Download to read offline



![Solution 1 [Masada+ 14]
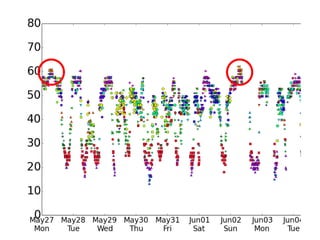
• We take intuition from topic models
in text mining.
–The data set of each day should be
modeled as a mixture of many
different speed distributions.](https://image.slidesharecdn.com/masadafdse2015-160316144912/85/FDSE2015-6-320.jpg)
![Latent Dirichlet Allocation (LDA) [Blei+ 03]
• LDA achieves a word token level clustering.
• Not a document level clustering
• Each document is modeled as a mixture of
many different word probability distributions.
topic <-> word probability distribution
document <-> topic probability distribution](https://image.slidesharecdn.com/masadafdse2015-160316144912/85/FDSE2015-7-320.jpg)
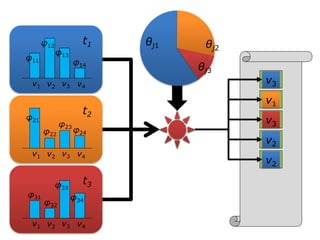

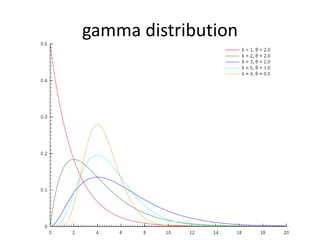

![Full joint distribution
• We estimated parameters by a variational
Bayesian inference. [Masada+ 14]](https://image.slidesharecdn.com/masadafdse2015-160316144912/85/FDSE2015-12-320.jpg)

![Solution 2 [Masada+ FDSE15]
• We use metadata in topic models.
–time points
–geographic locations](https://image.slidesharecdn.com/masadafdse2015-160316144912/85/FDSE2015-14-320.jpg)





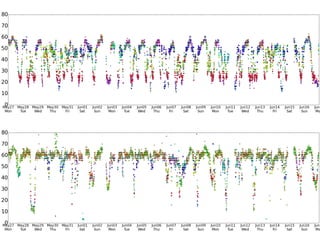
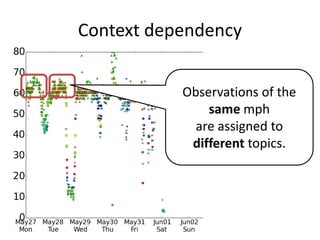
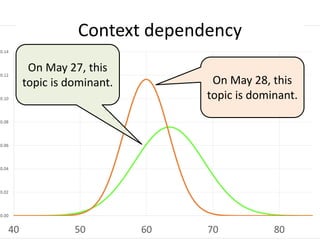

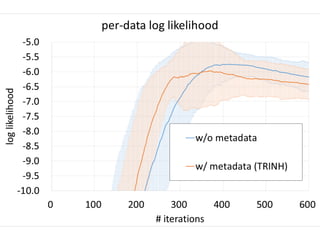





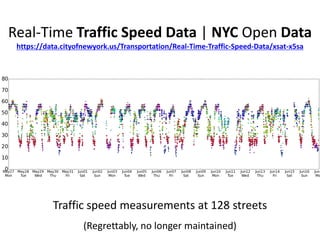
This document summarizes a hierarchical topic modeling approach for analyzing traffic speed data. The model treats each day's data as a mixture of different speed distributions. It extends latent Dirichlet allocation to model speeds as continuous gamma distributions rather than discrete words. The model further incorporates metadata on time of day and sensor location to make topic probabilities dependent on context. Model parameters are estimated using variational Bayesian inference, and the model achieves better performance than alternatives by capturing similarity between observations based on timing and location.





























































































