Downloaded 34 times
![cvpaper.challenge
Twitter@CVPaperChalleng
http://www.slideshare.net/cvpaperchallenge
MAILTO: cvpaper.challenge[at]gmail[dot]com](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-1-320.jpg)
![cvpaper.challenge
Twitter@CVPaperChalleng
http://www.slideshare.net/cvpaperchallenge
MAILTO: cvpaper.challenge[at]gmail[dot]com](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/75/2016-07-cvpaper-challenge2016-1-2048.jpg)



![German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, Antonio M. Lopez, “The SYNTHIA
Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes”, in CVPR,
2016.
【5】
Keywords: Semantic Segmentation, Domain Adaptation, Transfer Learning
手法
結果
概要
・セマンティックセグメンテーション用に,CGによる仮
想世界データセットであるSYNTHIA Datasetを作成.
・実世界データと合わせることで大幅に精度向上.
・SYNTHIA Dataset:
- 季節・天気・照明条件・視点の変動を含む.
- pixel-levelのクラス情報とdepth情報を持つ.
・CNNは,T-Net[Ros+,arXiv2016] と FCN[Long+,CVPR2015] を使用.
・実世界データとCGデータを併用して学習するため,
BGC (Balanced Gradient Contribution) [Ros+,arXiv2016]を使用.
学習時の各batchは,実世界データ6枚とCGデータ4枚を含む.
・実世界データとCGデータを併用して学習することで,
実世界データのみで学習した場合と比較し精度向上.
(Camvid, KITTIの場合,Class Accuracyが10%前後向上.)
Links
論文 http://www.cv-
foundation.org/openaccess/content_cvpr_2016/papers/Ros_Th
e_SYNTHIA_Dataset_CVPR_2016_paper.pdf
プロジェクト・動画 http://synthia-dataset.net/dataset/
新規性・差分
・CGデータを用いた先行研究では,物体検出・姿勢推定・屋
内シーンのセマンティックセグメンテーションが行われてい
る.
・本論文は,都市環境のセマンティックセグメンテーション
におけるCGデータの有効性を示した.](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-6-320.jpg)
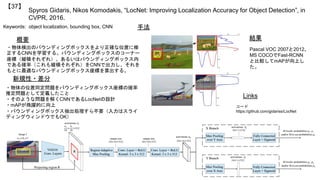
![German Ros, Simon Stent, Pablo F. Alcantarilla, Tomoki Watanabe, “Training Constrained
Deconvolutional Networks for Road Scene Semantic Segmentation”, in arXiv pre-print 1604.01545, 2016.
【6】
Keywords: Semantic Segmentation, Domain Adaptation, Transfer Learning, Distillation, Compression
手法
結果
概要
・転移学習による高精度・省メモリなセマンティックセ
グメンテーション用ネットワークであるT-Netを提案.
・ランタイム・メモリ使用量無視の高精度ネットワークである
S-Net(source network)を生成.
S-Netは,2つのFCN[Long+,CVPR2015]のアンサンブル.
・Distillation [Hinton+,arXiv2015] に類似した手法で,
SegNetと同様のネットワークT-Net (target network) に転移学習.
・WCE (weighted cross-entropy) を使用し,クラスごとのデータの偏りを考慮.
・異なるデータを統合したデータセットに適用するため,
BGC (Balanced Gradient Contribution)を使用.
・FCNの1%のメモリ使用量で,FCNを越える精度を達成.
(下図のT-Net TK-SMP-WCE)
Links
論文 http://arxiv.org/pdf/1604.01545v1.pdf
新規性・差分
・転移学習をセマンティックセグメンテーション用のネ
ットワークに適用・拡張し,有効性を確認.
・セマンティックセグメンテーション用のデータが少数
である問題を解決するため,既存データセットを統合し
たMulti-Domain Road Scene Semantic Segmentation
(MDRS3) datasetを作成.](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-7-320.jpg)





![Ruxin Wang et al., “ActivityNet Challenge 2nd prize of untrimmed video classification”, in CVPRW, 2016.
【12】
Keywords: ActivityNet Challenge, Action Recognition
新規性・差分
概要
行動認識の大規模データベースであるActivityNetのコンペティションにおいて、行動識別第二位の手法.
特徴抽出と特徴統合、探索の戦略により認識や検出を行った.ビデオの入力から特徴抽出(CNN+VLAD, ResNet-152
ImageNet Pre-trained model, Inception-v3, ResNet-152 PlaceNet Pre-trained model + PCA1024 dims)、IDT+Fisher
vector, Two-Stream Very Deep CNN (flow), C3Dのfc7,音声特徴であるMFCCを取得.
特徴統合にはMulti-view intact space learningを用いてintact spaceを理解 [multi-view intact space learning, PAMI2015].
Latent Intact Representationを1500次元に設定.
・ActivityNetの識別タスクにて第一位を獲得.mAPが92.413%, Top-1が87.792%,
Top-3が97.084%であった.
・Intact Space を導入して視点変化に対応した学習を実行した.
Links
プロジェクト http://activity-net.org/challenges/2016/](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-14-320.jpg)





