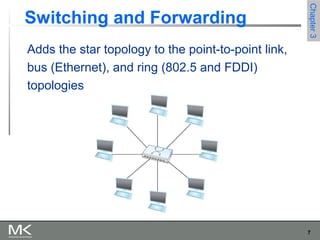
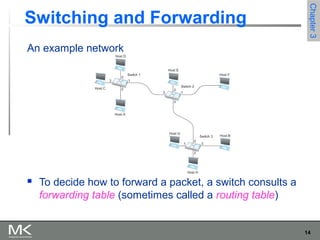
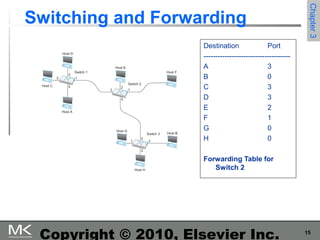
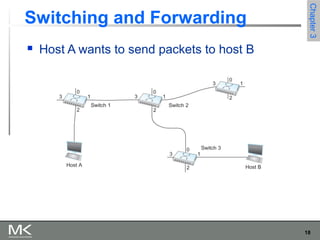
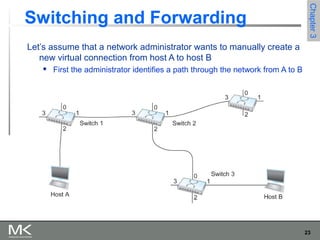
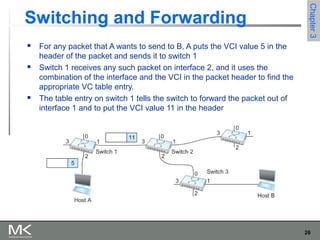
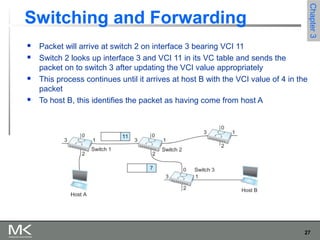
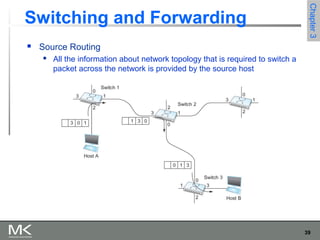
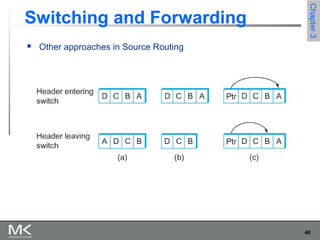
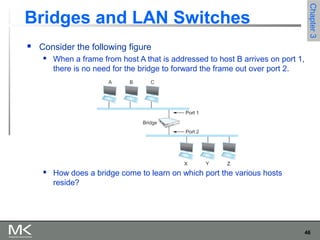
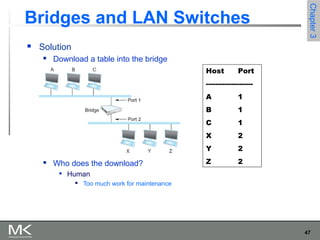
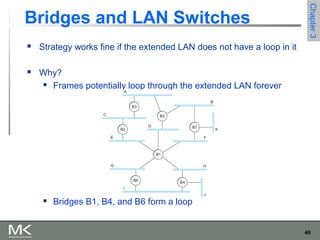
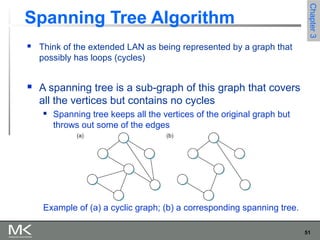
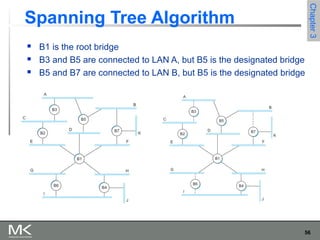
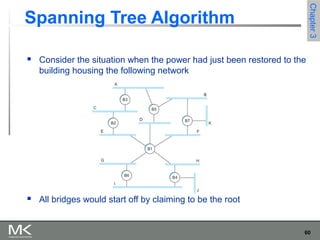
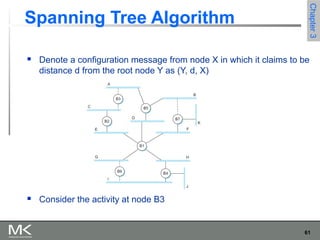
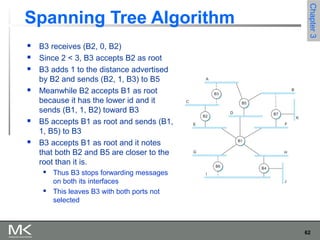
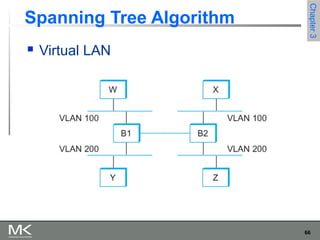
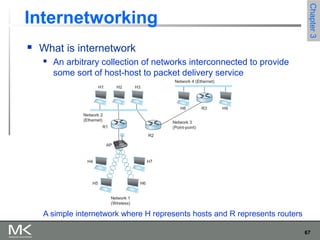
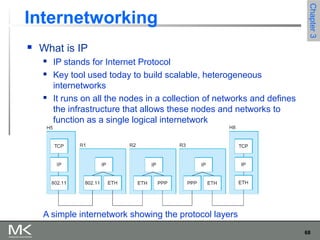
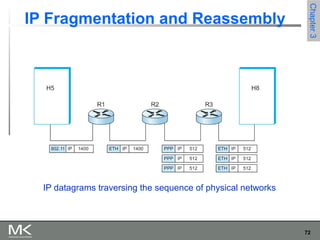
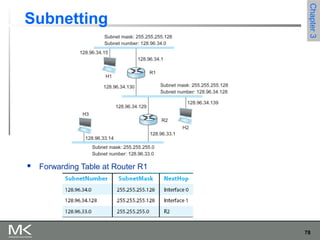
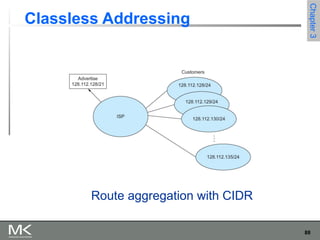
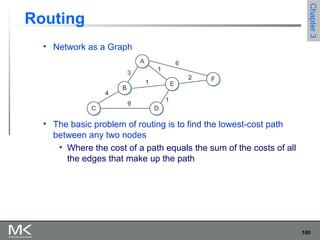
