Download as PDF, PPTX


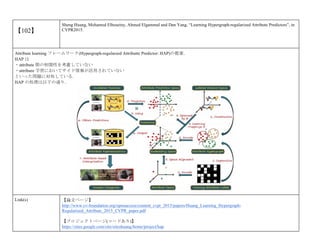


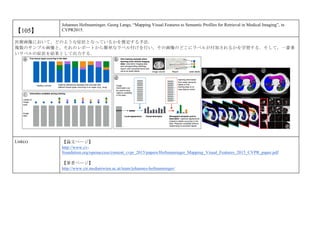

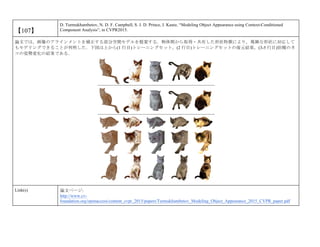
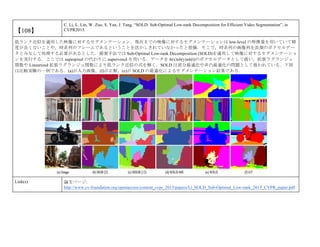
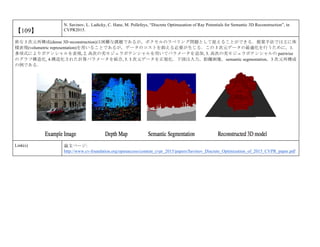
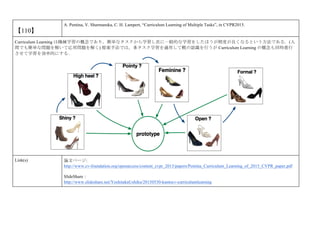



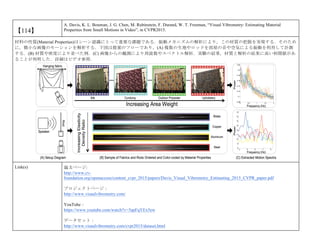


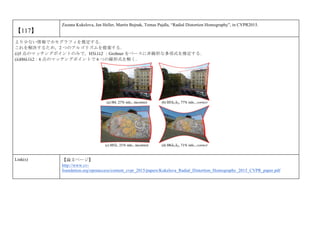


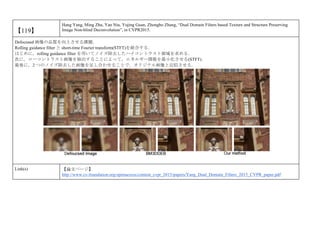



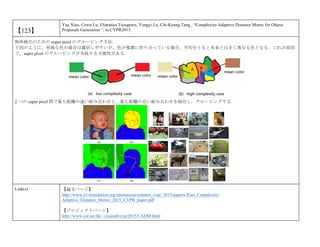


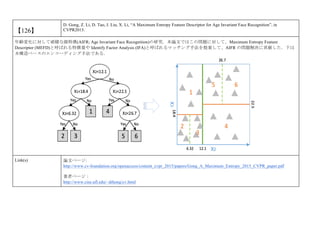
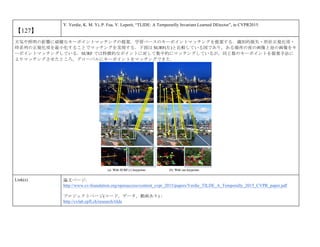
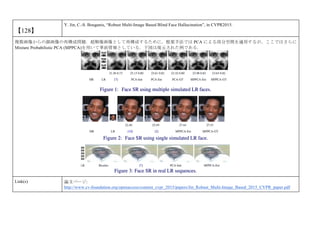


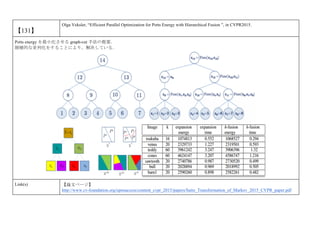


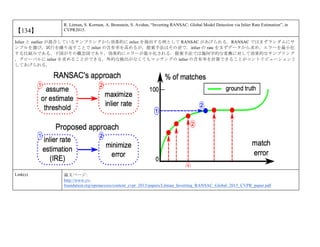

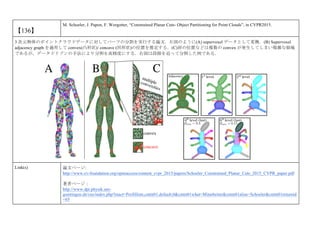






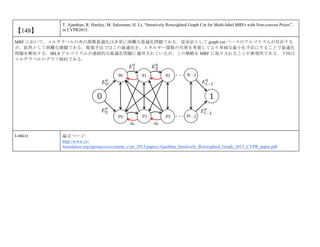
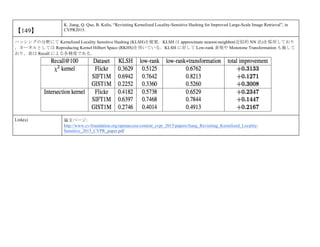
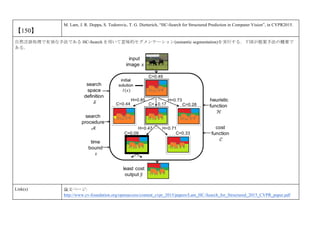


cvpaper.challengeにて8月にサーベイしたCVPR2015論文のまとめ(3/5)です. Computer Visionの"今"をまとめています. 産総研片岡裕雄(@HirokatuKataoka)と電機大中村研(http://www.is.fr.dendai.ac.jp/ )による合同プロジェクト「cvpaper.challenge」です. Twitterで論文情報を随時アップしてます. Twitter: https://twitter.com/CVpaperChalleng 質問コメント等がありましたらメールまで. Mail : cvpaper.challenge@gmail.com















































