Download to read offline














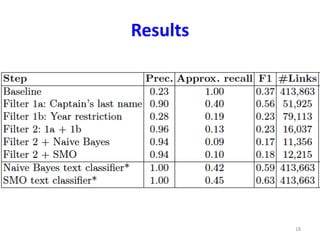






This study links ship records from muster rolls to newspaper articles by applying domain heuristics and text classification techniques. The researchers generated candidate links and then applied two types of filters: domain-specific filtering using heuristics like matching ship captain names and dates, and text classification to determine if articles were about ships. Combining the captain name heuristic with date restrictions produced very high precision links, though approximate recall was lower. The historian preferred these high precision links. The study aims to evaluate different techniques for linking historical datasets rather than introduce new methods.






















































































