Download as PDF, PPTX
![cvpaper.challenge
Twitter@CVPaperChalleng
http://www.slideshare.net/cvpaperchallenge
MAILTO: cvpaper.challenge[at]gmail[dot]com](https://image.slidesharecdn.com/201610deepsurvey2016-161103084610/85/2016-10-cvpaper-challenge2016-1-320.jpg)


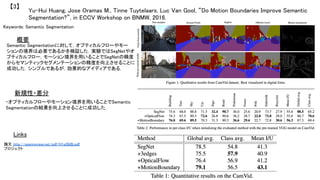





![Toshisada Mariyama, Kunihiko Fukushima, Wataru Matsumoto, “Automatic Design of Neural Network
Structures Using AiS”, in ICONIP, 2016.
【9】
Keywords: Add-if-Silent, Neocognitron
概要
・AiS(※右記)により中間層のニューロン数を決定し,浅い
ニューラルネットワークを自動設計する.
・Bike Sharing Datasetを用いた実験で,適切なネットワーク構
造を決定できることを確認.
Links
論文
http://link.springer.com/chapter/10.1007/978-3-319-46672-9_32
https://books.google.co.jp/books?
id=UfUqDQAAQBAJ&printsec=frontcover&hl=ja
新規性・差分
・AiSの最適なパラメータを学習データを元に決定する手法を
提案.
・活性化関数にRBF (Radial Basis Function) を使用し,AiSを
回帰問題に適用.
※AiS (Add-if-Silent):
「前シナプス側に反応している細胞があるのに,すべての後シナプス側の細
胞が無反応であれば,新しい細胞を回路内に発生させるという教師なし学習
則」( https://www.jstage.jst.go.jp/article/fss/30/0/30_318/_pdf )
Source: [K. Fukushima, NN2013]](https://image.slidesharecdn.com/201610deepsurvey2016-161103084610/85/2016-10-cvpaper-challenge2016-10-320.jpg)

![René Ranftl,Vibhav Vineet, Qifeng Chen Vladlen Koltun, “Dense Monocular Depth Estimation in Complex
Dynamic Scenes”, in CVPR, 2016.
【11】
Keywords:depth estimation, monocular camera, optical flow field, motion segmentation, moving object
新規性・差分
概要
・動物体を含む複雑なシーンに対し、単眼カメラ画像から密な
デプスを推定する手法の提案
・まず、2枚の連続画像から生成したオプティカルフローフィール
ドに対し、提案アルゴリズムを用いて複数のモーションモデル
に分割する。次に、凸最適化問題を解いて、検出された各物体
のスケールを決定し、シーンを再構成する。
・従来のStructure From Motion(SFM)は動物体に課題。
multibody SFMでは動物体を剛体と仮定。non-rigid SFMでは物
体形状、軌跡に制約あり。本手法では複数の動物体を含むダ
イナミックなシーンに適用可
・Kitti dataset, MPI Sintel datasetを用いて定性・定量評価を実
施。Depth Transfer[project page]などの既存手法に比べ相対
精度等の各評価指標で優位
Links
論文
http://www.cv-foundation.org/openaccess/content_cvpr_2016/
papers/Ranftl_Dense_Monocular_Depth_CVPR_2016_paper.pdf
プロジェクト
http://vladlen.info/publications/dense-monocular-depth-
estimation-in-complex-dynamic-scenes/](https://image.slidesharecdn.com/201610deepsurvey2016-161103084610/85/2016-10-cvpaper-challenge2016-12-320.jpg)





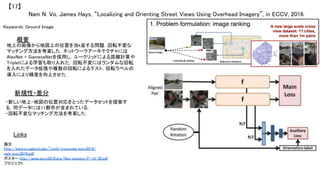






![Pavel Tokmakov, Karteek Alahari, Cordelia Schmid, “Weakly-Supervised Semantic Segmentation using Motion
Cues”, in ECCV, 2016.
【24】
Keywords: Weakly Supervised Semantic Segmentation
新規性・差分
概要
モーションや物体カテゴリの尤度マップを手掛かりとして,前景
領域のセマンティックセグメンテーションを弱教師付き学習の要
領で行う.右図が本論文の手法におけるオーバービューであ
り,FCNN [Chen+, ICLR15]をベースとして,直感的にはEM-
algorithm的に解決する (E-stepはピクセルラベルの推定,M-
stepはbackpropによる最適化).学習ははYouTube Objects,
ImageNet Videos, Pascal VOC 2012より行った.
・画像に対する物体ラベルを入力として,弱教師付き学習によ
りセマンティックセグメンテーションを実施した.
・弱教師付き学習により,今後は膨大なデータによる学習が可
能である.
Links
論文 https://arxiv.org/pdf/1603.07188v2.pdf
ポスター http://www.eccv2016.org/files/posters/P-2B-40.pdf](https://image.slidesharecdn.com/201610deepsurvey2016-161103084610/85/2016-10-cvpaper-challenge2016-25-320.jpg)







cvpaper.challengeにて2016年10月にサーベイした論文のまとめです. Computer Visionの"今"をまとめています. cvpaper.challenge2016は産総研,東京電機大,筑波大学,東京大学,慶應義塾大学のメンバー約30名で構成されています. 2015年はCVPR2015の全602論文を読破し,PRMUにて論文調査からアイディア考案,論文化までをカバーする「DeepSurvey」を提案しました. 2016年は「1000本超の読破」と「コンピュータビジョンの上位会議への投稿」を目標に活動しております. Twitterで論文情報を随時アップしてます. Twitter: https://twitter.com/CVpaperChalleng 質問コメント等がありましたらメールまで. Mail : cvpaper.challenge@gmail.com






















![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)






































![[DL輪読会]Blind Video Temporal Consistency via Deep Video Prior](https://cdn.slidesharecdn.com/ss_thumbnails/20201030deepvideoprior-201030024757-thumbnail.jpg?width=640&height=640&fit=bounds)



