Download as PDF, PPTX








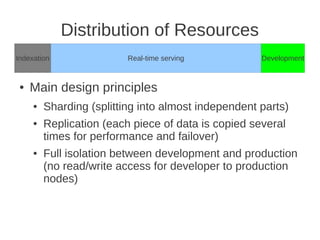




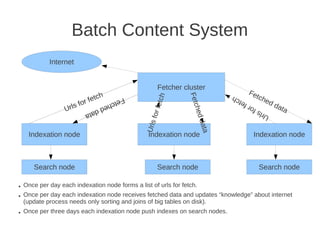
















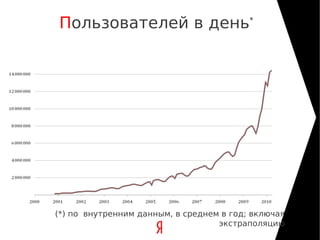
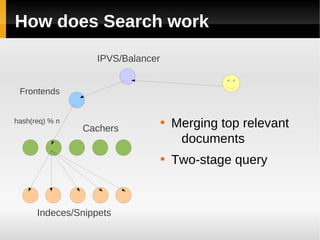





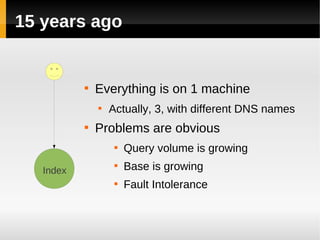

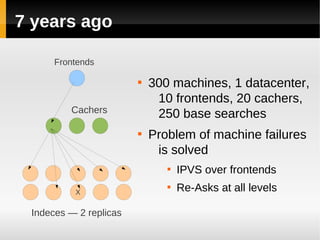
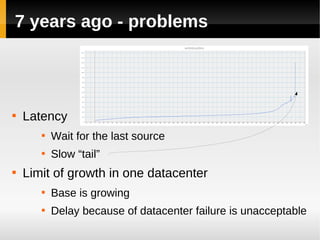
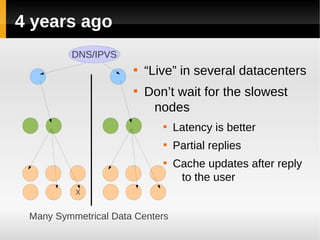

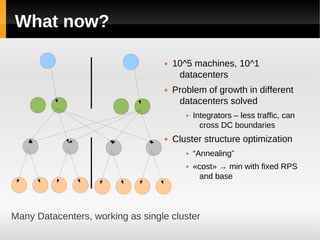









The document discusses the architecture of Yandex's search cluster. It describes how Yandex distributes resources across indexation nodes, search nodes, and development nodes. It also discusses challenges like ensuring high availability, distributing load efficiently, and enabling large-scale experiments across many servers.



















































































