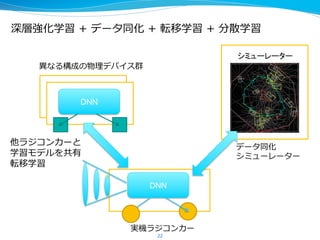
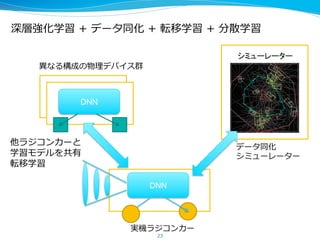
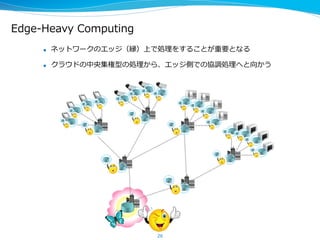
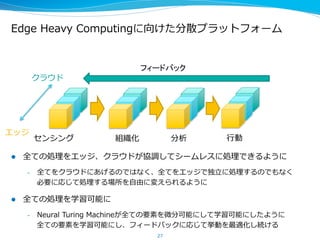
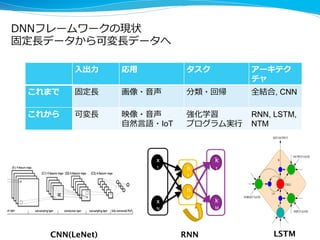
Interop2015 セミナーでの講演資料 デモリンク:https://www.youtube.com/watch?v=a3AWpeOjkzw RNN, VAE, 深層強化学習, PFNの取り組みについて



![ディープラーニングとは
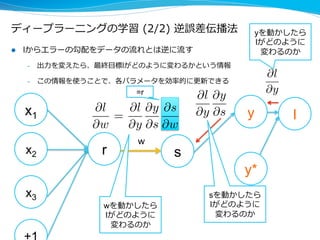
l 層が深く、幅も広いニューラルネットワークを利利⽤用した
機械学習⼿手法
l 2012年年の⼤大ブレーク以来、研究コミュニティのみならず
産業界に多く使われてきた
– 2014〜~2015年年中に出された関連論論⽂文数は1500を超える*
l 画像認識識、⾳音声認識識などで劇的な精度度向上を果たし、その
多くが既に実⽤用化されている
– Googleは47の⾃自社サービスで既に利利⽤用している
3
2014年の一般画像認識コンテストで優勝した
22層からなるのGoogLeNetの例 [Google 2014]
*http://memkite.com/deep-‐‑‒learning-‐‑‒bibliography/](https://image.slidesharecdn.com/interop2015okanohara-150612074211-lva1-app6892/85/IoT-3-320.jpg)

![RNNの⼀一般化
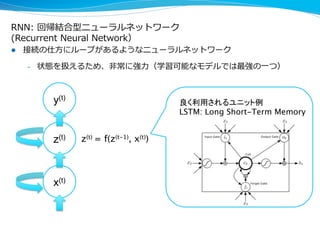
l 計算フローが全て、微分可能な要素で構成されていれば、RNNとみなせ
全ての要素を効率率率的に学習することが可能 c.f. 後退型⾃自動微分
l Neural Turing Machine [A. Graves+ 2014]
– メモリのアドレッシングも微分可能な要素で実現し、学習される
– コピーやソートなどのタスクを学習し、⼀一般化もできた
l Learning to Execute [W. Zaremba 2014]
– pythonプログラムの解釈と実⾏行行を学習させることができた
12
メモリアドレッシングの構成要素](https://image.slidesharecdn.com/interop2015okanohara-150612074211-lva1-app6892/85/IoT-12-320.jpg)
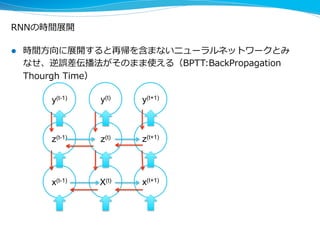
![RNNによる画像⽣生成: DRAW [K. Gregor+ 2015]
13
全体をかいてから、
下から上に書く
ように学習されて
いる
(PFNによる追試結果)
順に絵を書くようなニューラルネットを学習させる
時間方向のパレットの様子](https://image.slidesharecdn.com/interop2015okanohara-150612074211-lva1-app6892/85/IoT-13-320.jpg)


