Download as PDF, PPTX




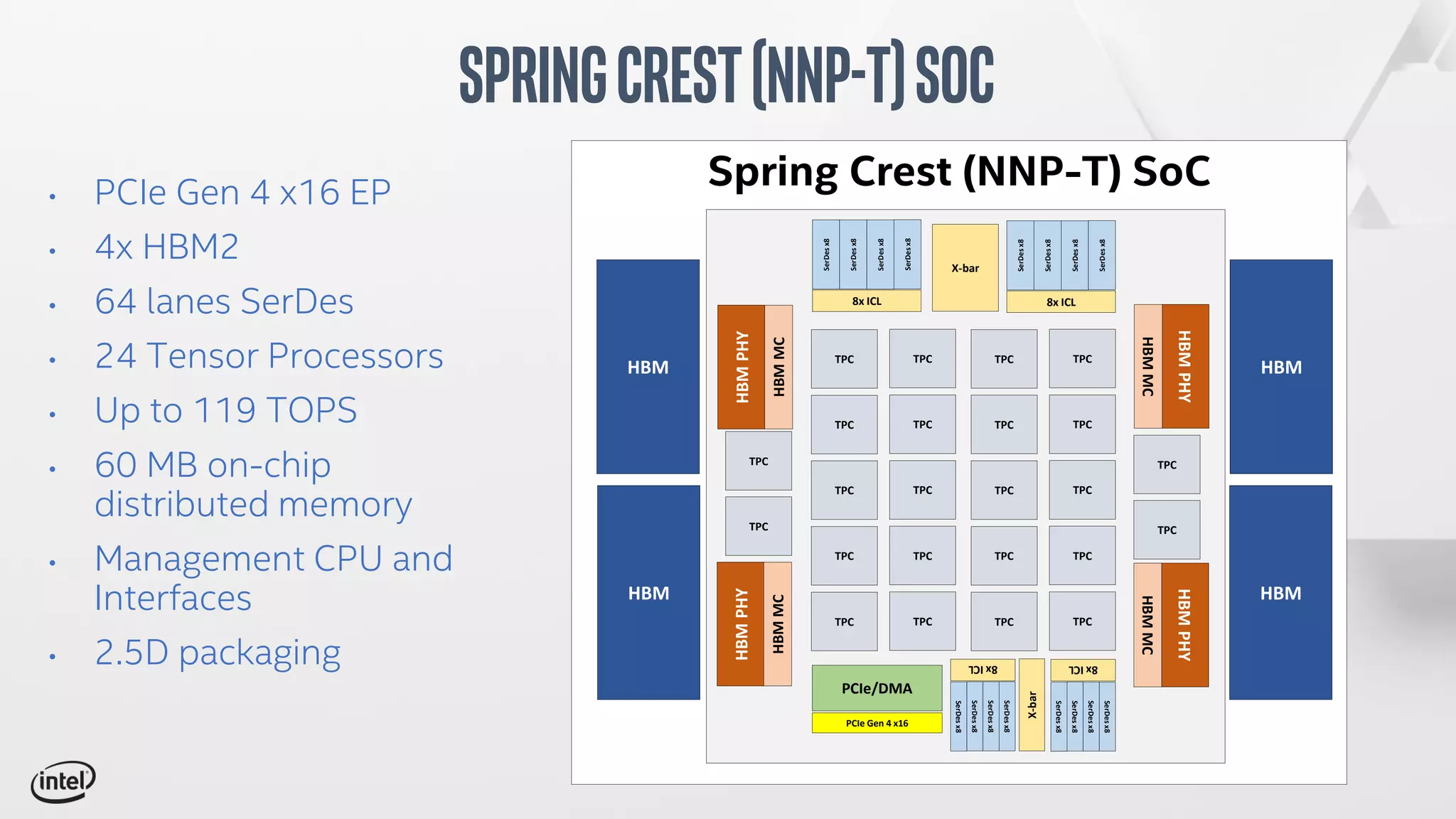



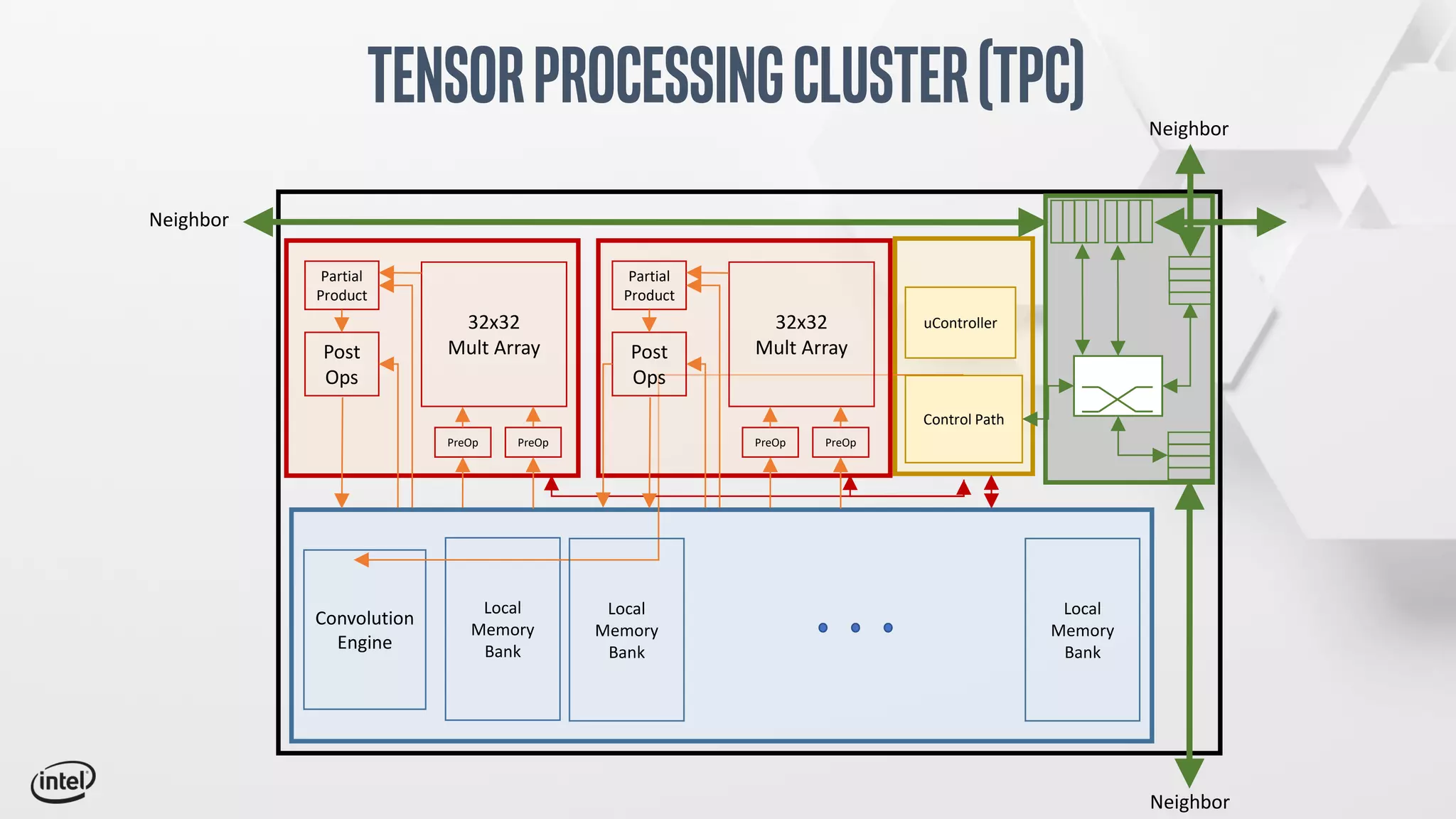
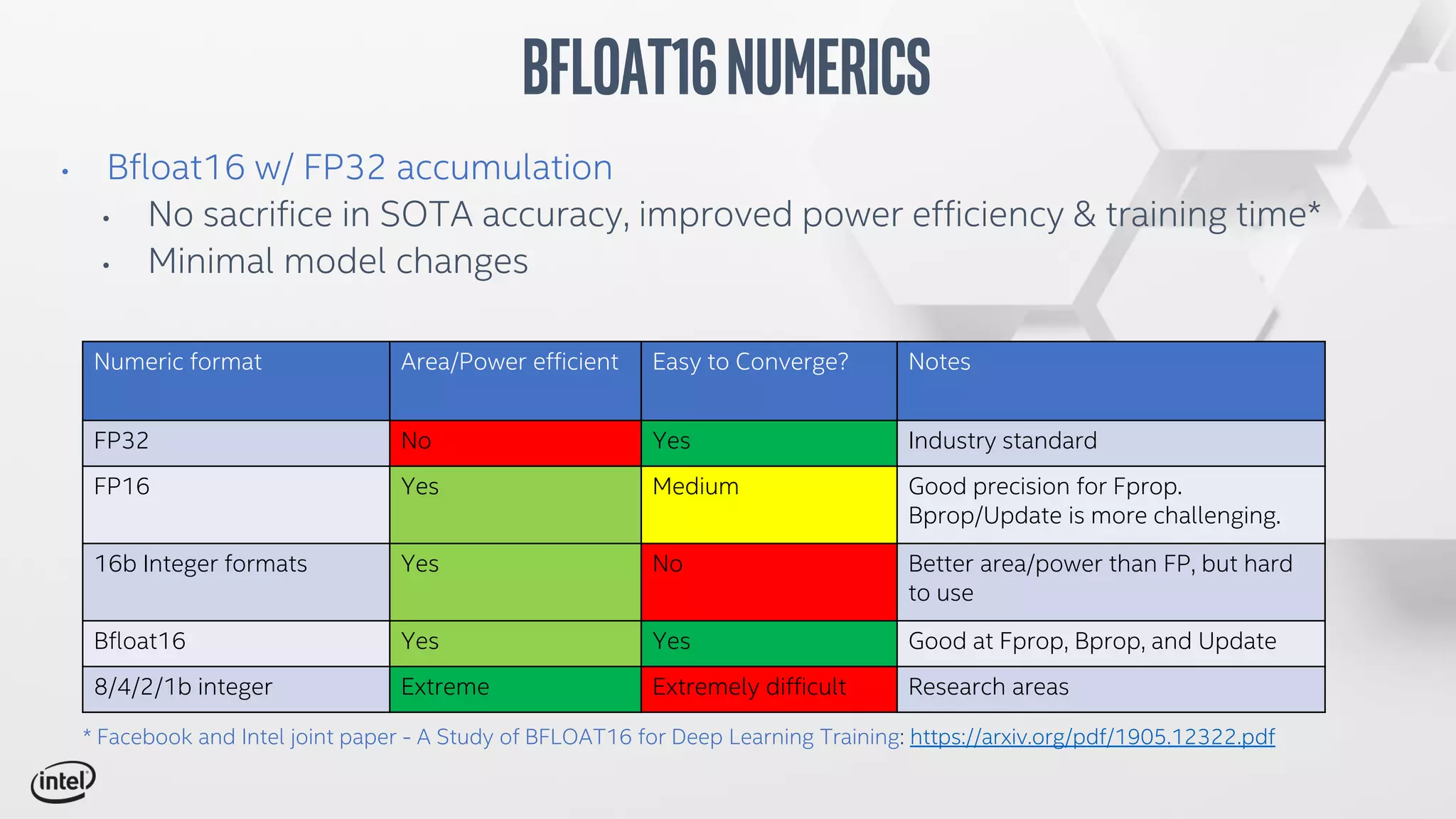


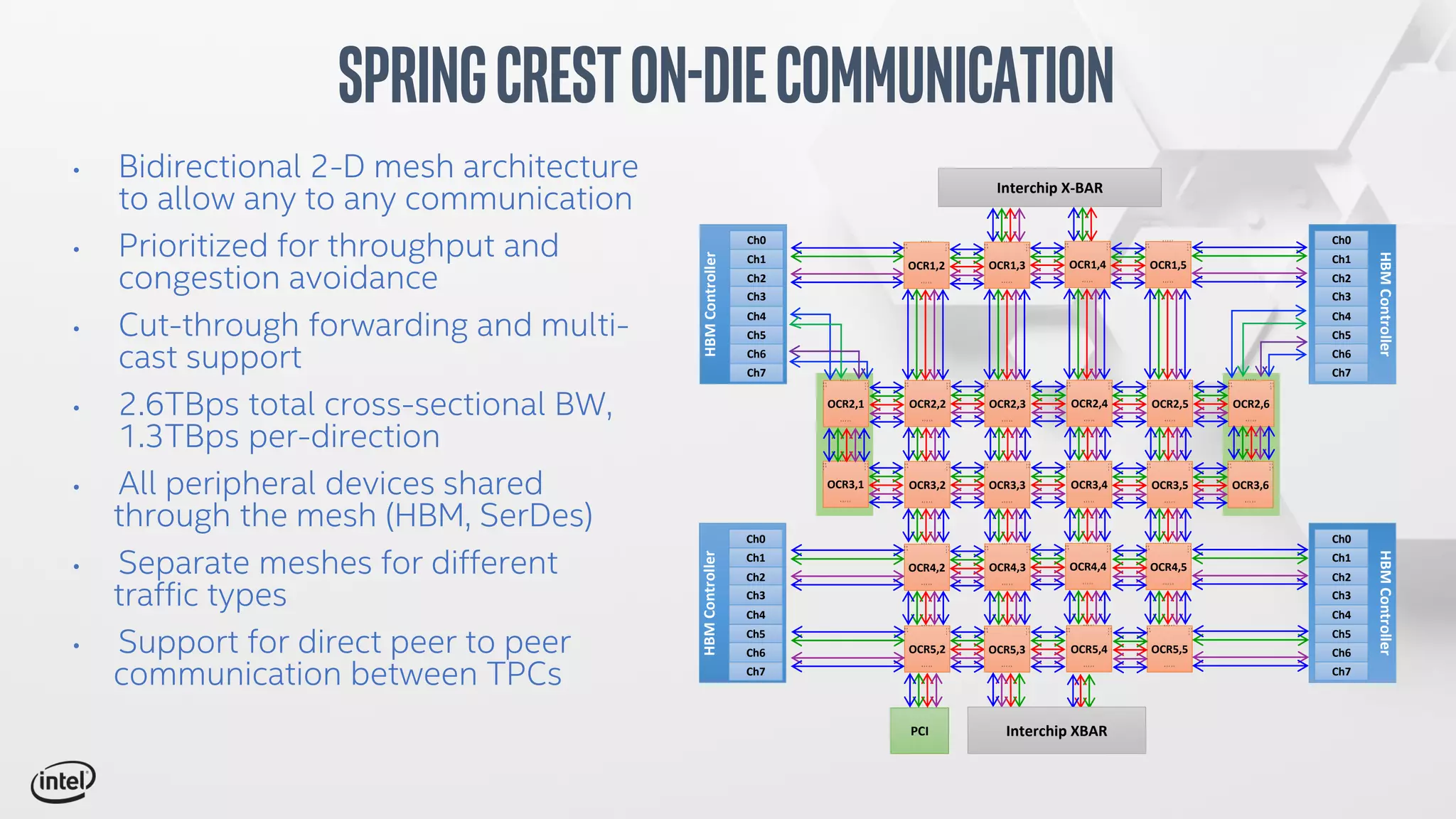




