Downloaded 17 times















![implicit val env = Trickle.createEnv()
val checkoutTrackSource: DataStream[CheckoutTrack] =
CheckoutTrackMonorailSource()
val lineItemsSource: DataStream[LineItemRecord] = CDCSource[LineItemRecord](
topic = "core-line_items-v2", // ...
)
Typical Flink application](https://image.slidesharecdn.com/apacheflinkadoptionatshopify-220324210259/85/Apache-Flink-Adoption-at-Shopify-20-320.jpg)
![implicit val env = Trickle.createEnv()
val checkoutTrackSource: DataStream[CheckoutTrack] =
CheckoutTrackMonorailSource()
val lineItemsSource: DataStream[LineItemRecord] = CDCSource[LineItemRecord](
topic = "core-line_items-v2", // ...
)
val sink: SinkFunction[Result] = pipelineConfig.sinkType match {
case Print => new PrintSinkFunction()
case Bigtable => BigtableSink[Result](
table = "vendor_popularity", // ...
)
}
Typical Flink application](https://image.slidesharecdn.com/apacheflinkadoptionatshopify-220324210259/85/Apache-Flink-Adoption-at-Shopify-21-320.jpg)
![implicit val env = Trickle.createEnv()
val checkoutTrackSource: DataStream[CheckoutTrack] = CheckoutTrackMonorailSource()
val lineItemsSource: DataStream[LineItemRecord] = CDCSource[LineItemRecord](
topic = "core-line_items-v2", // ...
)
val sink: SinkFunction[Result] = pipelineConfig.sinkType match {
case Print => new PrintSinkFunction()
case Bigtable => BigtableSink[Result](
table = "vendor_popularity", // ...
)
}
val checkouts = processCheckoutTrackSource(checkoutTrackSource)
val lineItems = processLineItemsSource(lineItemsSource)
val results = aggregateJoinResults(
joinCheckoutsAndLineItems(checkouts, lineItems)
)
results.addSink(sink)
env.execute("Demo App")
Typical Flink application](https://image.slidesharecdn.com/apacheflinkadoptionatshopify-220324210259/85/Apache-Flink-Adoption-at-Shopify-22-320.jpg)
![implicit val env = Trickle.createEnv()
val checkoutTrackSource: DataStream[CheckoutTrack] = CheckoutTrackMonorailSource()
val lineItemsSource: DataStream[LineItemRecord] = CDCSource[LineItemRecord](
topic = "core-line_items-v2", // ...
)
val sink: SinkFunction[Result] = pipelineConfig.sinkType match {
case Print => new PrintSinkFunction()
case Bigtable => BigtableSink[Result](
table = "vendor_popularity", // ...
)
}
val checkouts = processCheckoutTrackSource(checkoutTrackSource)
val lineItems = processLineItemsSource(lineItemsSource)
val results = aggregateJoinResults(
joinCheckoutsAndLineItems(checkouts, lineItems)
)
results.addSink(sink)
env.execute("Demo App")
Typical Flink application](https://image.slidesharecdn.com/apacheflinkadoptionatshopify-220324210259/85/Apache-Flink-Adoption-at-Shopify-23-320.jpg)


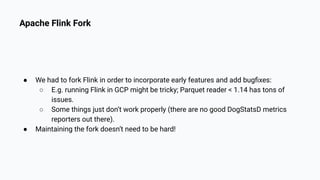
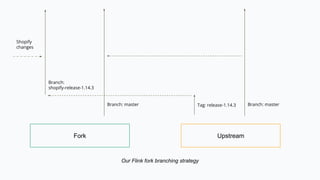
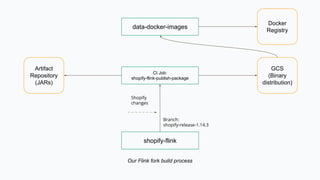








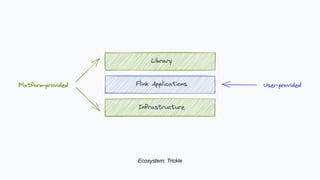
Yaroslav Tkachenko discusses Shopify's adoption of Apache Flink to simplify building and operating data applications for real-time data processing. The strategy involves developing an ecosystem of tools that evolves into a serverless platform, focusing on community engagement and production maturity. Key milestones include foundational components, observability, and enhancing technical support for adoption across multiple teams.





















































