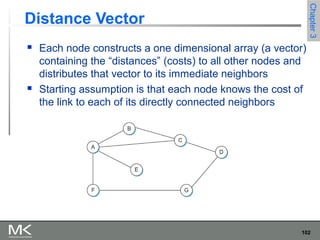
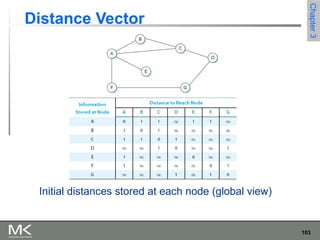
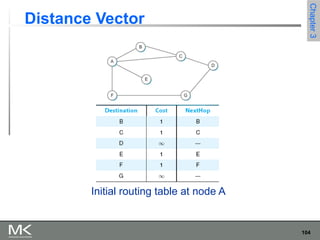
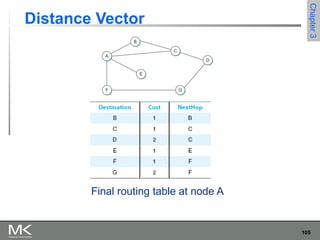
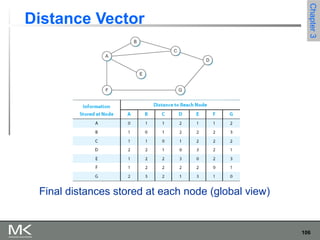
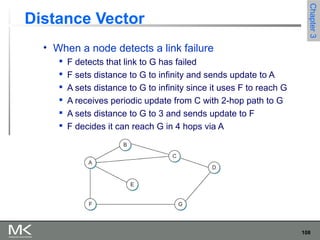
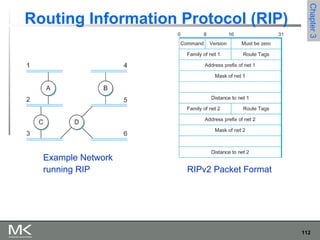
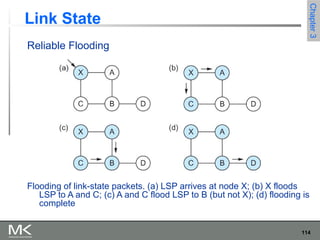
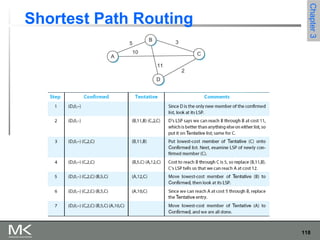
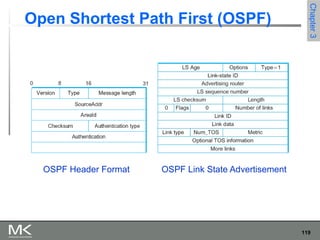
This chapter discusses different techniques for interconnecting networks, including switching, bridging, and routing. It covers store-and-forward switching using switches to connect networks. There are two main approaches for switching - connectionless switching using datagrams and connection-oriented switching using virtual circuits. Connectionless switching forwards each packet independently based on the destination address, while connection-oriented switching establishes paths through the network before transmitting data packets.