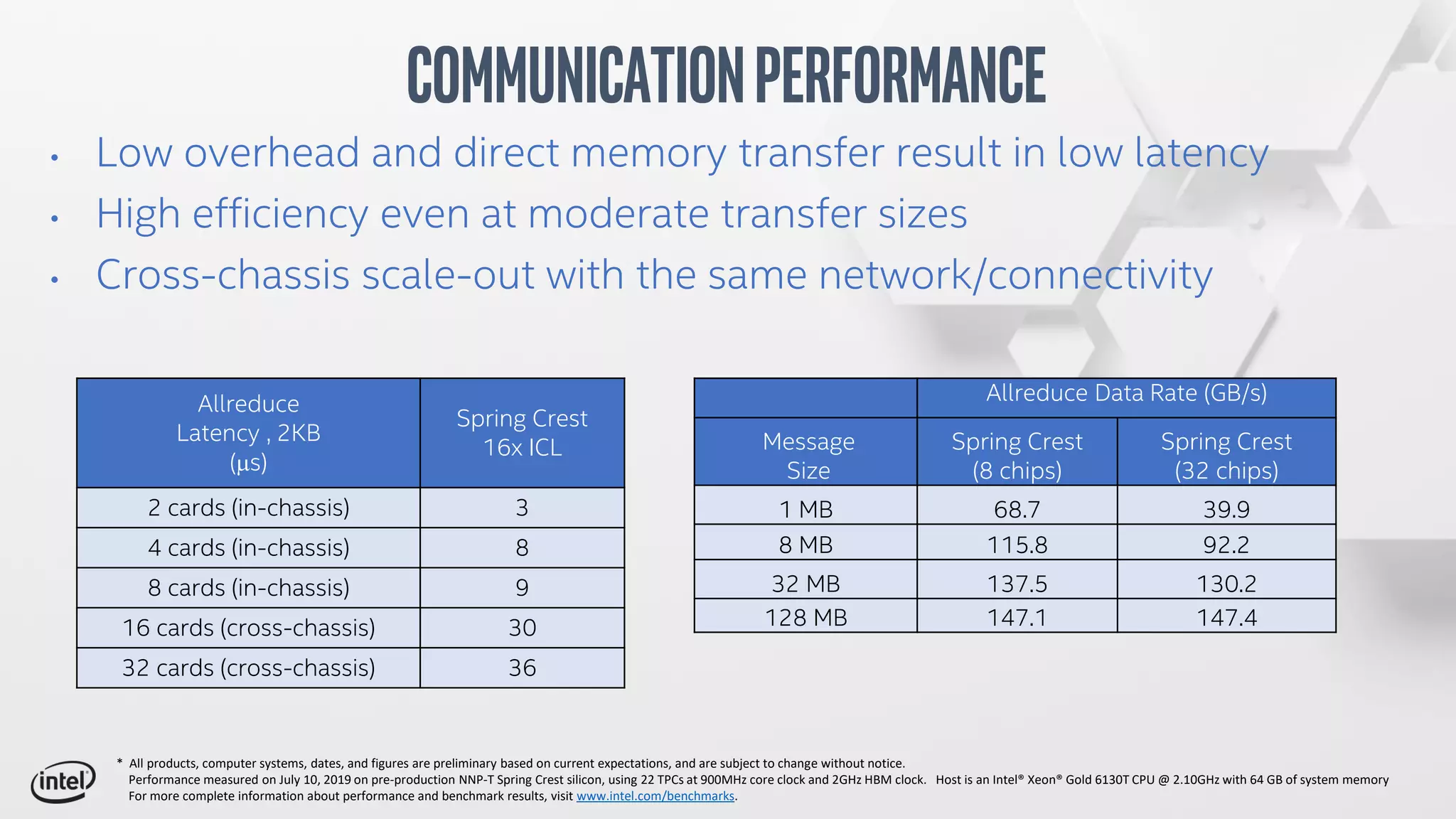



The document discusses Intel's Spring Crest deep learning accelerator, the Nervana NNP-T, detailing its architecture, performance metrics, power efficiency, and software stack. It emphasizes factors such as compute, memory, and communication for deep learning training at scale, alongside specific design features and benchmark results. Additionally, it provides legal disclaimers related to product performance and forward-looking statements, indicating that specifications are subject to change.






















![No[1][1]](https://cdn.slidesharecdn.com/ss_thumbnails/no11-1196304497535347-2-thumbnail.jpg?width=640&height=640&fit=bounds)
































