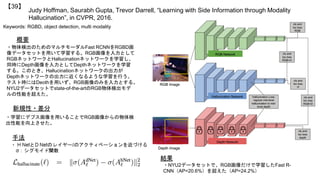
![Waqas Sultani, Mubarak Shah, “What if we do not have multiple videos of the same action? - Video
Action Localization Using Web Images”, in CVPR, 2016.
【18】
Keywords: Action Detection, Weakly Supervised Learning, Web Images
新規性・差分
概要
Web画像を用いた学習による,動画像からの行動検出に関する研究である.従
来ではある程度拘束があるビデオを用いるが,本論文では拘束がなく長時間の
ビデオからいかに人物行動のローカライズを行うかという設定で研究する.学
習にはキーワードベースの画像検索により収集した画像を,テスト時には行動
候補領域を抽出し,Web画像から収集した画像により学習された識別器により
行動検出を実行する.候補領域の抽出には[Cho+, CVPR15]を用いた.(1) キー
フレームからの候補領域やその特徴,(2) 相関行列とその平均の誤差,(3) 相関
行列の値を最小化するように条件付けして最適化.
・大規模な学習データが揃わずとも,キーワードベースに
より検索されたweb画像により学習した識別器でも高精度
な行動検出ができることが判明した.
・右下の表のように,UCF-Sportsデータに対して良好な
性能を実現した.THUMOSに対しても精度を算出した.
Links
論文
http://crcv.ucf.edu/papers/cvpr2016/CVPR16_Waqas_AL.pdf
ビデオ https://www.youtube.com/watch?v=99FE9XOeX-k
候補領域抽出 [Cho+, CVPR15]
http://www.di.ens.fr/willow/pdfscurrent/cho2015.pdf](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-20-320.jpg)



![Luis Herranz, Shuqiang Jiang, Xiangyang Li, “Scene Recognition with CNNs: objects, scales and dataset
bias”, in CVPR, 2016.
【22】
Keywords: Hybrid-CNN, ImageNet and PlaceNet
新規性・差分
概要
シーン認識の問題を扱う際に,ImageNetやPlaceNetのデータを
用いてデータセットのバイアスからなる特徴の偏りを解消する.
従来ではHybrid-CNN [23]によりこの問題に取り組んだが,
ImageNetの特徴はシーン認識をうまく向上させるための手がか
りとはなりえなかった.本論文ではImageNetのスケールを考慮
し,さらにはデータセットの偏りの問題を取り扱うことで効果
的にシーン認識の手がかりとして,Hybrid-CNNがうまくいくた
めの成功例となった.
・ImageNetとPlaceNetのHybrid-CNNに対してスケールや
データバイアスの考慮によりシーン認識の精度が向上
・SUN397に対して66.26%とstate-of-the-artな精度を実現
した.
Links
論文 http://www.cv-
foundation.org/openaccess/content_cvpr_2016/papers/Herran
z_Scene_Recognition_With_CVPR_2016_paper.pdf](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-24-320.jpg)
![Ziyu Zhang, Sanja Fidler, Raquel Urtasun, “Instance-Level Segmentation for Autonomous Driving with
Deep Densely Connected MRFs”, in CVPR, 2016.
【23】
Keywords: Semantic Segmentation, Autonomous Driving
新規性・差分
概要
自動運転の文脈で用いることができるセマンティックセグメンテーション
の手法を提供する.この問題に対して,Densely Connected Markov
Random Fieldを用いてアノテーション情報からのセマンティックセグメン
テーションを実行する.MRFは(1)に示す3つの項 -- Pairwise Smoothness
Term, Pairwise Local CNN Prediction Term, Pairwise Inter-connected
component Term から構成される.
・KITTI Datasetに対して[Zhang+, ICCV15]よりも高い精度
でセマンティックセグメンテーションを実現した.
・密な結合を持つMRFモデルの提案により,周辺領域に対
する分離性能を向上し,セマンティックセグメンテーショ
ンに貢献した.
Links
論文 http://arxiv.org/pdf/1512.06735v2.pdf
Slide
http://www.cs.toronto.edu/~urtasun/courses/CSC2541/08_inst
ance.pdf](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-25-320.jpg)


















