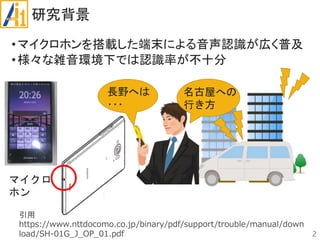
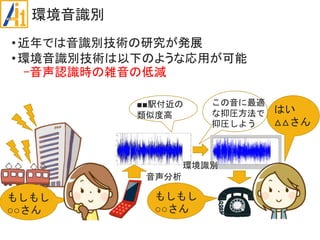
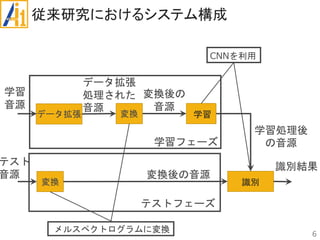
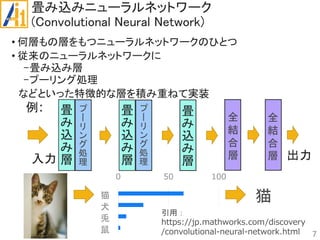
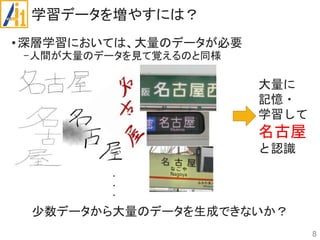
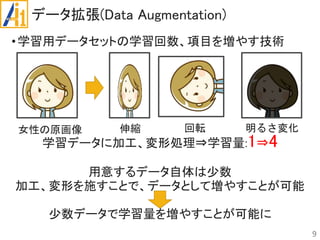
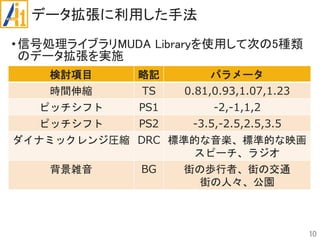
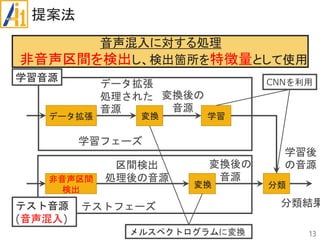
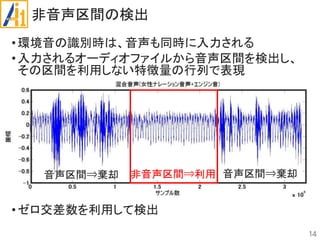
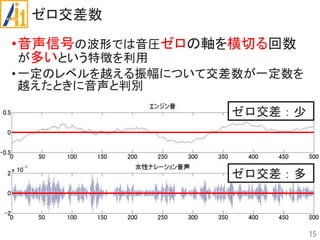
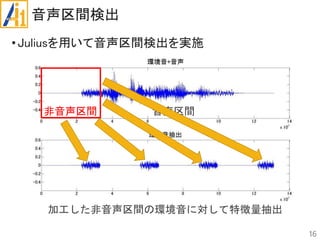
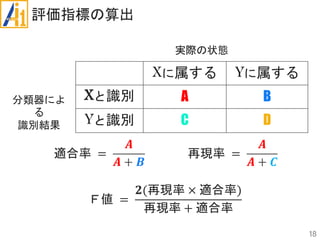
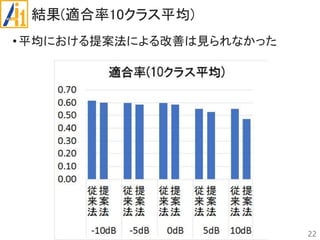
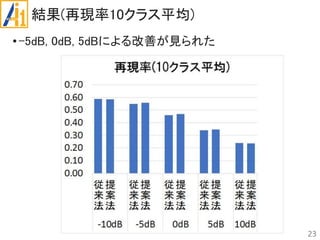
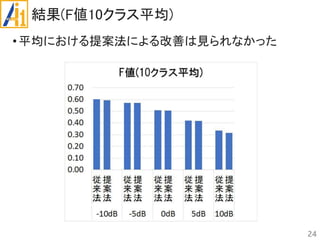
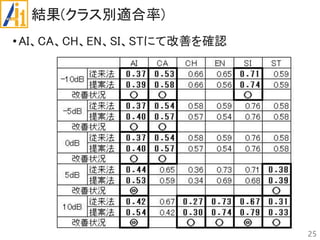
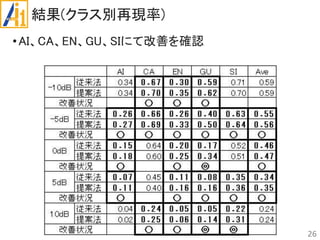
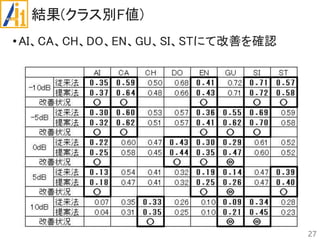
従来研究
Deep Convolutional NeuralNetworks and Data
Augmentation for Environmental Sound Classification
(J. Salamon 2016)
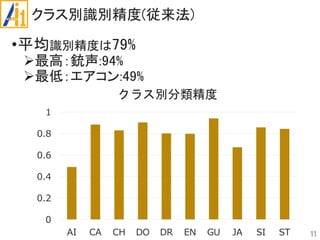
•学習・識別
CNN(畳み込みニューラルネットワーク)を使用
•平均識別率が約79%
データ拡張を導入
5
#22 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#23 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#24 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#25 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#26 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#27 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#28 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#29 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#30 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#51 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#52 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。
#63 Each environmental audio signal was segmented into several sub-signals.
それぞれの環境オーディオ信号は各サブ信号に分割されている。
These sub-signals were randomly divided into five groups of equal sizes.
それらのサブ信号は同じサイズの5つのグループにランダムに分割されている。
Then, four arbitrarily selected groups were used for training and the rest was used for testing.
次に任意に選ばれた4つのグループはトレーニング用に用いられ、その残りはテスト用に用いられた。
For the cross-validation procedure, the same process was repeated 50 times with different training and test sets to ensure that all samples are included in the test set at least once.
交差検証の手順では、全ての標本が少なくとも1度は含むように保証するため、異なるトレーニングとテストセットで50回同じプロセスを繰り返した。
Two classifiers, feedforward neural network and k-nearest neighbor (k-NN), were deployed in this experiment.
2つの分類器、フィードフォワードニューラルネットワークとk近傍法(k-NN)は、この環境にて展開(配置)される。