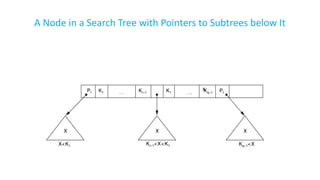
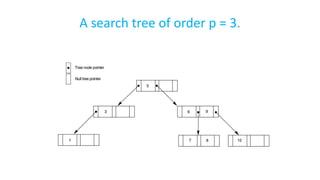
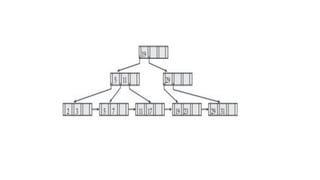
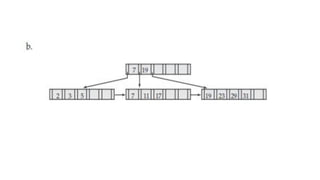
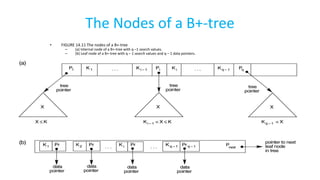
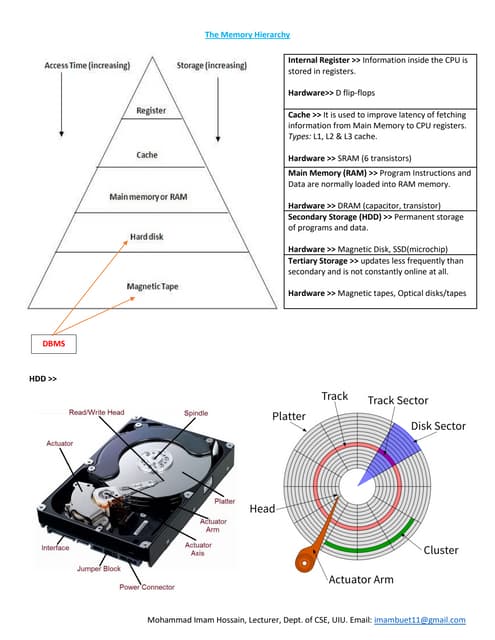
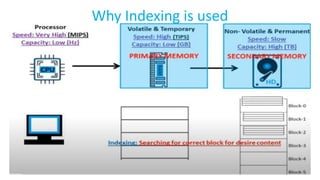
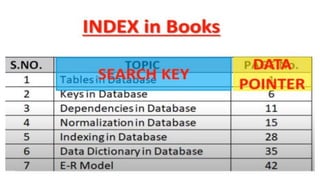
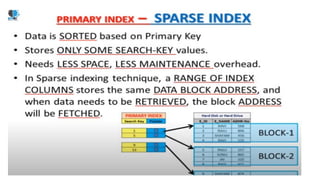
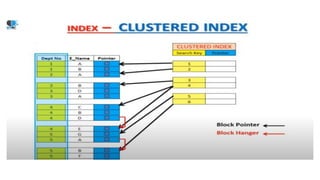
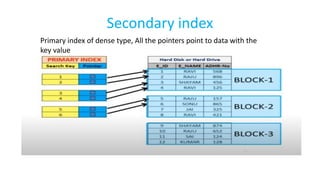
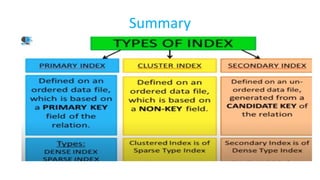
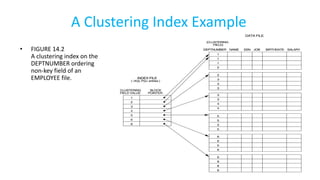
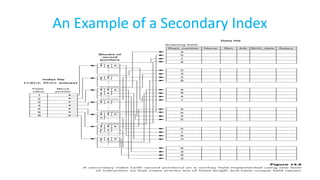
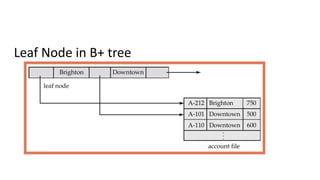
The document discusses various indexing structures for database files, including single-level indexes like primary, clustering, and secondary indexes, as well as multi-level indexes and their implementations using B-trees and B+-trees. It explains the purposes of indexes as access paths to improve search efficiency, with distinctions between dense and sparse indexes and the implications of each type. Additionally, it covers the advantages and disadvantages of B+-trees, particularly their ability to maintain performance during insertions and deletions without requiring full file reorganization.
























![A B+
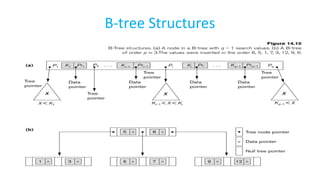
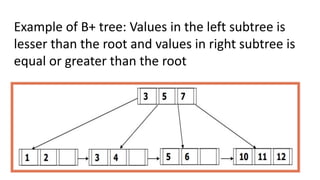
-tree is a rooted tree satisfying the following properties:
● All paths from root to leaf are of the same length
● Each node that is not a root or a leaf has between ceil[n/2] and n
children.
● A leaf node has between ceil[(n–1)/2] and n–1 values
● Special cases:
○ If the root is not a leaf, it has at least 2 children.
○ If the root is a leaf (that is, there are no other nodes in the tree), it
can have between 0 and (n–1) values.](https://image.slidesharecdn.com/doc-20240804-wa0006-240804122207-7209d70a/85/DOC-20240804-WA0006-pdforaclesqlindexing-35-320.jpg)
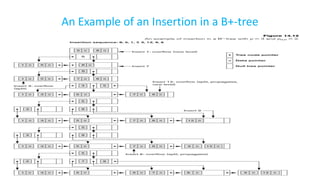
![Insertion in a full node (Overflow) at leaf level: keep ceil[n/2] keys in the
first node; remaining keys in the new node ; copy the smallest value of the
new node into the parent node.
Insertion in a full node at non-leaf level: keep ceil[n/2] keys in the original
node; move the smallest of the remaining values to the root and put
remaining values in the new node.
NOTE: Keys are inserted in serial order in B and B+ trees.](https://image.slidesharecdn.com/doc-20240804-wa0006-240804122207-7209d70a/85/DOC-20240804-WA0006-pdforaclesqlindexing-36-320.jpg)