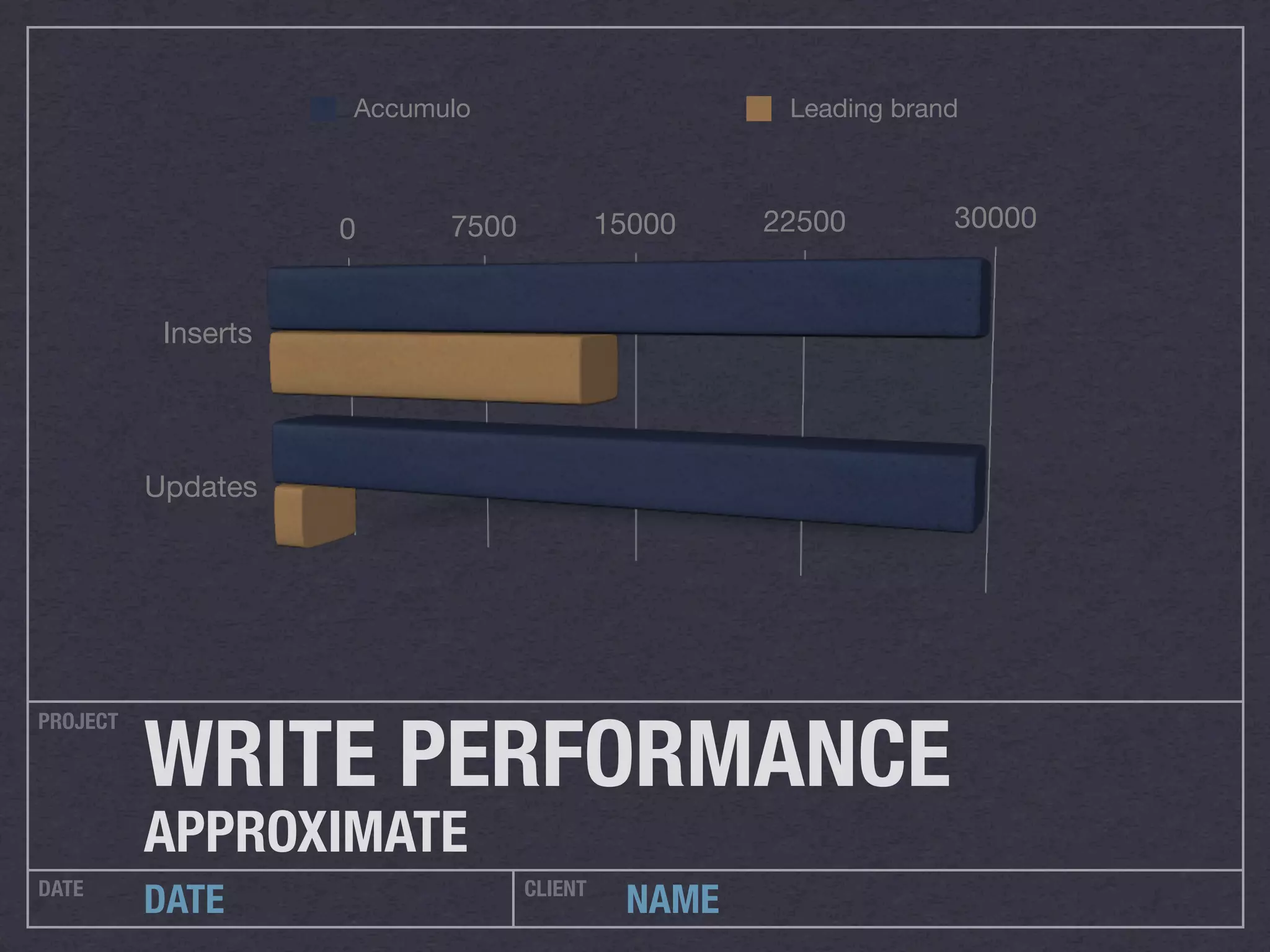








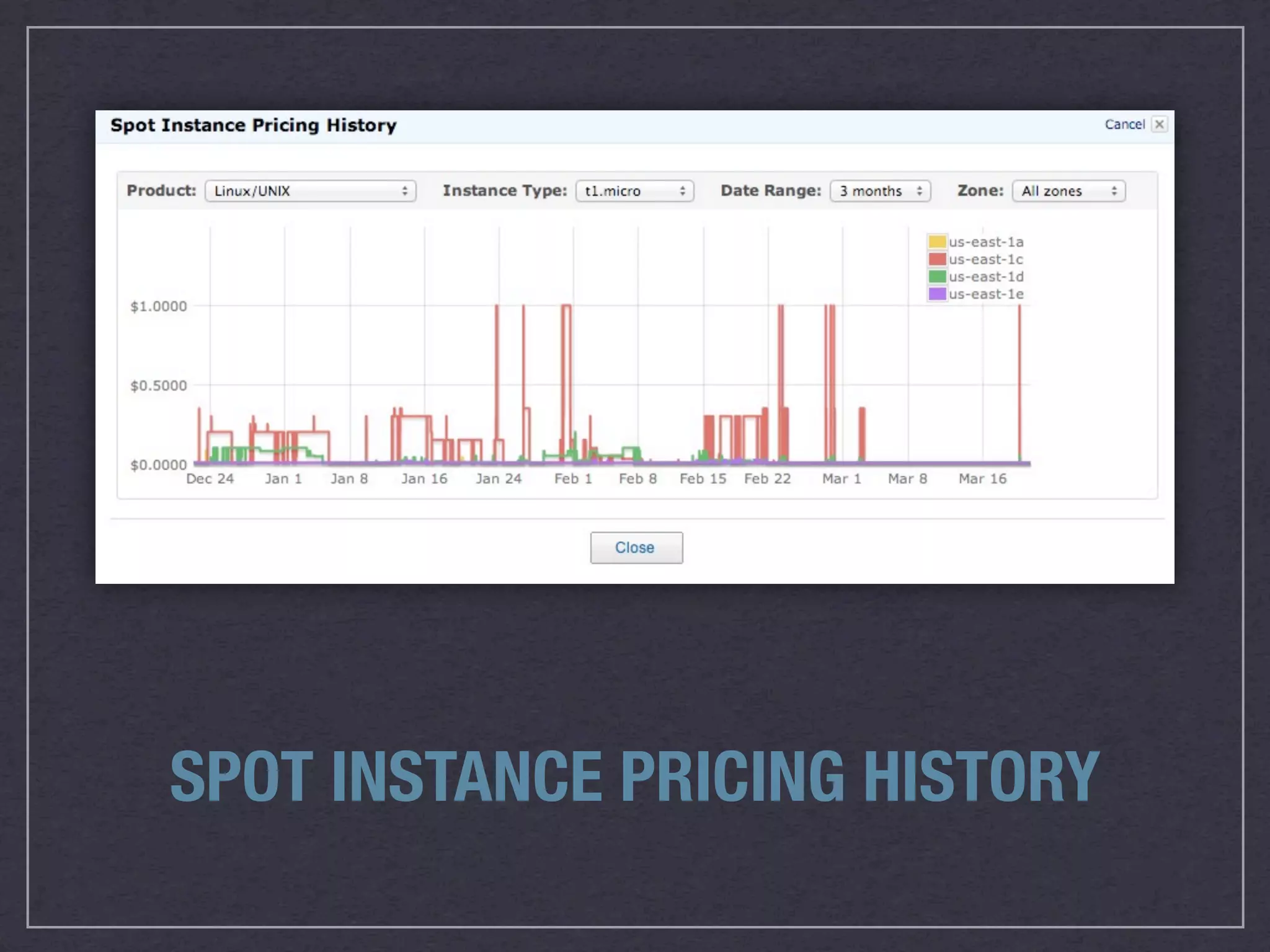









































































































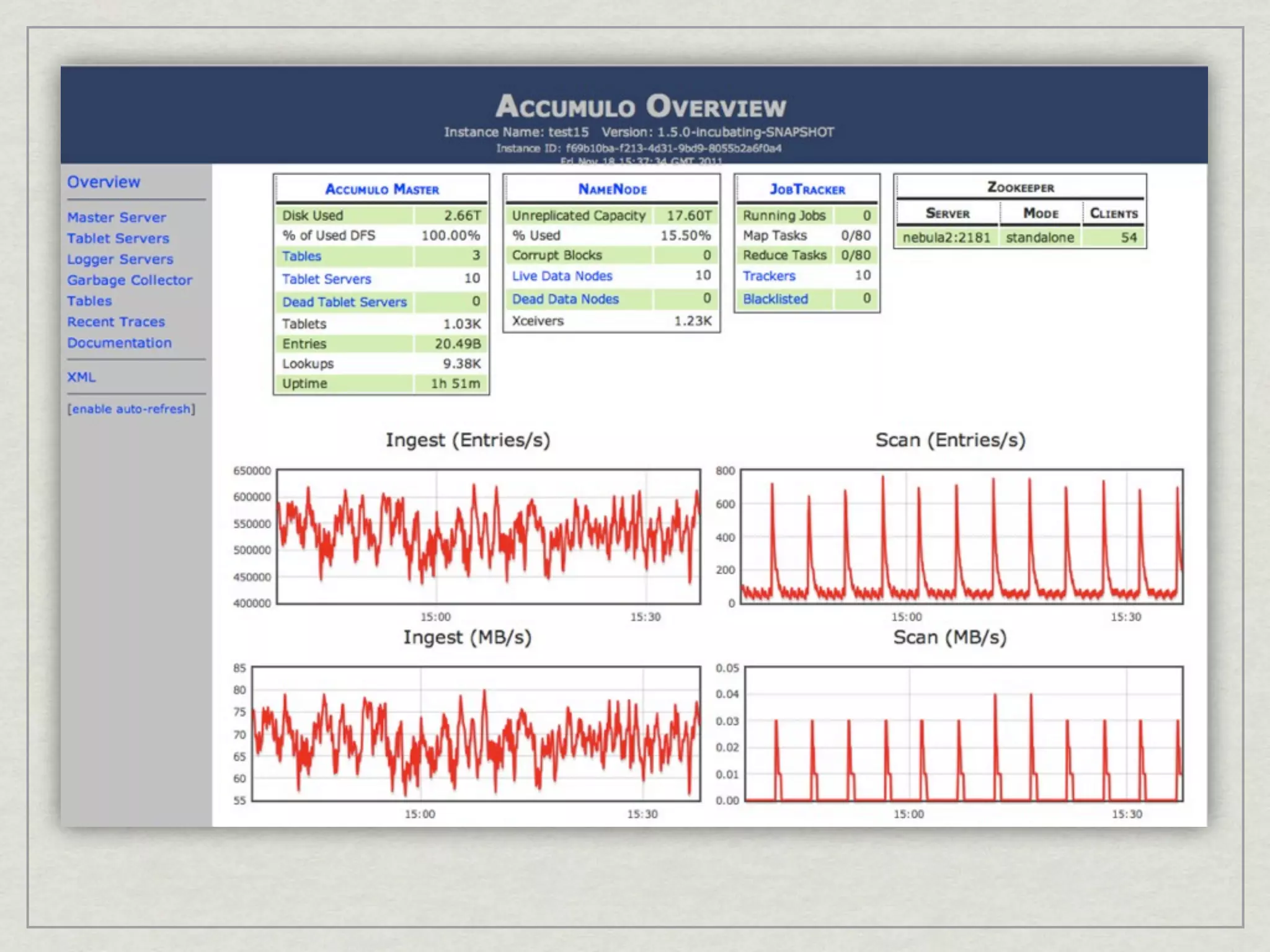

















This document discusses running Apache Accumulo, a distributed key-value store, on Amazon's Elastic Compute Cloud (EC2). It provides details on instance types and configurations for Accumulo and Hadoop on EC2, including software, ports, and security groups. It also covers scaling the Accumulo cluster on EC2 by provisioning new instances, handling failures automatically, and scaling down by removing instances. The document shows Accumulo can scale to handle over a million writes per second on EC2 and that clients see no errors when machines fail or are added.




















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













