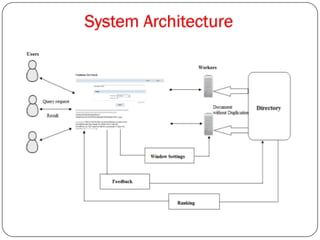
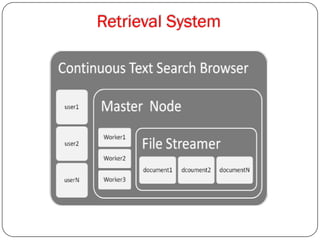
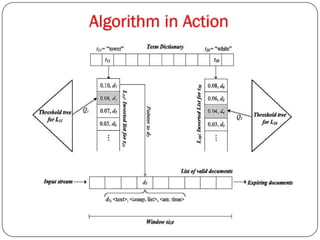
The document proposes an architectural model for continuously retrieving relevant updated data from text streams using MapReduce techniques. It aims to address issues with existing systems that find it tough to monitor data streams, are time consuming with only servers able to process, require scanning entire document sets, and may retrieve duplicate documents. The proposed system uses multiple worker nodes running an incremental threshold algorithm to compute the k most relevant documents for a query in a distributed manner.



























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