![VAEの利利⽤用例例(2)半教師有り学習
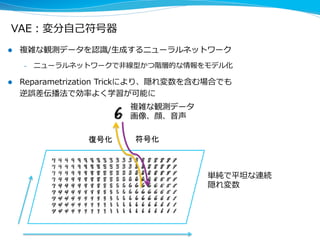
l 潜在変数の世界は、平坦で無相関な単純な表現になっているのでその上で
学習する場合は学習データは遥かに少なくてすむ
l 半教師有り学習
– 教師データと、(⼤大量量の)教師なしデータを組みあわせて学習
l VAEによる半教師あり学習は1/30の教師ありデータでも同程度度の精度度を達
成(現在の半教師有り学習の最⾼高精度度)
– ⼀一ラベルあり、教師あり 300サンプル vs 半教師あり 10サンプル
17
MNIST(⼿手書き⽂文字認識識タスク)のエラー率率率
他の半教師有り学習⼿手法 VAEを利利⽤用した半教師有り学習
[kingma+ 15]](https://image.slidesharecdn.com/interop2015okanohara-150612074211-lva1-app6892/85/IoT-17-320.jpg)

![深層強化学習
l 状態sと⾏行行動aをどのように表すのか?
– もし状態種類数に⽐比べ試⾏行行回数が⼤大きいならQ学習は有効
– 実際の問題では状態数は⾮非常に多い
u 例例えば、全ての⾞車車の位置関係をどのように求めるか?
l Deep Q-‐‑‒Learning Network [V. Minh+ 2015]
– ある状態である⾏行行動aをとった場合の期待将来報酬をDNNでモデル化
– (状態, ⾏行行動)のモデル化および、期待将来報酬のモデル化を同時に⾏行行う
l Atariのゲームでゲーム画⾯面を⼊入⼒力力、操作を⾏行行動、スコアを報酬とした時、単
⼀一の学習システムで約50のゲームで⼈人と同レベルの性能を達成
19](https://image.slidesharecdn.com/interop2015okanohara-150612074211-lva1-app6892/85/IoT-19-320.jpg)








![VAEの導出
l P(x|z) に⾮非線型モデルを利利⽤用した場合,p(z|x)を求めることは⼀一般に困難
l p(z|x)を近似する別の⾮非線型モデル q(z|x) を⽤用意する
l 尤度度の変分下限
38
あたかも、qで x→z と符号化
した後にpでz→xと復復号化
したようにみえる
log p✓(x) L(✓, ; x)
= DKL(q (z|x)||p✓(z)) + Eq (z|x) [log p✓(x|z)]
認識識モデルq(z|x)に対する
事前確率率率による正則化の効果
p(x|z)
復復号化
q(z|x)
≒ p(z|x)
符号化
z
x
p(x|z)とq(z|x)のどちらもニューラルネットワークで
表し、下限L(θ, φ; x)をθとφについて最⼤大化
Reparameterization Trick + 逆誤差伝播法で
効率率率的に学習可能](https://image.slidesharecdn.com/interop2015okanohara-150612074211-lva1-app6892/85/IoT-38-320.jpg)
![強化学習におけるQ学習
l 状態s, ⾏行行動aにおける将来の期待報酬 Q(s, a) を求めたい
l Bellman⽅方程式:最適なQ*では次が成り⽴立立つ
Q*(s, a) = Esʼ’ [r + γ maxaʼ’ Q*(sʼ’, aʼ’) | s, a]
– Q学習
– Q(s, a)のテーブルを初期化
– それぞれの状態 sについて
– ある⽅方策にもとづき⾏行行動 aを選ぶ
– ⾏行行動aをとり,報酬rと次の状態sʼ’を観測
– Q(s, a) := Q(s, a) + α [r + γ maxaʼ’ Q(sʼ’, aʼ’) – Q(s, a)]
– s = sʼ’
39
実際のQ値と今のQ値との差](https://image.slidesharecdn.com/interop2015okanohara-150612074211-lva1-app6892/85/IoT-39-320.jpg)






















![ドライブレコーダ映像からの3次元空間認識 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevmiyazawa-191031085336-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=640&height=640&fit=bounds)

![[基調講演] Deep Learning: IoT's Driving Engine](https://cdn.slidesharecdn.com/ss_thumbnails/dllabdaykeynotenishikawa-180704002744-thumbnail.jpg?width=640&height=640&fit=bounds)




































