Downloaded 22 times


![Outline
Introduce
Types of Indexes
– Single-level Ordered Indexes
– Multilevel Indexes
– Dynamic Multilevel Indexes Using B-Trees and B+-Trees
Using indexes on MySQL
Reading: [1]chap. 5+6(13+14)
http://dev.mysql.com/doc/refman/5.5/en/optimizatio
2
Hệ quản trị CSDL @ BM HTTT](https://image.slidesharecdn.com/5-131208204802-phpapp02/85/5-indexing-2-320.jpg)






















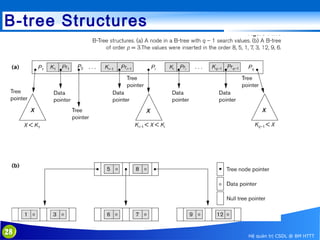
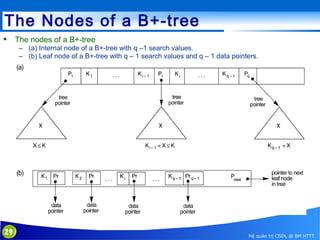

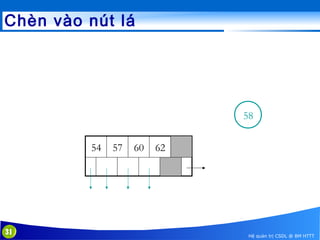
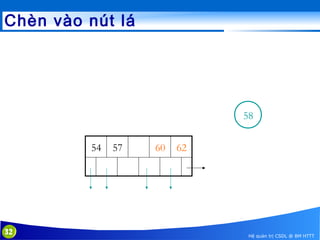
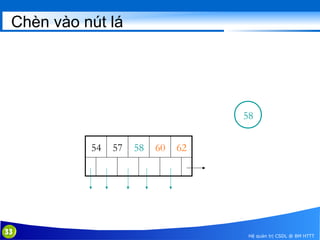
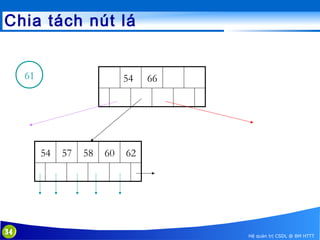
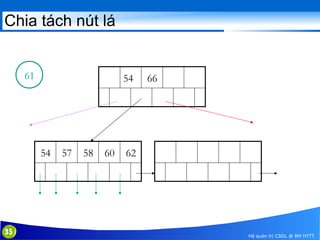
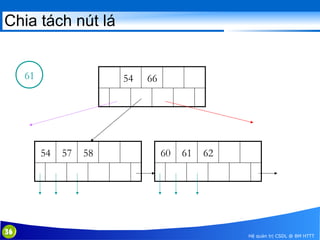
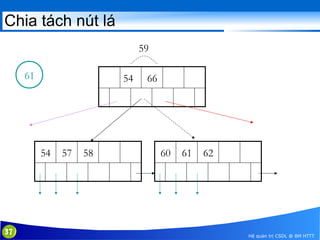
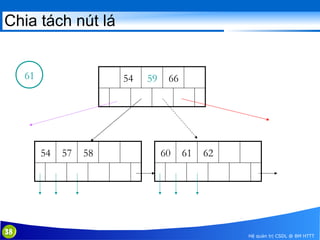
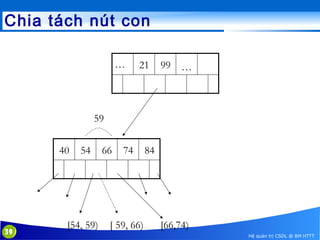
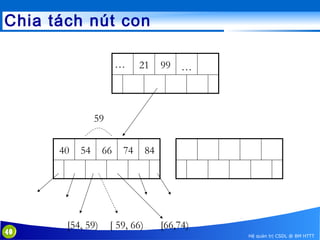
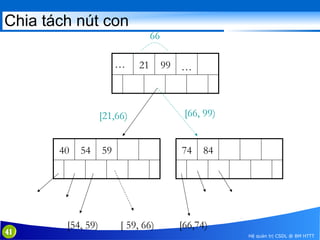
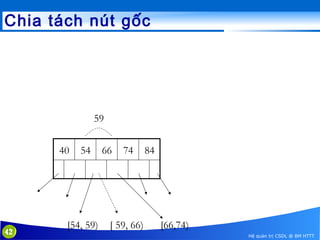
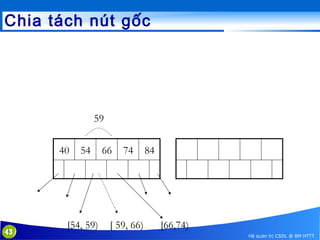
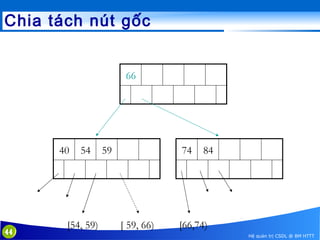

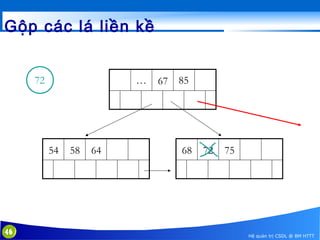
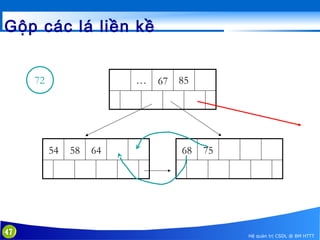
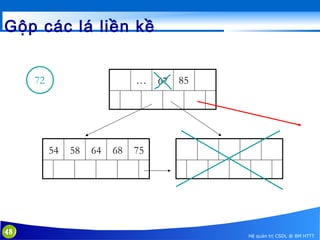
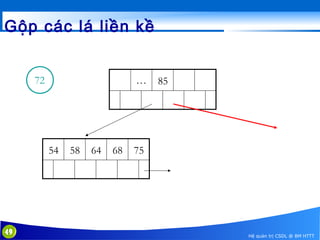












This document discusses database indexing and how indexes are used in MySQL. It begins with an introduction to indexing and describes several types of indexes, including single-level ordered indexes, multilevel indexes, and dynamic multilevel indexes using B-trees and B+-trees. It then provides examples of how to create and use indexes on tables in MySQL, including creating indexes on single or multiple columns and viewing existing indexes. The document aims to explain how database indexes improve query performance in MySQL.