![Jialin Wu, Gu Wang, Wukui Yang, Xiangyang Ji, “Action Recognition with Joint Attention on Multi-Level
Deep Features”, in BMVC, 2016.
【46】
Keywords: Action Recognition, CNN, RNN
新規性・差分
概要
CNNとRNN(LSTM)を用いて複数階層の特徴量にアクセス
することにより、行動認識の精度を向上させる.提案手法
の構造には複数の枝分かれしたMulti-branch modelが含ま
れる.この仕組みにより背景のノイズに頑健な認識ができ
ると主張した.C3Dの3D Convolution [Tran+, ICCV15]に
より作成されたCNNをLSTMに入力.
・畳み込みやLSTMの仕組み自体ではなく,そのアーキテ
クチャの構造により新しさを出した.
・State-of-the-artではないが,UCF101で90.6%,
HMDB51にて61.7%と良好な性能を出した.
Links
論文 http://arxiv.org/pdf/1607.02556v1.pdf
プロジェクト](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-48-320.jpg)
![Jordan M. Malof, Kyle Bradbury, Leslie M. Collins, Richard G. Newell, “Automatic Detection of Solar
Photovoltaic Arrays in High Resolution Aerial Imagery”, in arXiv pre-print 1607.06029, 2016.
【47】
Keywords: Drone, UAV, Solar Panel
新規性・差分
概要
航空画像からのソーラーパネルの検出.135km^2に渡る観
測を実行した.データは5,000x5,000[pixels]の画像600枚
により構成される.アノテーションされた2,700箇所のデ
ータにより学習と検出を行った.手法にはRandom
Forestsを用いて,後処理により精度を高めている.特徴
は注目点の周辺から画素を蓄積する.
・Pixel-wiseのセグメンテーションを実行.また,物体レ
ベルの認識も提供している.
Links
論文 https://arxiv.org/ftp/arxiv/papers/1607/1607.06029.pdf
プロジェクト](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-49-320.jpg)


![Nikolaus Mayer, Eddy Ilg, Philip Hausser, Philipp Fischer, Daniel Cremers, Alexey Dosovitskiy, Thomas
Brox, “A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow
Estimation”, in CVPR, 2016.
【50】
Keywords: Scene Flow, Optical Flow, Disparity, Stereo Matching
データセッ
ト
結果
概要
・CNNによるオプティカルフロー推定を,視差・シーンフ
ローの推定に拡張.
・CGによる3種のステレオ動画データセットを提供.シーン
フローの学習・評価を可能にする最初の大規模データセット.
・シーンフローのground truthとして重要なdisparity changeを計算.
・セグメンテーションラベルは物体レベルと材質レベルの2種を用意.
・視差推定はKITTI 2015 benchmarkにおいて,MC-CNN-acrt
[Zbontar+,arXiv2015]と比較し,精度で少し劣るが1000倍高速.リアルタ
イムの手法のMBM [Einecke+,IV2015]と比較し,誤差30%低減.
・個々のタスクを別々に解くより,SceneFlowNetで統合して解く方が高
精度.
Links
論文 http://www.cv-
foundation.org/openaccess/content_cvpr_2016/papers/Mayer_A_Large_Dataset_CVPR
_2016_paper.pdf
プロジェクト http://lmb.informatik.uni-freiburg.de/Publications/2016/MIFDB16/
新規性・差分
・先行研究のFlowNet [Dosovitskiy+,ICCV2015]では,椅子が空を
飛ぶデータセットであるFlying Chairs Datasetにより,オプティカ
ルフロー推定用CNNを学習.
・本論文では,Stanford ShapeNetの様々な物体が奥行きの変化も
含めて空を飛ぶFlyingThings3D dataset(他2種)により,シーン
フロー推定用CNNを学習.
(2)Monkaa
(Sintelを意識)
(3)Driving
(KITTIを意識)
(1)FlyingThings3
D
手法
・オプティカルフローを推定するFlowNet,視差を推定する
DispNetを学習.その後,2つを下図のように統合した
SceneFlowNetを学習.](https://image.slidesharecdn.com/201607deepsurvey2016-160803014730/85/2016-07-cvpaper-challenge2016-52-320.jpg)


cvpaper.challengeにて2016年7月にサーベイした論文のまとめです. Computer Visionの"今"をまとめています. cvpaper.challenge2016は産総研,東京電機大,筑波大学,東京大学,慶應義塾大学のメンバー約30名で構成されています. 2015年はCVPR2015の全602論文を読破し,PRMUにて論文調査からアイディア考案,論文化までをカバーする「DeepSurvey」を提案しました. 2016年は「1000本超の読破」と「コンピュータビジョンの上位会議への投稿」を目標に活動しております. Twitterで論文情報を随時アップしてます. Twitter: https://twitter.com/CVpaperChalleng 質問コメント等がありましたらメールまで. Mail : cvpaper.challenge@gmail.com











































![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Se...](https://cdn.slidesharecdn.com/ss_thumbnails/theneuro-symbolicconceptlearnerinterpretingsceneswordsandsentencesfromnaturalsupervision-190906012005-thumbnail.jpg?width=640&height=640&fit=bounds)




