Download to read offline







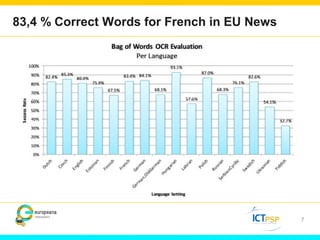

































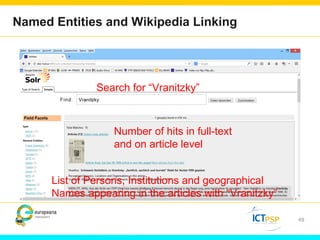
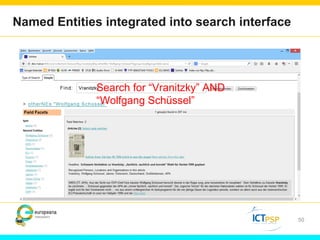
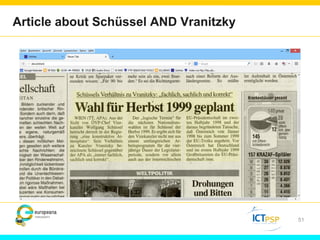
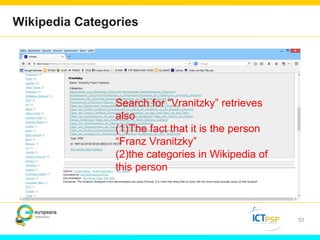
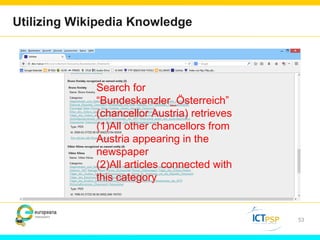



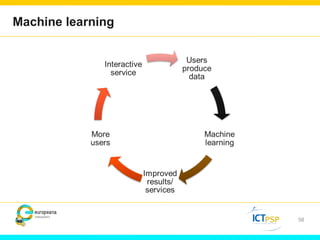

Optical Character Recognition (OCR) technology can help users in their research by digitizing printed texts and enabling full-text search. However, OCR quality varies and error rates can be as high as 10-40% depending on factors like language and publication date. This can negatively impact researchers seeking all occurrences of search terms. Crowd-sourcing corrections for searched words and utilizing external knowledge sources like Wikipedia could help improve search results and researchers' experiences. Machine learning applied to large digitized collections also has potential to extract additional useful information and insights not readily apparent from the text alone.










































































