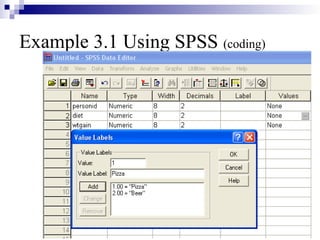
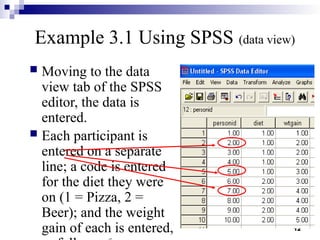
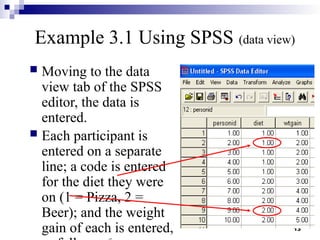
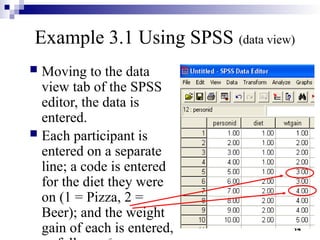
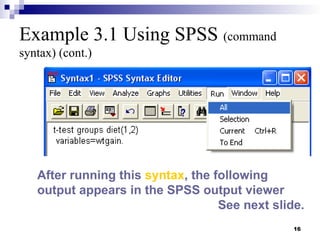
This document outlines the data analysis and interpretation phase of the business research process, focusing on the independent samples t-test, a statistical method used to compare differences between separate groups. It provides an example of how to conduct a t-test using SPSS to analyze weight gain differences between two diets, pizza and beer, demonstrating hypothesis formulation and data coding techniques. Additionally, it emphasizes the importance of checking for equal variances in the analysis and interpretation of results.



![4
When to use the independent samples t-test
Any differences between groups can be explored
with the independent t-test, as long as the tested
members of each group are reasonably
representative of the population. [1]
[1] There are some technical
requirements as well. Principally,
each variable must come from a
normal (or nearly normal) distribution.](https://image.slidesharecdn.com/12-240819171606-8effc4c9/85/12-Data-Analysis-Interpretation-pptx-4-320.jpg)