Download as PDF, PPTX




















![Array of Structure Versus Structure of
Arrays (AoS Vs. SoA)
On architectures where performance can be significantly
affected by memory access pattern, it may be useful to
consider whether AoS is better or SoA
struct {
float r, g, b;
} AoS[N];
struct {
float r[N];
float g[N];
float b[N];
} SoA;
7/13/17 23](https://image.slidesharecdn.com/pearc17v4-170714022847/85/PEARC17-Interactive-Code-Adaptation-Tool-for-Modernizing-Applications-for-Intel-Knights-Landing-Processors-23-320.jpg)



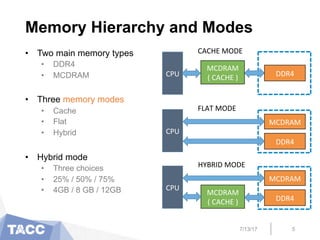
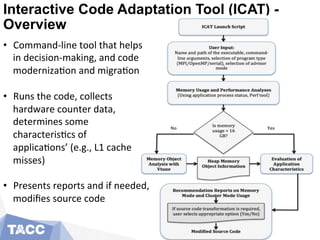
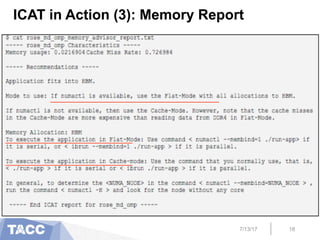
The document presents an interactive code adaptation tool (ICAT) designed to assist in modernizing applications for Intel's Knights Landing (KNL) processors, focusing on memory management and parallelization techniques using MPI and OpenMP. It discusses the evolving complexity of HPC architectures and the need for users to adapt their code to leverage multiple memory hierarchies effectively. The tool enables users to modify code interactively, apply optimizations, and improve performance by utilizing advanced memory features unique to KNL architecture.













































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)




![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)








